کیودو (Kudu) به عنوان یک لایه ذخیره ساز جدید و جایگزین HDFS توسط شرکت کلودارا (Cloudera) بعد از سه سال تحقیق و توسعه ، به عنوان یک پروژه متن باز به بنیاد آپاچی پیشنهاد و توسط آپاچی به عنوان یک پروژه نوپا (در حال رشد – incubating) پذیرفته شده است .
همانطور که می دانید، HDFS به عنوان لایه اصلی ذخیره سازی داده ها در هدوپ، یک مکانیزم ترتیبی در خواندن اطلاعات دارد و بازیابی یک داده خاص در یک کلاستر از رایانه ها، عملی زمان بر است . برای رفع این مشکل، از HBASE به عنوان یک رهیافت جایگزین ذخیره سازی داده ها در هدوپ استفاده می کنیم که به ما اجازه دسترسی تصادفی و سریع به یک رکورد اطلاعاتی را می دهد. اما HBASE هم به عنوان یک بانک اطلاعاتی سطر گسترده توزیع شده، امکان پردازش دسته ای داده ها را با سرعت بالا فراهم نمی کند و معمولاً ترکیب این دو روش برای یک راه حل کامل تحلیل و بازیابی اطلاعات در سازمانها و شرکتها استفاده میشود.
کیودو در این بین، برای ایجاد یک راه حل میانه، ایجاد و توسعه داده شده است و روشی را برای ذخیره داده ها پیشنهاد می کند که هم به سرعت می تواند یک رکورد را در بین میلیون ها رکورد پیدا کند و هم پردازش دسته ای و گروهی داده ها را برای ما با سرعت و کارآیی بالا به ارمغان می آورد و از سرورهای امروزی که رم بالایی دارند هم حداکثر استفاده را انجام می دهد. (تا حد امکان پردازش ها را در حافظه انجام می دهد)
برای نیل به این هدف، کلوداِرا به جای بهبود HDFS یک سیستم ذخیره سازی جدید را از پایه طراحی کرده است که به طور مستقل می تواند مورد استفاده عملیات پردازش داده قرار گیرد. کیودو یک فضای ذخیره سازی با قابلیت دسترسی تصادفی به داده ها و رابطی شبیه به کاساندرا و HBASE و Google BigTable است یعنی برای ذخیره داده ها از مدل جدولی استفاده می کند و امکان توزیع داده ها را بین صدها رایانه در یک کلاستر به ما می دهد اما بر خلاف HBASE و Google Big Table به جای وابسته بودن به HDFS از سیستم فایل محلی هر رایانه استفاده می کند و بر خلاف کاساندرا، الگوریتم Raft consensus algorithm را برای تضمین یکپارچگی و جامعیت داده ها به کار می برد. الگوریتم فشرده سازی داده های آن هم با این رهیافتها، متفاوت است .
کیودو چگونه کار می کند ؟
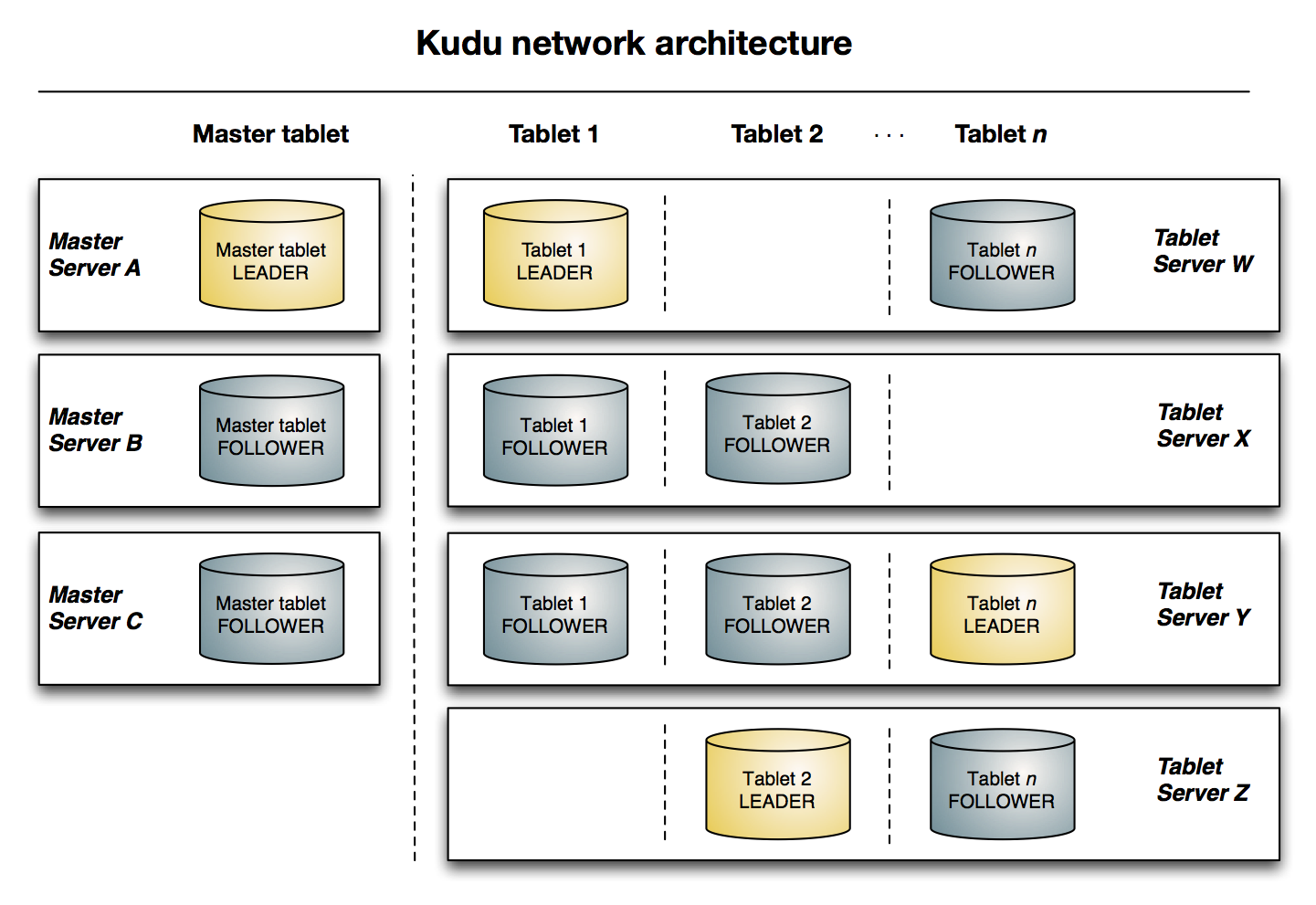
در کیودو ، داده ها به صورت جدولی با شِمای مشخص، ذخیره می شوند. هر جدول هم از تعدادی سطر تشکیل شده است که هر سطر یک کلید دستیابی منحصر بفرد دارد (این کلید می تواند ترکیب چند تا ستون یا فیلد باشد ) . ستون ها نوع داده های از پیش تعیین شده دارند . در هر جدول هم داده ها به زیر بخش هایی به اسم Tablet تقسیم می شوند که واحد توزیع و بازیابی داده ها هم همین Tablet ها هستند یعنی از هر Tablet دو یا چند نمونه در شبکه ذخیره می شود و این نمونه ها با هم، به روزرسانی می شوند (با الگوریتم Raft consensus algorithm ). این Tablet ها می توانند دارای ده ها گیگا بایت داده باشند و هر رایانه هم می تواند ده تا صد Tablet داشته باشد.
یک فرآیند و پروسه Master وظیفه هماهنگی بین هر رایانه یا Tablet Server را برعهده دارد و مباحث تحمل خطا هم در آن به خوبی لحاظ شده است و در صورت بروز مشکل، سرورهای Master پشتیبان این وظیفه هماهنگی را برعهده میگیرند.
کیودو چگونه داده ها را ذخیره می کند ؟
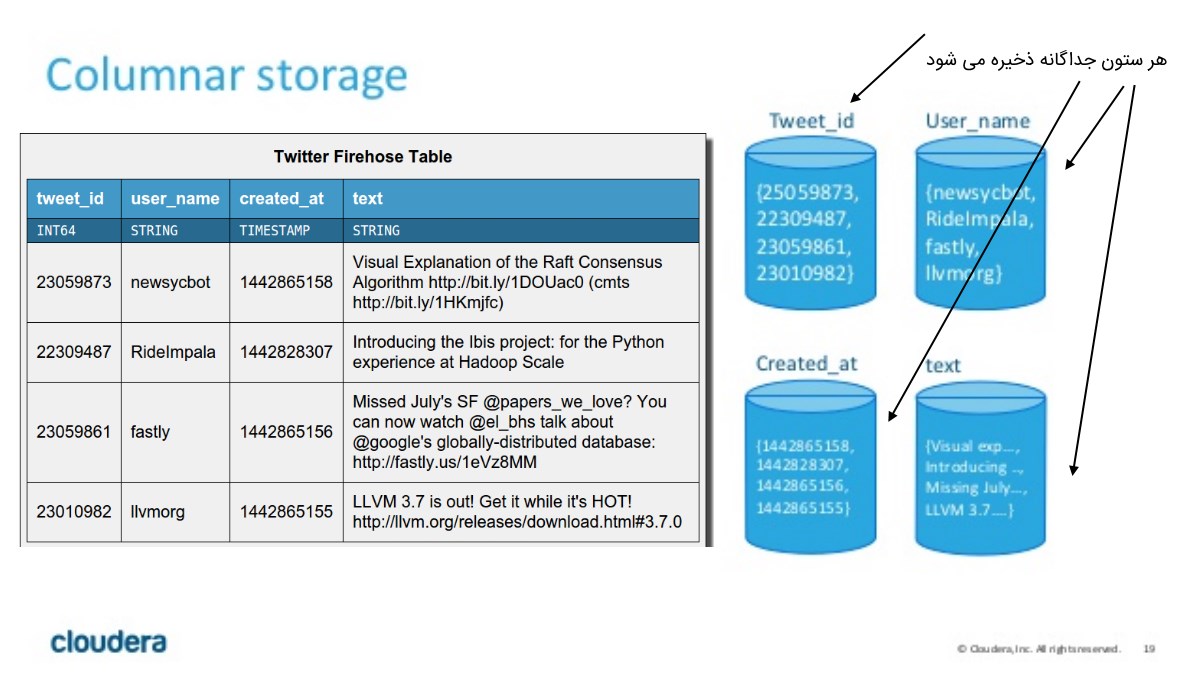
کیودو برای ذخیره داده ها در دیسک از روش ستونی Columnar استفاده می کند. (Parquet که یک روش ذخیره نوین و با کارآیی بالا در هدوپ است از همین مفهوم کمک میگیرد) در این روش، هر ستون یا فیلد، جداگانه ذخیره می شود که باعث می شود بتوان هر ستون را (مثلا ستون سن یا قد) را با توجه به نوع داده اش، به بهترین شکل ممکن فشرده سازی کرد و از طرفی وقتی براساس مقدار یک ستون جستجو انجام میدهیم با حداکثر سرعت می توانیم عملیات جستجو را مدیریت کنیم (کافیست داده ها را مرتب ذخیره کنیم و یا از HASH استفاده کنیم.)
برای به روز رسانی داده ها هم از روش log-structured merge-tree or LSM tree استفاده می کند که باعث می شود حداکثر استفاده از بافر و حافظه انجام شود و عملیات IO و دیسک هم به حداقل برسد.
کیودو در کجای پشته هدوپ قرار می گیرد ؟
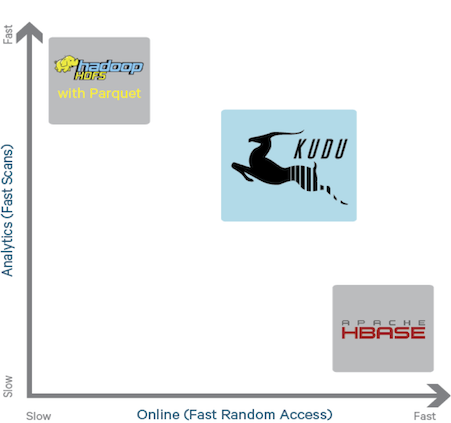
سوالی که بعد از خواندن مطلب فوق ممکن اس به ذهن شما برسد این است که کیودو دقیقا در کجای فناوریهای کلان داده قرار میگیرد ؟ شکل زیر می توان گویای این مطلب باشد .
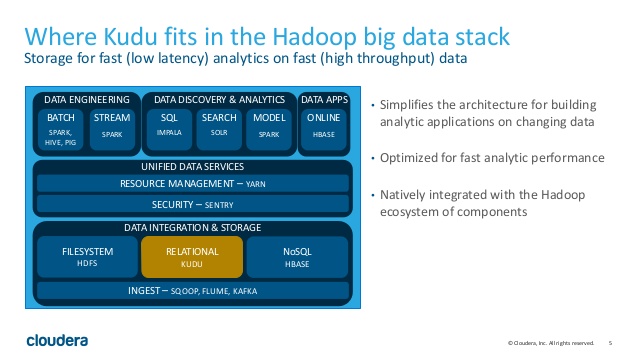 همانطور که مشاهده می کنید، کیودو به عنوان یک لایه ذخیره ساز در هدوپ عمل میکند و پردازشهای لایه های بالاتر مانند HIVE ، اسپارک و … می توانند مستقیماً از آن استفاده کنند.
همانطور که مشاهده می کنید، کیودو به عنوان یک لایه ذخیره ساز در هدوپ عمل میکند و پردازشهای لایه های بالاتر مانند HIVE ، اسپارک و … می توانند مستقیماً از آن استفاده کنند.
نمونه عملی کاربرد کیودو در صنعت
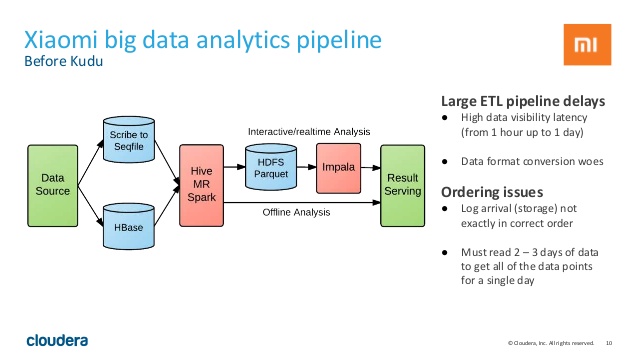
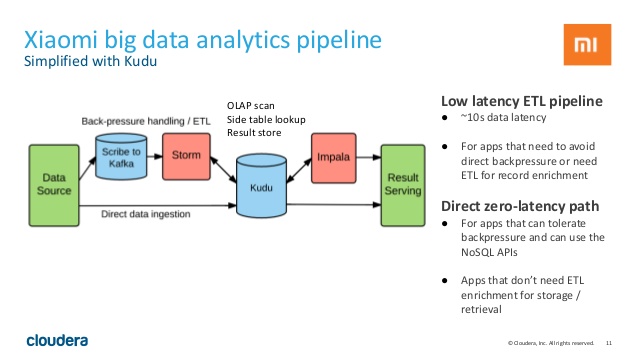
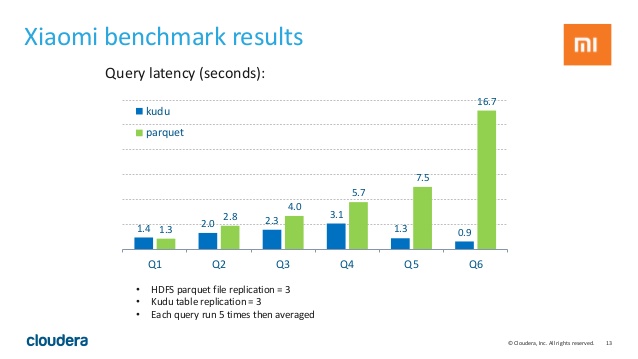
شرکت چینی شیائومی که یکی از برترین تولیدکنندگان لوازم دیجیتال همراه در چند سال اخیر در دنیا بوده است، برای پردازش حجم سنگین داده های روزانه خود، معماری اطلاعاتی سیستم ذخیره و بازیابی اطلاعات خود را به کیودو ارتقا داده است و نتایج بهبود عملکرد آنرا در شکلهای زیر می توانید مشاهده کنید :