
مقدمه ای بر پیکان (Apache Arrow) : تحلیل درون حافظه داده های ستونی
پروژه متن باز پیکان ، علیرغم نوپا بودنش در اکو سیستم آپاچی، در حال تبدیل شدن به یک استاندارد در حوزه پردازش داده و ایجاد یک بستر مناسب برای تعامل بین فناوریهای مختلف کلان داده است.
توسعه گران ارشد ۱۳ پروژه متن باز اصلی دنیای کلان داده، یک تیم مشترک برای ایجاد و توسعه پیکان ، شکل داده اند و سایر شرکتها و پروژه ها هم در حال تطبیق دادن خود با آن هستند. این ۱۳ تا پروژه عبارتند از :
تحلیل درون حافظه ای داده های ستونی
پروژه پیکان، برآمده از چهار گرایش و نیاز جدید مهندسی داده امروز دنیاست :
- داده های ستونی : قبلاً در مقاله Kudu درباره مفهوم داده های ستونی توضیح داده شد اما به طور خلاصه ،امروزه فناوریهای کلان داده، ستونی شده اند. یعنی به جای ذخیره سطری داده ها ، آنها را به صورت ستونی ذخیره می کنند. با اینکار ، فیلترگذاری و جستجوی داده ها بسیار سریعتر و بهینه تر صورت میگیرد. مثال زیر گویای این مطلب است.
 البته پروژه Apache Parquet که مخصوص این نوع از ذخیره سازی ، ابداع شده است به رشد این گرایش کمک بزرگی کرد.
البته پروژه Apache Parquet که مخصوص این نوع از ذخیره سازی ، ابداع شده است به رشد این گرایش کمک بزرگی کرد.
- پردازش درون حافظه ای : اسپارک محبوبیت و رواج امروز خود را مدیون پردازش های درون حافظه ایست که باعث افزایش کارآیی قابل ملاحظه سیستم های نوین اطلاعاتی امروزی شده است .
- داده های پیچیده و ساختارهای پویا : داده های دنیای واقعی با ساختار سلسله مراتبی و تودرتو راحت نمایش داده می شوند که رشد قالب JSON و بانکهای اطلاعاتی سندگرا مانند مانگو دی بی، نشانگر این نیاز کسب و کار امروزی است . سیستم های مدرن تحلیلی معاصر باید بتواند این نوع از داده ها را به صورت پیش فرض پشتیبانی کند.
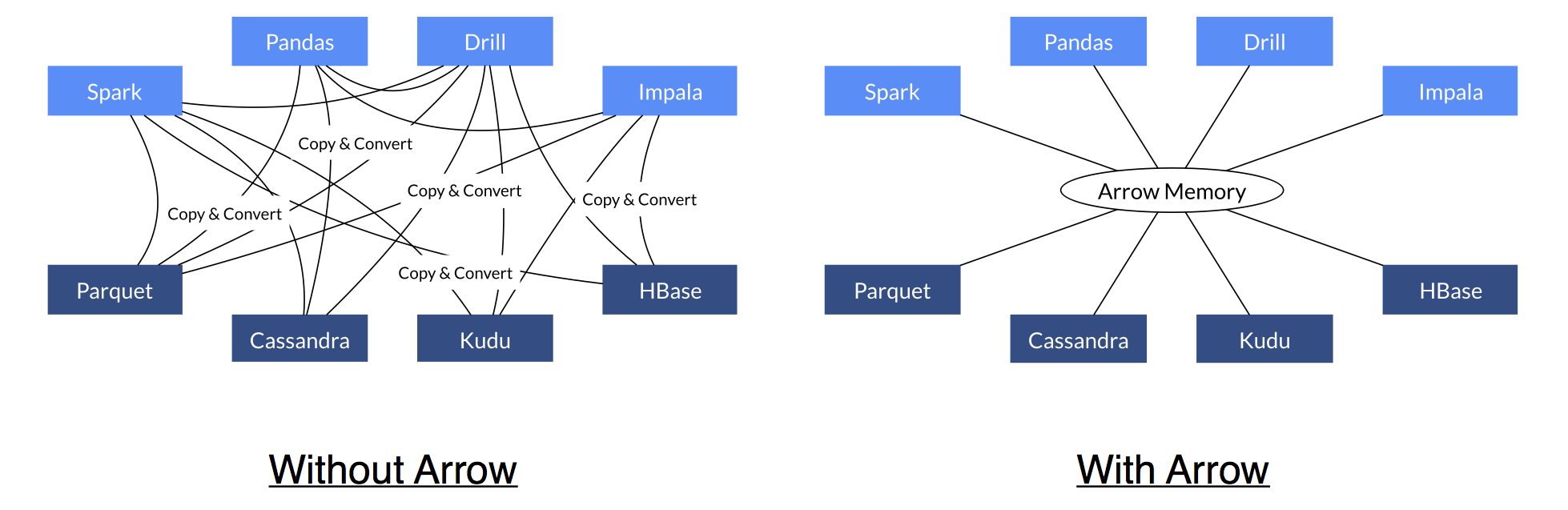
- نیاز به تعامل و برقراری ارتباط بین فناوریهای مختلف حوزه کلان داده : در حال حاضر، فناوریها و کتابخانه های مختلف حوزه کلان داده، هر کدام روشی را برای ذخیره و پردازش داده ها ابداع کرده اند و برای برقراری ارتباط بین آنها و استفاده از داده ها به صورت مشترک، نیاز به فرآیندهای مختلف تبدیل داده داریم که هم زمان بر است و هم توسعه سامانه ها را با مشکل مواجه می کند. Apache Parquet ، Apache Avro تلاشهایی برای رفع این مشکل و استاندارد سازی تبادل داده هاست .
اغلب سیستم های پردازش داده معاصر، یک یا حداکثر دو مورد از موارد سه گانه فوق را دارا هستندو پیکان ، تلاشی است برای ساخت سامانه هایی با پشتیبانی از تمام نیازهای نوین مورد اشاره به صورت استاندارد و متن باز.
مولفه های تشکیل دهنده پیکان
پیکان، مجموعه ای مولفه ها و فناوریهاییست که موتورهای اجرایی کلان داده (مانند اسپارک، توزیع و تجمیع) و کتابخانه های ذخیره ساز داده ها (مانند HDFS) از آنها به عنوان لایه های میانی خود استفاده خواهند کرد . این فناوریها و الگوریتم ها عبارتند از :
- مجموعه ای از نوع داده های استاندارد شامل نوع داده های SQL و JSON مانند Decimal,Int,BigInt
- ساختار داده ستونی برای نمایش درون حافظه رکوردهای اطلاعاتی که بر روی نوع داده های استاندارد بنا نهاده شده است.
- ساختمان داده های رایج مورد نیاز برای کار با داده های ستونی مانند صفها و جداول درهم سازی به صورت بهینه و موثر با سی پی یو های امروزی.
- IPC از طریق حافظه مشترک ، TCP/IP و RDMA
- کتابخانه هایی برای خواندن و نوشتن داده های ستونی به زبانهای مختلف
- الگوریتم های SIMD (یک دستور، چندین منبع داده) و مطابق با رهیافت خط تولید (PipeLine) برای عملیاتی مانند مرتب سازی ، جستجو ، تطبیق الگو و … که به صورت موثر از حافظه و سی پی یو استفاده کند .
- تکنیکهای فشرده سازی داده های ستونی برای بهینه سازی حافظه .
- ابزارهایی برای ذخیره موقت داده ها در حافظه های پایدار مانند HDD و SSD
البته نکته مهمی که باید مد نظر داشت این است که پیکان، به تنهایی نه یک موتور پردازش داده مانند اسپارک است و نه یک کتابخانه ذخیره و توزیع داده مانند HDFS بلکه طراحی شده است که به عنوان یک بستر مشترک و استاندارد برای موارد زیر به کار رود :
- موتورهای اجرای SQL مانند SparkSQL ، Drill و Impala
- سیستم های تحلیل و پردازش داده مانند Pandas و اسپارک
- سیستم های پردازش جریان و مدیریت صف مانند کافکا و استرم .
- سیستم های ذخیره ساز کلان داده مانند کاساندرا ، HBASE ، Kudu و Parquet
بنابراین پروژه پیکان ، در تقابل و رقابت با هیچ کدام از این سیستم های فوق نیست بلکه سرویس دهنده ای به آنهاست تا کارآیی و اشتراک داده به صورت استاندارد را برای آنها ممکن کند .
 یک مثال عملی
یک مثال عملی
برای آشنایی بیشتر با ماموریت پروژه پیکان، مثال زیر را در نظر بگیرید. اطلاعات تعدادی از کاربران به صورت زیر در قالب جی سان ذخیره شده است :
people = [
{
name: ‘mary’, age: 30,
places_lived: [
{city: ‘Akron’, state: ‘OH’},
{city: ‘Bath’, state: OH’}
]
},
{
name: ‘mark’, age: 33,
places_lived: [
{city: ‘Lodi’, state: ‘OH’},
{city: ‘Ada’, state: ‘OH’},
{city: ‘Akron’, state: ‘OH}
]
}
]
فقط شهرهای سکونت این افراد را در نظر میگیریم . با ذخیره آرایه ای این مقادیر در پیکان ، فضای ذخیره سازی پشت صحنه ما به صورت زیر خواهد بود :
![]()
با نگاه به ساختار فوق ، موارد زیر را می توانیم در رابطه با این داده ها نتیجه بگیریم :
- با توجه به سه آرایه فوق و جستجوی بهینه در آفست ها با مرتبه زمانی تقریباً ۱ می توان به جستجوی یک شهر خاص پرداخت.
- داده های شهرها به صورت پیوسته و در یک آرایه ذخیره شده است . بنابراین برای مقاصد تحلیل و پردازش بسیار بهینه و مفید خواهد بود .