

مقدمه و کاربرد
در ادامه سری آموزش الگوریتم های ضروری یادگیری ماشین، در این مقاله آموزشی به رگرسیون خطی می پردازیم. یکی از پرکاربردترین روشهای مدلسازی داده ها که پایه ریاضی بسیار ساده ای هم دارد، رگرسیون خطی است . هر گاه بتوانیم بین دو متغیر یک رابطه خطی را تشخیص دهیم، می توانیم از این نوع رگرسیون، برای پیش بینی مقادیر این متغیرها بر اساس مقدار متغیر دیگر استفاده کنیم . منظور از رابطه خطی هم این است که ببینیم با افزایش یک متغیر ، متغیر دیگر افزایش ( یا کاهش ) یافته و با کاهش آن هم متقابلاً متغیر دوم ، کاهش (یا افزایش) می یابد و این افزایش یا کاهش ، رابطه مستقیم (ضریبی ساده) با مقدار متغیر اول که آنرا متغیر مستقل می نامیم دارد. یک راه ساده برای کشف این رابطه هم این است که در یک نمودار، مقدار یک متغیر را بر اساس دومی رسم کنیم و اگر شکل حاصل ، شبیه به یک خط مستقیم بود، می توانیم نتیجه بگیریم که رابطه بین این دو متغیر یک رابطه خطی است . به این نمودار ، نمودار پراکنش هم می گویند.
قطعه کد زیر ، مقادیر قد و وزن بیست نفر را که از داده های واقعی به دست آمده است را در یک نمودار پراکنش به سادگی نشان می دهد :
که خروجی زیر را تولید می کند :
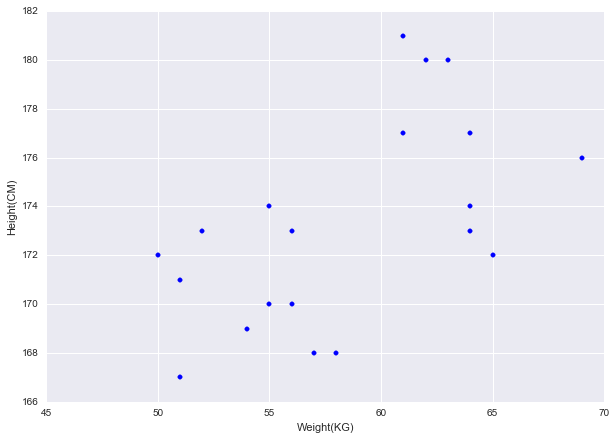
البته در نمودار فوق ، یک رابطه کاملاً خطی را مشاهده نمی کنیم اما به طور کلی، با افزایش وزن، قد هم افزایش یافته است و با کاهش قد، وزن کمتری را هم شاهد هستیم که نشان از رابطه ای خطی دارد. (در اکسل هم به راحتی می توانید با انتخاب دو ستون موردنظر ، نمودار پراکنش مربوطه را رسم کنید)
بعد از اینکه متوجه رابطه خطی بین دو متغیر شدیم ، کافیست فرمول رابطه خطی بین آنها را محاسبه کرده و از آن برای پیش بینی مقادیر جدید یک متغیر بر اساس مقدار متغیر دیگر استفاده کنیم .
احتمالاً از ریاضیات دبیرستان به یاد دارید که فرمول یک خط عبارتست از : Y= w1 *X + w0 که در آن w1 را شیب خط و w0 را عرض از مبدأ می نامیم. در این رابطه ، X متغیر مستقل و Y متغیر وابسته نامیده می شود هر چند به راحتی می توان X را هم بر حسب Y به دست آورد و جای متغیر وابسته و مستقل را به دلخواه عوض کرد.
اما چگونه این ضرایب را به دست آوریم ؟ با ما همراه باشید .
تاریخچه رگرسیون
رگرسیون به معنای بازگشت است . در سال ۱۸۷۷ فرانسیس گالتون (به انگلیسی: Francis Galton) در مقالهای که درباره بازگشت به میانگین منتشر کردهبود. اظهار داشت که متوسط قد پسران دارای پدران قدبلند، کمتر از قد پدرانشان میباشد. به نحو مشابه متوسط قد پسران دارای پدران کوتاهقد نیز، بیشتر از قد پدرانشان گزارش شدهاست. به این ترتیب گالتون پدیده بازگشت به طرف میانگین را در دادههایش مورد تأکید قرارداد. برای گالتون رگرسیون مفهومی زیستشناختی داشت، اما کارهای او توسط کارل پیرسون (به انگلیسی: Karl Pearson) برای مفاهیم آماری توسعه دادهشد. گرچه گالتون برای تأکید بر پدیده « بازگشت به سمت مقدار متوسط » از تحلیل رگرسیون استفاده کرد، اما به هر حال امروزه واژه تحلیل رگرسیون جهت اشاره به مطالعات مربوط به روابط بین متغیرها به کار بردهمیشود.
محاسبات ریاضی ضرایب معادله خطی
برای یافتن فرمول یک خط ، کافیست دو نقطه از آن را داشته باشیم اما در دنیای واقعی ما به جای دو نقطه، هزاران داده داریم که باید بهترین خط برازش شونده بر آنها را بیابیم. پس ابتدا نیاز داریم تعریفی برای “بهترین” پیدا کنیم و برآن اساس، ضرایب معادله خط را بیابیم .
برای مثال عملی این مقاله از مجموعه داده های فروش املاک مورد استفاده در درس یادگیری ماشین : رگرسیون سایت کورسرا ، بهره برده شده است .
می خواهیم رابطه ای بین مساحت یک خانه بر حسب فوت مربع و قیمت آن بر حسب دلار پیدا کنیم و می دانیم که رابطه ای خطی بین این دو برقرار است. (مجموعه داده ها از این آدرس قابل مشاهده و دانلود است). برای اینکار باید بهترین خطی که رابطه قیمت بر اساس مساحت خانه را نشان میدهد، بیابیم . فرض کنید که این خط را یافته ایم ، یعنی به ازای هر خانه با مساحت معلوم، قیمت حدودی آن با گذاشتن در این رابطه ،به دست می آید.
حال اگر داده های موجود (خانه های فروش رفته شده که به آنها داده های آموزشی هم می گوئیم) را در این رابطه قرار دهیم به ازای هر خانه ، یک قیمت فروش تخمینی حاصل می شود که با قیمت واقعی خانه، اختلافی خواهد داشت . هدف ما در رگرسیون خطی ، یافتن خطی است که کمترین اختلاف بین داده های موجود و داده های تخمین زده شده را داشته باشد .
بنابراین اگر تابعی داشته باشیم که اختلاف بین مقادیر واقعی و مقادیر تخمینی را نشان دهد مثلاً مجموع مربعات این اختلاف ها (اگر خود اختلاف ها را جمع بزنیم به دلیل اینکه اعداد مثبت و منفی خواهیم داشت، اثر یکدیگر را خنثی کرده و عددی نامعقول حاصل خواهد شد)، می توانیم دنبال روشی برای یافتن دو ضریب W0 و W1 که همان ضرایب خط هستند برای می نیمم کردن این تابع باشیم . به روش مجموع مربعات ، Residual Sum of Squares – RSS هم گفته میشود.

تابع RSS(W0,W1) یک تابع از درجه دو است و به ازای مقادیر مختلف W0 و W1 ، با داشتن x و y ها، خروجی های مختلفی تولید می کند که در شکل زیر به صورت سه بعدی این تغییرات را می بینید :
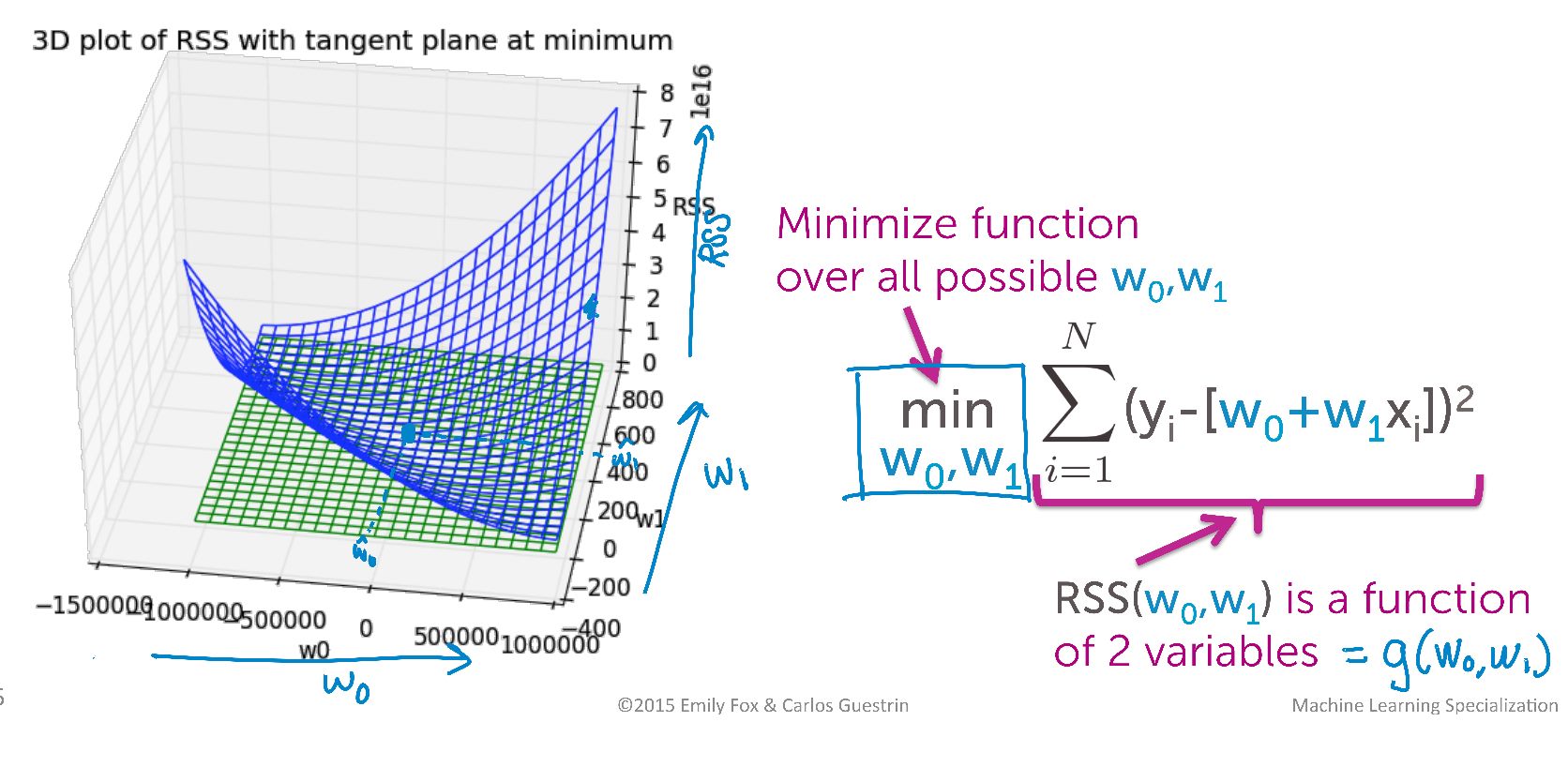
مباحث ریاضی می نمم کردن این تابع از حوصله این بحث خارج است اما با نگاه به شکل فوق ، می بینیم که اولاً این می نیمم سراسری وجود دارد و ثانیاً این می نیمم زمانی اتفاق می افتد که تغییرات RSS نسبت به W0 و W1 صفر باشد (برای تجسم این موضوع فرض کنید که روی منحنی آبی رنگ، به سمت پایین که می نیمم تابع است در حال حرکتیم . در نقطه پایین ، با تغییرات جزئی هر کدام از دو متغیر مساله، جابجایی ما در مقایسه با سایر نقاط بسیار ناچیز خواهد بود ) . بنابراین کافیست مشتق این تابع نسبت به هر دو متغیر گرفته شده و برابر صفر گذاشته شود (البته در دنیای واقع از روش کاهش گرادیان استفاده میشود). نتیجه عبارتست از :
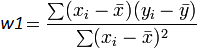
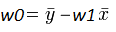
که در آن، N تعداد داده های موجود، x و y هم داده های مساله و ![]() هم میانگین متغیر مستقل ماست . اگر به فرمول فوق دقت کنید، W1 یا همان شیب خط، ضریب همبستگی بین دو متغیر x و y است و W0 هم تفاضل میانگین y و ضریب همبستگی ضرب در میانگین x است .
هم میانگین متغیر مستقل ماست . اگر به فرمول فوق دقت کنید، W1 یا همان شیب خط، ضریب همبستگی بین دو متغیر x و y است و W0 هم تفاضل میانگین y و ضریب همبستگی ضرب در میانگین x است .
تفسیر ضرایب رگرسیون خطی
در معادله یک خط ، شیب و عرض از مبدأ تفسیر مشخصی دارند اما در حوزه داده ها ، عرض از مبدأ ممکن است تفسیر پذیر نباشد . با نگاه به مثال فروش مسکن، اگر مساحت خانه صفر باشد ، y با عرض از مبدأ برابر خواهد شد . فرض کنید این عدد برابر ۴۰۰۰۰ دلار است . می توانیم اینگونه بیان کنیم که برای خرید خانه ، حداقل باید ۴۰۰۰۰ دلار پول داشت و بعد از آن بسته به متراژ خانه، این قیمت افزوده خواهد شد.
اما شیب خط یا W1 تفسیر واضحی دارد . w1 بیانگر میزان تغییری است در y به ازای یک واحد افزایش x . مثلاً در مثال فروش مسکن، اگر شیب خط برابر ۲۸۰ باشد به این معناست که به ازای افزایش یک فوت مربع به خانه، قیمت آن، ۲۸۰ دلار اضافه خواهد شد.
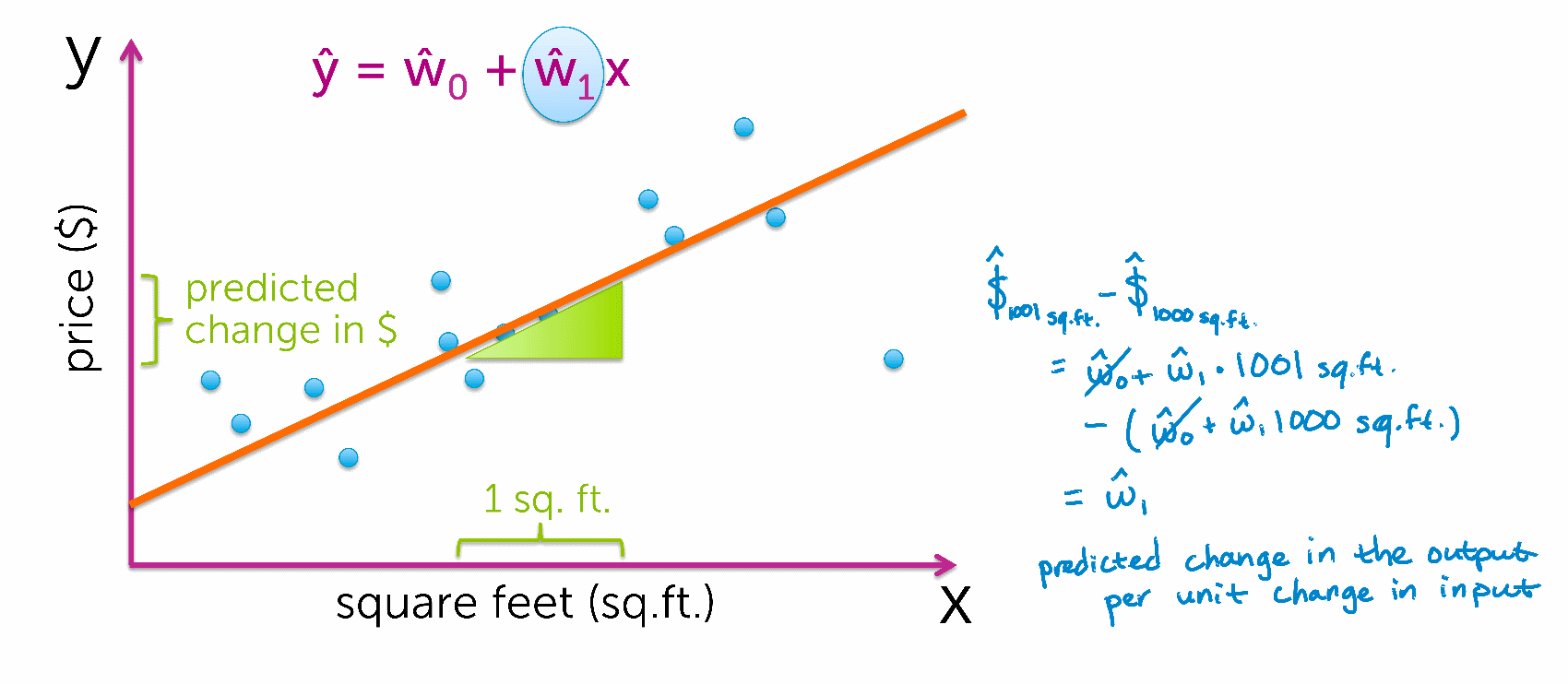
رگرسیون چندمتغیره
رگرسیون چند خطی تعمیمی از رگرسیون خطی است با در نظر گرفتن بیش از یک متغیر مستقل و یک مورد خاص مدلهای خطی عمومی تشکیل شده با محدود کردن تعداد متغیرهای وابسته به یک. مدل اساسی برای رگرسیون خطی عبارتست از
در رابطه بالا ما در نظر میگیریم که n مشاهده از یک متغیر وابسته و p متغیر مستقل موجودند. پس Yi، i اُمین مشاهده از متغیر وابسته است، Xij نیز i اُمین مشاهد از j اُمین متغیر مستقل است که j = ۱, ۲, …, p میباشد. مقادیر βj بیانگر متغیرهای تخمین زده شده و εi نیز i اُمین خطای معمولی مستقل توزیع یافته به طور یکسان است.
مثلا فرض کنید برای پیش بینی فشار خون یک شخص، ترکیب وزن و چربی خون را نیاز داریم . در اینجا از رگرسیون چند متغیره باید استفاده کنیم.
البته در رگرسیون چند متغیره دو فرض مهم باید وجود داشته باشند اول اینکه تعداد متغیرهای مستقل از تعداد مشاهده ها و داده های موجود بیشتر نباشد که البته معمولاً این شرط همیشه برقرار است و دوم اینکه بین خود متغیرهای مستقل، رابطه خطی معناداری وجود نداشته باشد . مثلاً اگر بین وزن و چربی خون ، رابطه خطی وجود داشته باشد، نمی توانیم ترکیب خطی این دو را برای پیش بینی فشار خون استفاده کنیم.
برای یافتن ضرایب این معادله ، از محاسبه گرادیان و روش کاهش گرادیان استفاده می کنیم. البته بررسی دقیقتر ابعاد این رگرسیون ، نیاز به دانش عمیق آماری و ریاضی دارد که علاقه مندان را به کتابهای آماری مرجع و خواندن محاسبه ضرایب همبستگی و رگرسیون توصیه می کنیم .

چهار فرض اصلی در استفاده از رگرسیون خطی
برای استفاده از این تکنیک ساده و کارآمد در پیش بینی مقادیر یک متغیر وابسته ، باید چهار شرط زیر حتماً برقرار باشد تا بتوانیم روی صحت مدل (رابطه کشف شده بین داده ها) پیشنهادی ، حساب باز کنیم.
- داده ها به صورت نرمال توزیع شده باشند . یعنی تا حد امکان داده های پرت نداشته باشیم و جامعه آماری ما نمونه ای درست از کل جامعه باشد مثلا برای بررسی قد بر اساس وزن ، تنها به داده های اندازه گیری شده دانشجویان دانشگاه بسنده نکنیم و تمام اقشار و تمام سنین را در تحلیل خود دخیل کنیم . از طرفی اگر داده های پرت زیادی داشته باشیم ، ابتدا آنها را حذف و مجموعه داده یکنواختی ایجاد کنیم .
- وجود رابطه خطی بین متغیرهای مستقل و متغیر وابسته . فرض اصلی ما در رگرسیون خطی، وجود یک رابطه خطی بین متغیرهاست که باید از وجود آن مطمئن باشیم و گرنه مدلسازی ما ، قابل اعتماد نخواهد بود. یک راه برای بررسی ریاضی این موضوع (غیر از رسم نمودار پراکنش و بررسی چشمی رابطه خطی)، رسم نمودار RSS یا همان توان دو تفاضل مقادیر تخمین زده شده با مقادیر واقعی بر اساس مقادیر متغیر وابسته است . این نمودار باید کاملاً یکنواخت باشد و خطی (نمودار سمت راست شکل زیر) . در غیر اینصورت ، وجود رابطه خطی بین متغیر وابسته و مستقل، تضمین نمی شود.
- متغیرها و داده ها با دقت مناسب جمع آوری شده باشند وگرنه مدل ایجاد شده ، با دنیای واقعی همخوانی نخواهد داشت .
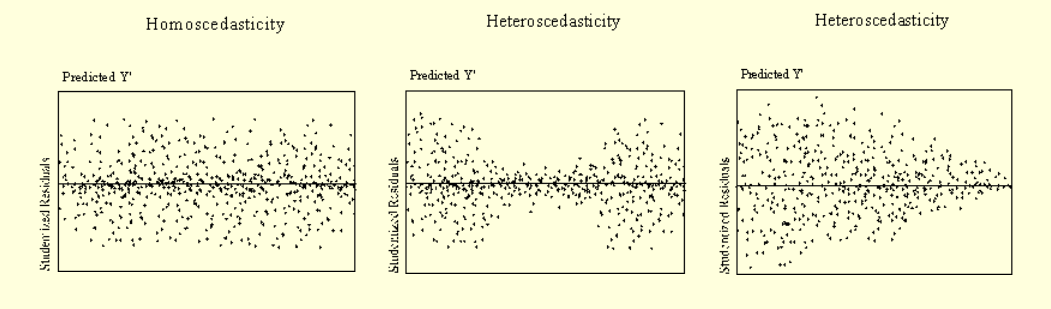
- همواریانسی (Homoscedasticity ) : واریانس خطا بین تمام مقادیر متغیر مستقل، باید به صورت نرمال توزیع شده باشد و شکل نمودار پراکنش آن ، این موضوع را نشان دهد.
نمونه کدهای پایتون
برای استفاده از رگرسیون خطی به صورت عملی ، از داده های فروش املاک استفاده خواهیم کرد. که می توانید از [download-attachment id="1646" title="kc_house_data"] هم آنها را دانلود کنید .
ابتدا داده ها را در یک دیتافریم پاندا بارگذاری می کنیم و به داده ها، نگاهی میاندازیم :
با استفاده از کتابخانه قدرتمند محاسبات عددی پایتون یعنی Numpy ، ضرایب رگرسیون را محاسبه می کنیم :
تابع polyfit متغیر مستقل و متغیر وابسته و نیز درجه چند جمله ای را که در اینجا یک است را از ما میگیرد و ضرایب معادله چندجمله ای خواسته شده را بر می گرداند که در اینجا عبارتست از :
که ۲۸۱ شیب خط و ۴۷۱۱۶ عرض از مبدأ ما خواهد بود.
حال ، قیمت بر اساس متراژ را رسم میکنیم و خط رگرسیونی هم که به دست آورده ایم را با رنگ دیگری در نمودار نشان میدهیم :
در کدهای بالا از کتابخانه Bokeh برای رسم نمودار استفاه کرده ام که نمودارهایی زیبا مبتنی بر کتابخانه D3.js و تعاملی ایجاد می کند و نیز امکان ایمپورت کردن از سایر کتابخانه های مثل seaborn و matplotlib را داراست .
خروجی کد فوق از قرار زیر است :
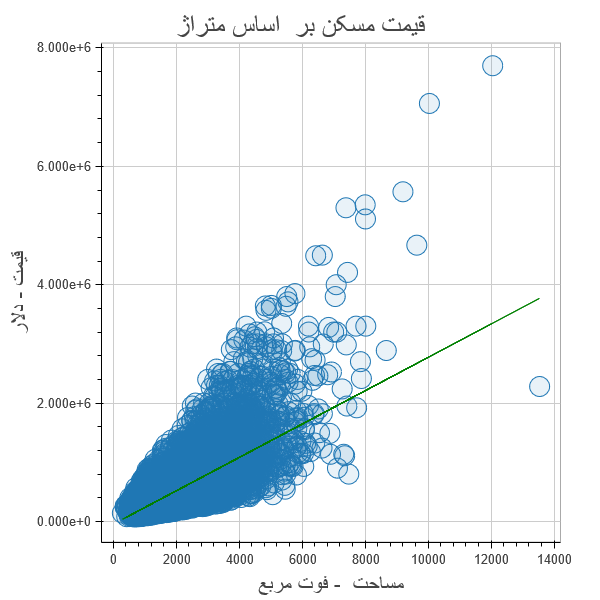
برای آشنایی با Bokeh به صورت مفید و مختصر می توانید از این آموزش استفاده کنید و برای آشنایی بیشتر با انواع نمودار و رسم آنها به مستندات آن مراجعه کنید . مقایسه ای از ابزارها و کتابخانه های مختلف بصری سازی پایتون با ذکر مثال ، در این آدرس آمده است .
تابع circle برای رسم دایره و تابع lineبرای رسم خط رگرسیون به کار رفته است . البته می توانیم به صورت ساده تر ، نمودار پراکنش این دو متغیر را به صورت زیر رسم کنیم :
البته با این روش امکان رسم خط روی نمودار وجود نخواهد داشت .
اگر بخواهیم از کتابخانه های رایج پایتون مانند matplotlibهم استفاده کنیم ، می توانیم با استفاده از Seaborn که کار با آنرا راحت تر کرده است ، قطعه کد زیر را بنویسیم :
خروجی این کد از قرار زیر خواهد بود :
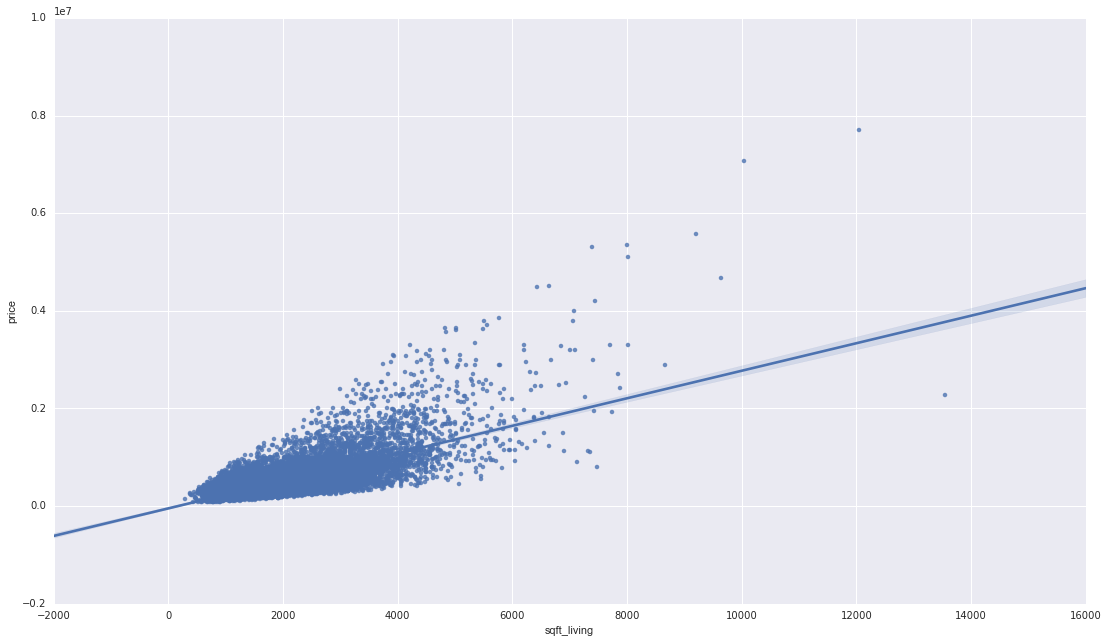
برای مشاهده امکانات مختلف و متنوعی که کتابخانه
Seabornبرای رسم نمودار های رگرسیون ارائه می کند، به این بخش از مستندات آن مراجعه کنید .
اگر بخواهیم ضرایب رگرسیون را خودمان محاسبه کنیم ، می توانیم از تابع زیر در پایتون استفاده کنیم که بر اساس فرمول های محاسه شده در بالا ، به محاسبه شیب خط و عرض از مبدأ می پردازد :
اگر بخواهیم حرفه ای تر عمل کنیم ، از کتابخانه SKLearn پایتون که کتابخانه اصلی یادگیری ماشین در این زبان محبوب علم داده است، کمک میگیریم و کد فوق را به صورت زیر می نویسیم :
در کد فوق ابتدا، داده ها را به دو دسته آموزشی و آزمایشی تقیسم می کنیم. ۵۰۰ تا داده آخر را که حدود بیست و پنج درصد داده های اصلی است را برای این منظور کنار می گذاریم . سپس با استفاده از کلاس LinearRegression و تابع fit آن ، ضرایب رگرسیون خطی را محاسبه می کنیم و در متغیر regr ذخیره می کنیم . با کمک تابع predict این متغیر ، مقادیر تخمین زده شده برای داده های تست را به دست آورده و با کسر آنها از مقادیر واقعی ، Residual sum of squares آنرا برای داده های تست به دست آورده ، پرینت می کنیم . نیز امتیاز واریانس محاسبه شده برای داده های تست را هم به دست می آوریم و در مرحله آخر هم داده های آزمایشی و خط رگرسیون متناظر را رسم میکنیم . خروجی کار را در شکل زیر می بینید :
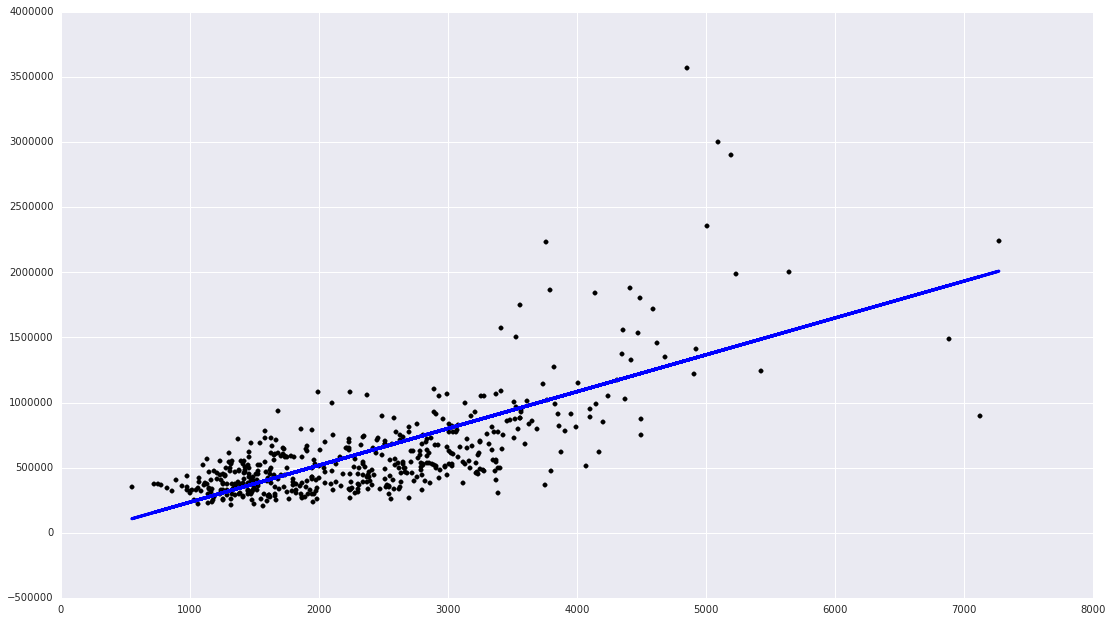
لازم به توضیح است که امتیاز محاسبه شده فوق بر اساس فرمول زیر محاسبه می شود :
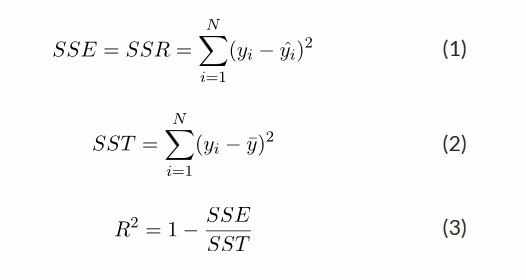
همانطور که مشاهده می کنید ، اگر اختلاف مقادیر موجود با مقادیر تخمین زده صفر باشد، که بهترین حالت ممکن است، این عدد به یک نزدیک است و اگر اختلاف معناداری وجود داشته باشد این عدد به سمت یک عدد منفی بزرگ ، میل می کند که در مثال ما، امتیاز خوبی به دست آورده ایم و می توانیم مدل را مناسب ارزیابی کنیم . برای آشنایی بیشتر با معیارهای ضروری ارزیابی مدل های یادگیری ماشین، به این مقاله حتماً مراجعه کنید .
نمونه کدهایR
برای تکمیل بحث ، کدهای لازم برای رگرسیون خطی با زبان R را هم با توجه به این آدرس، از قرار زیر خواهد بود :
سخن پایانی
هدف از این مقاله، آشنایی مقدماتی و عملی با مفهوم رگرسیون بخصوص رگرسیون خطی است و به تدریج سایر انواع رگرسیون و الگوریتمهای مورد نیاز برای پردازش داده ها، معرفی و آموز داده خواهد شد.
سلام خسته نباشید ممنون از سایت خوبتان اگه میشه بقیه الگوریتم های یادگیری ماشین رو هم بذارید لطفا تو پایتون پیاده سازی کنید مثل همین بخش.
انشالله از اسفندماه به صورت مداوم آموزشها به روز خواهند شد. مطالب فارسی مناسب هم ترجمه و هم جمع آوری شده است منتهی به دلیل مشغله فراوان، امکان نهایی کردن آنها تا الان مقدور نشده است. در هر صورت، بابت این تاخیر پیش آمده عذرخواهم.
با سلام
تابع خواندن از فایل csv در کتابخانه پایتون از pd.DataFrame.from_csv به pd.read_csv تغییر پیدا کرده است
تشکر از اینکه لطف کردید و تغییرات را اطلاع دادید . مطلب اصلاح شد.
با سلام
مقادیر خطای پیش بینی متغیری پیوسته توسط دو مدل رپیدماینر در زیذ آورده شده است. برای مقایسه این دو مقدار جهت تعیین مدل بهتر فقط مقادیر اصلی (۲۵۲۵۸۹٫۲۳ با ۷۸۵۸۹۹۹٫۲۳) مقایسه می شود یا اینکه مقادیر تلرانس خطای پیش بینی (۵۲۵۲۵٫۲۳ و ۲۵۸۲٫۲۳) هم تاثیر دارد؟
خطای پیش بینی مدل اول: ۵۲۵۲۵٫۲۳-/+۲۵۲۵۸۹٫۲۳
خطای پیش بینی مدل دوم: ۲۵۸۲٫۲۳-/+۷۸۵۸۹۹۹٫۲۳
بسیار ممنون