
در ادامه سلسله مباحث آموزشی پردازش زبان طبیعی و قبل از اینکه بخواهیم به صورت کامل به مباحث مرتبط با این موضوع به صورت عملی بپردازیم، نیازمند متون فارسی اولیه برای تحلیل های متنی هستیم.
با توجه به اینکه نوشته های رسمی روزنامه ها و سایتهای خبری، خیلی نیاز به پاکسازی و پیش پردازش ندارند، تصمیم گرفتیم به کمک توابع توسعه توئیتر، تعدادی توئیت فارسی را جمع آوری کرده و به صورت محدود، چند تحلیل کوچک روی آنها انجام دهیم تا در آموزش های بعدی، بتوانیم از این متون آماده استفاده کنیم.
بنابراین در این آموزش، به جمع آوری توئیت های فارسی به کمک کتابخانه tweepy و توابع جریانی توئیتر که امکان خواندن مداوم توئیت های تصادفی را به ما میدهد، خواهیم پرداخت.
پیش نیاز
قبل از شروع کار، پایتون نسخه ۳٫۶ را روی سیستم تان نصب کنید. ترجیحاً برای نصب پایتون، از توزیع آناکوندا استفاده کنید که اکثر کتابخانه های تحلیل متن و داده را دربردارد. نرم افزار پای چارم را هم برای اجرای کدهای پایتون، توصیه می کنم. کتابخانه tweepy را هم که در ادامه به آن نیاز خواهیم داشت، بعد از نصب آناکوندا یا پایتون، با مراجعه به خط فرمان به صورت زیر نصب کنید :
pip install tweepy
با توجه به فیلتر بودن سایت توئیتر برای انجام این تمرین از نرم افزارهایی مانند سایفون استفاده کنید و دقت کنیدکه گزینه Use VPN Mode را در تنظیمات این نرم افزار تیک بزنید تا تمام ترافیک ویندوز از جمله ترافیک مورد نیاز برای اتصال به توئیتر هنگام اجرای برنامه ها از طریق این نرم افزار صورت بگیرد.
کدهای پروژه انجام شده را از این آدرس می توانید دانلود کنید و پوشه بارگزاری شده را درون محیط توسعه پای چارم باز کرده، به اجرای فایلهای مختلف آن به صورت مرحله به مرحله بپردازید. در حال حاضر حدود ۷۰ هزار توئیت هم در این مخزن کد، موجود و قابل استفاده است.
ایجاد یک برنامه کاربردی در پایگاه توسعه دهندگان توئیتر
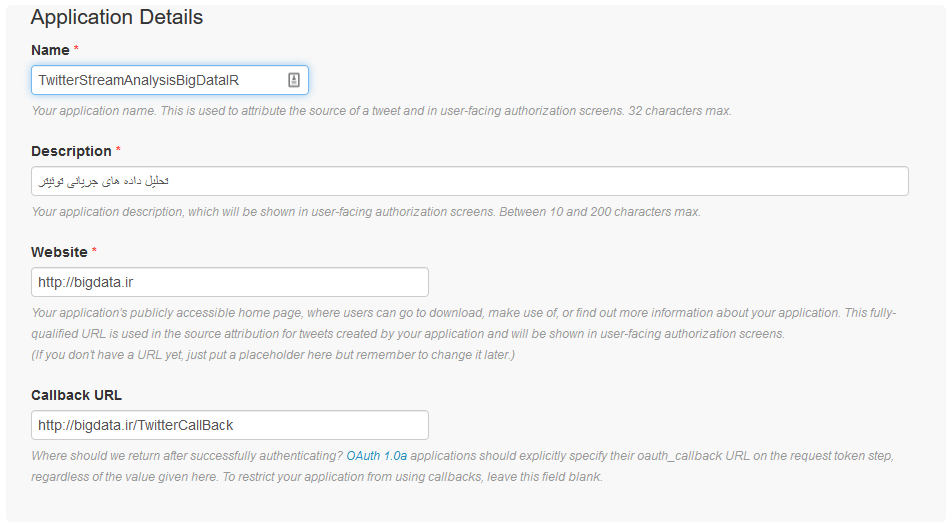
در گام اول باید یک حساب کاربری در توئیتر ایجاد کنیم. با مراجعه به آدرس https://apps.twitter.com و استفاده از دکمه Create New App، مشخصات برنامه ای که از طریق آن قصد تحلیل داده های توئیتر و خواندن توئیتها را داریم، وارد کرده، برنامه کاربردی خود را می سازیم.
شکل بعد، فرآیند ساخت یک برنامه کابردی در توئیتر را نشان میدهد. در این مرحله، چند نکته قابل ذکر است و باید رعایت شود:
- نام برنامه باید منحصر بفرد باشد
- توضیح برنامه حتماً وارد شود
- آدرس سایتی که قصد انتشار برنامه را داریم و توسط توئیتر هنگام مراجعه کاربران به برنامه ما نمایش داده خواهد شد هم تایپ شود
البته همانطور که در شکل مشخص است، برای استفاده شخصی از این برنامه (کاری که ما قصد انجام آنرا داریم )، یک آدرس جعلی هم کفایت میکند.
بعد از این مرحله، برنامه کاربردی ما ساخته شده و مشخصات آن نمایش داده خواهد شد. اگر به صفحه ابتدایی برگردیم، نام و توضیح این برنامه را میتوانیم مشاهده کنیم.
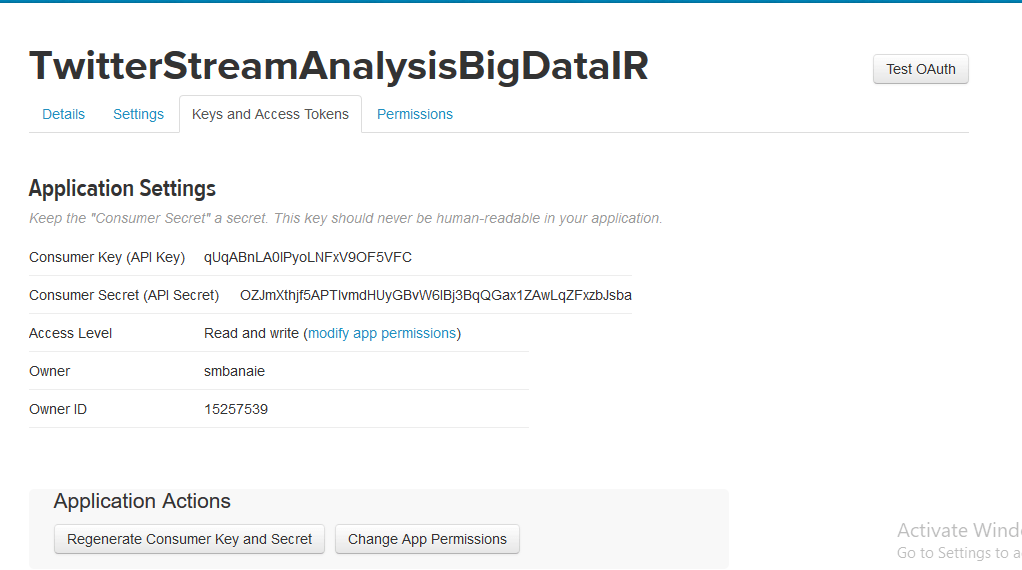
با کلیک بر روی نام برنامه، می توانید به مشخصات کامل آن دسترسی داشته باشید. API Key و API Secret که برای مراحل بعدی مورد نیاز است درون زبانه keys and access tokens قرار گرفته است.
گام صفر
در این گام، تنها به اجرای برنامه و مشاهده توئیت ها و اطلاعات مختلفی که هنگام دریافت یک توئیت به دست ما می رسد، می پردازیم. فایل twitter-step-0-Get-Your-Hands-Dirty.py را باز کرده، محتویات آنرا بررسی کنید.
در این فایل، کلاسی داریم با نام TweetListener که از کلاس StreamListener از ماژول tweepy ارث بری دارد . کلاس StreamListener برای خواندن جریانی توئیت ها (خواندن مداوم جریان داده های توئیتر) استفاده می شود و متد on_data آن، هنگام دریافت هر توئیت، به صورت خودکار فراخوانی می شود. بنابراین پردازش های خود را در این متد انجام می دهیم.
با دستور json.loads(data) رشته دریافت شده که اطلاعات یک توئیت است را به جی سان تبدیل نموده و برای تبدیل یک دیکشنری (جی سان) به رشته برای ذخیره در فایل، چاپ و مانند آن، از json.dumps(data) استفاده خواهیم کرد. برخی از اطلاعات json_data ( توئیت دریافت شده) را چاپ کرده ایم که مهم ترین این اطلاعات، متن توئیت یا json_data[“text”] است.
برای مشاهده تمام اطلاعاتی که راجع به یک توئیت از سمت توئیتر به ما ارسال می شود، با دستور print(data)، می توانید کل جی سان دریافتی را مشاهده و بررسی نمایید.
نکته : در نسخه های اولیه کتابخانه توئی پای، متن یک توئیت محدود به ۱۴۰ کاراکتر بود که همان استاندارد اولیه توئیتر را پوشش می داد. با گسترش میزان کاراکترهای یک توئیت توسط توئیتر، توابع جریانی توئیتر هم برای این منظور، به روز رسانی شدند و بالطبع، کتابخانه توئی پای هم این امکان را در کتابخانه خود، پیاده سازی کرد. اگر می خواهید یک توئیت را به صورت کامل و با اندازه ای بیش از ۱۴۰ کاراکتر دریافت کنید، هنگام ساخت یک متغیر از کلاس جریان توئیتر (کد انتهای فایل)، باید حالت دریافت را گسترش یافته (tweet_mode=’extended’) اعلام کنید. به صورت زیر :
و برای خواندن متن توئیت هم به جای json_data[“text”] از json_data[‘extended_tweet’][‘full_text’] استفاده کنید که در مرحله بعدی، این تغییرات در کد، اعمال شده است.
در انتهای فایل با دو دستور زیر :
ابتدا متغیری از نوع جریان های توئیتر ایجاد کرده، در مرحله بعد با تابع filter موجود در این متغیر، شروع به دریافت جریانی از توئیت های فارسی که در آنها کلمات با، از ، به ، در به کار رفته است، خواهیم کرد. یعنی به صورت لحظه ای و مداوم (تا زمانی که خطایی پیش نیاید یا ارتباط اینترنت ما قطع نشود)، بخشی از توئیت های فارسی که در آنها این کلمات به کار رفته است ( نه همه آنها)،را دریافت خواهیم کرد و با متد on_data به پردازش آنها خواهیم پرداخت.
نکته : اگر کل توئیت دریافتی را پرینت کنید یعنی دستور print(data) حروف فارسی به صورت کدشده (با علامت u انگلیسی که کد یونیکد هر حرف است) خواهید دید اما اگر هر بخش از اطلاعات را به صورت جداگانه پرینت کنید، آنها را فارسی خواهید دید.
گام اول
در این مرحله، هر توئیت دریافتی را در پوشه tweets ذخیره خواهیم کرد. برای اینکه مدیریت این فایلها راحت تر باشد، آنها را در پوشه ای به تاریخ روز دریافت شدن توئیت با پسوند txt ذخیره می کنیم.
فایل twitter-step-1-Get-Tweets.py را اجرا کنید تا این فایلهای متنی ساخته شوند. در این فایل، تنها شناسه هر توئیت و متن آنرا در یک خط ذخیره می کنیم. بین شناسه و متن توئیت، یک تب (t\) قرار می دهیم و با دستور tweet.replace(‘\n’, ‘ ‘) مطمئن می شویم که توئیت دریافتی شامل کاراکتر خط جدید نباشد ( که باعث شود متن آن، در چند خط چاپ و ذخیره شود و کار پردازش، در مراحل بعدی به مشکل بربخورد)
توضیح اینکه دستور codecs.open فایل مربوط به ذخیره توئیت ها را به صورت یونیکد باز کرده (و اگر موجود نباشد، آنرا ایجاد می کند) و به کمک فایل باز شده، متن توئیت را در آن ذخیره می کنیم.
گام دوم
در این مرحله، به حذف علائم نگارشی ، آدرسهای ایمیل ، آدرسهای اشخاص و مانند آن می پردازیم و خروجی این مرحله را در پوشه step1 درون پوشه output ذخیره خواهیم کرد. فایل twitter-step-2-Remove-Special_Chars.py را برای این مرحله در نظر گرفته ایم. با دستورات :
تمام فایلهای موجود در تمام پوشه های قرار گرفته در آدرس tweets که پسوند txt داشته را باز کرده و خط به خط به پردازش آنها می پردازیم.
برای حذف یک الگوی خاص، از کتابخانه معروف re در پایتون (رجوع به این آدرس)،که مخفف عبارات با قاعده است استفاده کرده ایم. در کد زیر :
ابتدا الگو را مشخص می کنیم: تمام کلماتی که با @ شروع شوند و بعد از آنها یکی از حروف الفبا یا اعداد یا آندرلاین (علامت [] به معنای یک کاراکتر است و تمامی کاراکترهای موجود در آن با هم OR می شوند یعنی یکی از بین آنها یکی هم بعد از @ به کار رفته باشد، الگوی ما به دست آمده است) به تعداد یک یا بیشتر (علامت +) به کار رود را با رشته خالی درون متغیر tweet جایگزین کرده ایم و نتیجه را هم در همین متغیر ذخیره نموده ایم.
گام سوم
در این مرحله، با حذف کاراکتر های خاص از توئیت ها، آماده پردازش آنها شده ایم. توصیه می کنیم که به جای اجرای فایل twitter-step-3-SomeAnalysis.py، سرور کتابچه های ژوپیتر را باز کرده (طبق راهنمای این آدرس)، و فایل Twitter-Analysis.ipynb را در آن آپلود و اجرا کنید. خوبی کتابچه های پایتون این است که برای اجرای هر تحلیل بر روی داده ها، نیاز به اجرای کدها از ابتدا ندارید. کافیست یک سلول جدید به کتابچه اضافه کرده، تحلیل و کد مورد نظر خود را وارد کرده، با زدن ctrl+enter آنرا اجرا نمایید و همانجا نتیجه را مشاهده کنید.
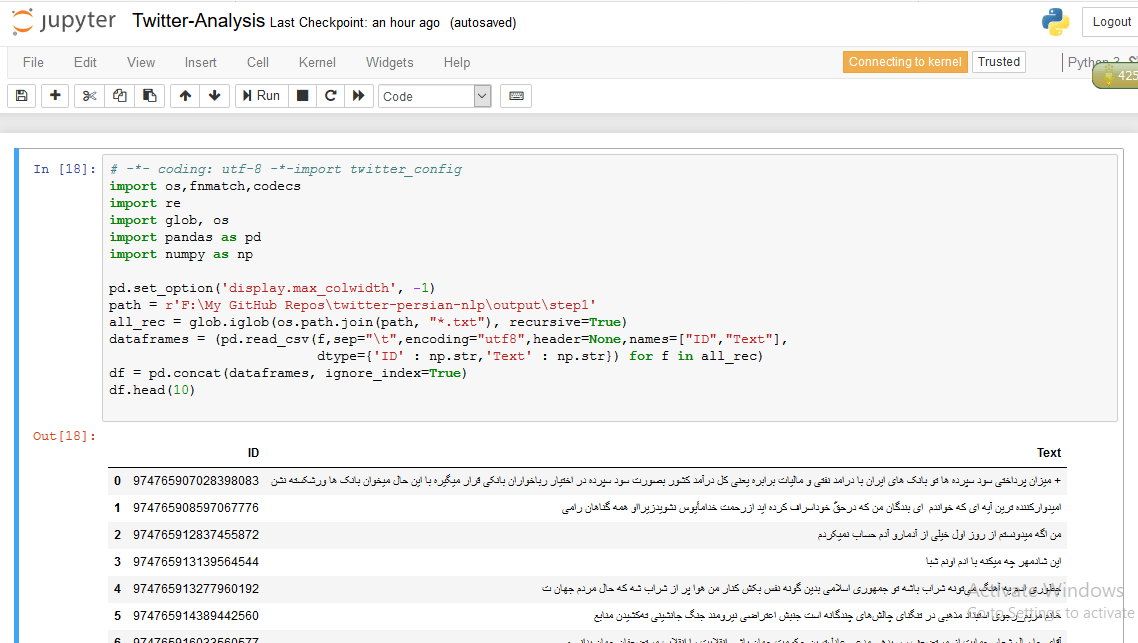
در این مرحله از کتابخانه معروف پاندا برای خواندن توئیت ها و بارگذاری آنها درون یک DataFrame استفاده کرده ایم. با دستورات زیر تمامی توئیت ها را درون متغیر df که دو ستون ID و Text دارد، بار گذاری می شوند :
نمونه ای از خروجی این مرحله را در زیر می توانید مشاهده کنید :
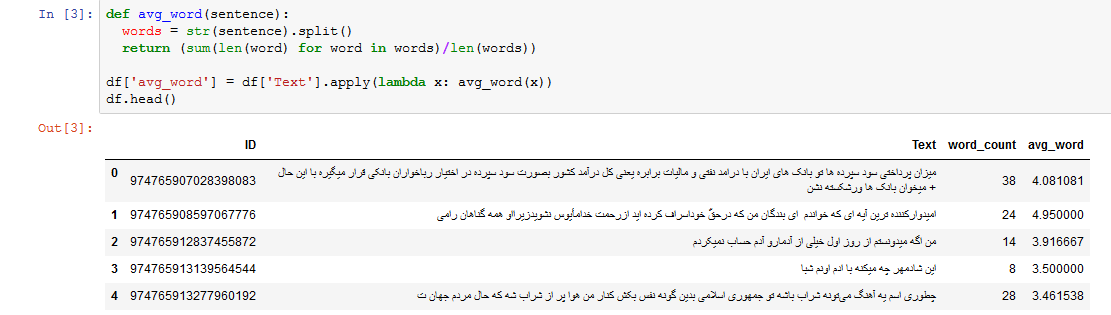
یکی از مهم ترین مزایای دیتافریم ها در پاندا، امکان ایجاد یک ستون جدید به سادگی ذکر نام ستون و ذخیره مقدار ثابت یا نتیجه اجرای یک تابع بر روی یک ستون دیگر است. یکی دیگر از مزایای دیتافریم، امکان استفاده از توابع لامبدا یا توابع ناشناس در آن است که به ما امکان پردازش سریع تک تک توئیت ها را می دهد.
مثلا در کد زیر، یک تابع یافتن میانگین طول کلمات یک توئیت تعریف کرده ایم و با استفاده از تابع apply که یک تابع از کاربر دریافت کرده و آنرا بر روی تک تک مقادیر یک ستون اجرا می کند، آنرا بر روی ستون Text اعمال کرده، خروجی آنرا به عنوان یک ستون، به دیتافریم خود اضافه کرده ایم :
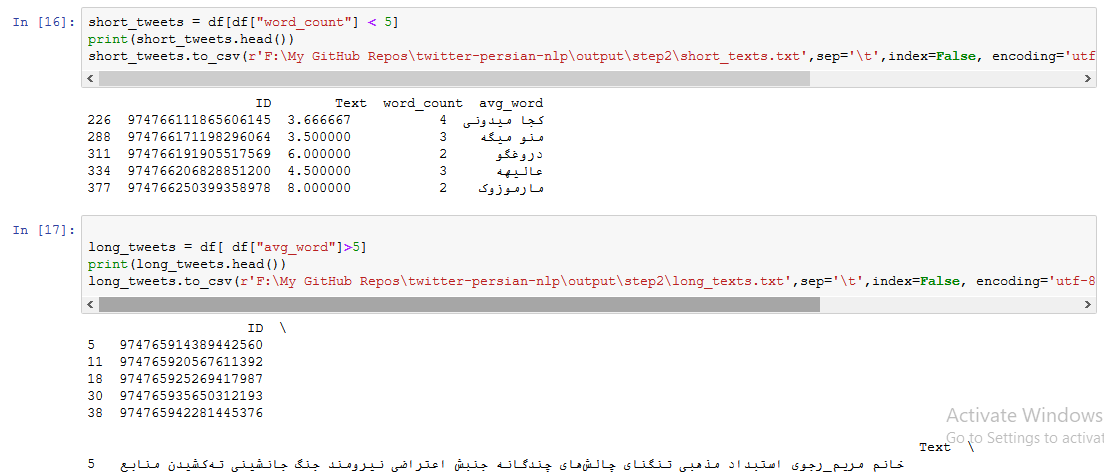
اعمال فیلتر و شرط بر روی یک ستون هم بسیار ساده است. در کدهای زیر توئیت هایی با تعداد کلمات زیر ۵ و نیز توئیت هایی با میانگین طول کلمات بالای ۵ را یافته، آنها در دو فایل مختلف ذخیره کرده ایم :
بعد از انجام تمامی پردازش ها، می توانیم مشابه فوق، کل دیتافریم را درون یک فایل متنی، برای پردازش های بعدی ، ذخیره کنیم.
سخن آخر
در این آموزش، به جمع آوری و پردازش اولیه توئیت های فارسی و ذخیره آنها درون چندین فایل متنی پرداختیم . امیدواریم این آموزش ساده، راهنما و شروعی برای علاقه مندان این حوزه باشد.
با اجرای هر کدام از این فایلها، به صورت خودکار تمامی فایلهای مورد بحث در این آموزش تولید خواهند شد (پوشه ها را البته به صورت دستی ایجاد کنید که خطایی هنگام اجرای کدها مشاهده نکنید )
کار بسیار با ارزشی کردید.
سلام
آخرین ورژن آنانوندا را نصب کردم
ولی دستور pip install tweepy کار نمیکنه
ارور invalid syntax میده
اگر آناکوندا را نصب کرده این میتونید یا در خط فرمان تایپ کنید :
conda install tweety
یا به کمک لانچر گرافیکی اناکوندا که توی منوی استارت ویندوز قرار میگیره، این کتابخانه را سرچ و نصب کنید
موفق باشید
من به دنبال مدلسازی یک چت بات هستم، آیا امکان استخراج مکالمات از توییتر هست؟
مهندسی داده :
این امکان به کمک API توئیتر وجود دارد.
سلام
میشه لطفا روند ساخت برنامه کاربردی در توئیتر را بیشتر توضیح بدید.
از این راهنما استفاده کنید.
وقتی روی create an app کلیک میکنم گزینه apply میاد. روی این گزینه کلیک میکنم یک شماره می خواد تا کد تایید رو برام بفرستند. شماره رو وارد میکنم اما کد تایید ارسال نمیشه. حالا باید چکار کنم؟
مثل اینکه اخیرا توئیتر سیاستهای امنیتی خود را تغییر داده است و برای ایجاد یک اپ کاربردی باید یک حساب کاربری مخصوص برنامه نویسان و توسعه گران ایجاد کنید که برای آن هم باید توضیحات کامل راجع به اپی که قرار است تولید کنید، بنویسید. بعد از این مرحله منطقا و بعد از بررسی های توئیتر باید فعال شود . اگر بقیه دوستان تجربه ای دارند خوشحال می شوم با ما در میان بگذارند.
ببخشید راه حلی برای R دارید؟ مشگل پورت ۴۴۳ هست که سایفون پشتیبانیش نمیکنه.
بسیار عالی
گویا tweepy برای نسخه های جدید Anaconda ویرایش نشده (برای Pythone 3.7.3) از طریق لینک زیر دانلود کردم
https://repo.continuum.io/archive/Anaconda3-4.3.1-Windows-x86_64.exe
برای اینکه مطمئن شوید که tweepy درست نصب شده می تونید از دستور زیر تو کامند ویندوز بعد از اینکه به آدرس Scripts رسیدین استفاده کنید (نمایش لیست پکیج ها)
pip list
سلام. ممنون از مطالب خوبتون
سوالم اینه که میشه از این روش برای جمع آوری توییت های انگلیسی استفاده کرد و با فیلتر کردن هشتگ های مورد نظر هم در توییت های جمع آوری شده باشن؟ یعنی فقط توییت و ریتوییت هایی جمع آوری بشن که هشتگ های مورد نظرم توش باشن؟ ممنون
می توانید از کلمات عمومی زبان انگلیسی که تقریبا توی بیشتر جملات هستند استفاده کنید .
سلام
ممنون از مطالب بسیارمفیدتون.
من api ایجاد کردم و توانستم تمامی کدهای شما را ران کنم و ممنونم از راهنمایی شما با مطالب ارزشمندتون.
و اما سوالم این هست که اگر من توئیت ها را با یک هشتگ خاص بخوام مثلا صادرات در ایران باید چطور اینکار را انجام بدهم؟ من در track در بخش filter وارد میکنم این کد را ولی خروجی فقط عدد ۴۰۱ یا ۴۰۲ تکرار میشود در هر سطر.
([‘صادرات_واردات’,’#ایران’ , ‘#صادرات’, ‘#واردات#’])=twitter_stream.filter(languages=[‘fa’], track
البته با این کد جواب گرفتم ولی توئیت های مورد نظرم نبود.
([‘واردات’,’صادرات’,’ ایران’])=twitter_stream.filter(languages=[‘fa’], track
و مسئله دوم این است که برای جمع آوری توئیت ها در یک دوره زمانی اگر نخواهم هر روز و هر ساعت توئیت ها را ذخیره کنم چی هست؟
ممنون من را راهنمایی بفرمایید.
سلام
ممنون از مطالب مفیدتون
اگر بخوام برای مدت زمان سه ماهه داده ها را جمع کنم باید چه کاری انجام دهم؟
جمع آوری دادههای سه ماه گذشته کمی مشکل است و توابع معمول توئیتر بیشتر برای جمع آوری لحظهای دادهها هستند اما اگر قصد جمع آوری دادهها از امروز تا سه ماه آینده را دارید، میتوانید از همین کدهای نوشته شده استفاده کنید. البته باید ابتدا یک اپ توئیتر بسازید و کلیدهای رمز مورد نیاز را دریافت کنید .