
دست به کد: جمع آوری و تحلیل اولیه آگهیهای استخدام جابینجا
در ادامه سلسله مقالات دست به کد که با هدف انجام عملی یک پروژه تحلیل داده از صفر تا صد در سایت مهندسی داده منتشر میشود، تصمیم گرفتم به بررسی و تحلیل دادههای سایت جابینجا به عنوان یکی از مراجع اصلی کاریابی آنلاین در ایران بپردازم. در بخش اول این مقاله به نحوه استخراج اطلاعات با کتابخانه معروف Scrapy و بررسی دادههای شرکتها با ابزار بسیار حرفهای و البته ساده هوش تجاری مایکروسافت یعنی پاوربیآی خواهیم پرداخت و بخش دوم این مقاله به تحلیل مشاغل، مهارتهای مورد نیاز بازار ایران، توزیع جغرافیایی بازارکار و مسایلی از این دست اختصاص خواهد داشت.
مطابق با روال آموزشهای گذشته، کدهای این پروژه داخل گیتهاب قرار گرفتهاند که اگر قصد افزودن سایتی جدید و یا تحلیل نوینی را به این آموزش داشتید و آنها را برای سایر خوانندگان سایت هم مناسب یافتید، آنرا fork کرده، تغییرات خود را اعمال کرده و نهایتاً از طریق Pull Request به ما اطلاع دهید که مخزن کد اصلی پروژه به روز رسانی شود.
استخراج دادههای شرکتها و مشاغل
در گام اول، باید سایت جابینجا را به دقت بررسی کنیم که ببینیم چه اطلاعاتی میتوان از آن استخراج کرد و این اطلاعات در چه صفحاتی قرار گرفتهاند و چگونه میتوان به آن صفحات دست پیدا کرد. اطلاعات اصلی مورد نیاز ما، اطلاعاتی هستند که با کلیک بر روی هر آگهی استخدام قابل مشاهده هستند. با کلیک بر روی هر آگهی، به صفحه اطلاعات آن آگهی که زیرمجموعه صفحه شرکت مربوطه است، هدایت میشویم که اطلاعاتی شبیه به زیر را به ما نشان میدهند :
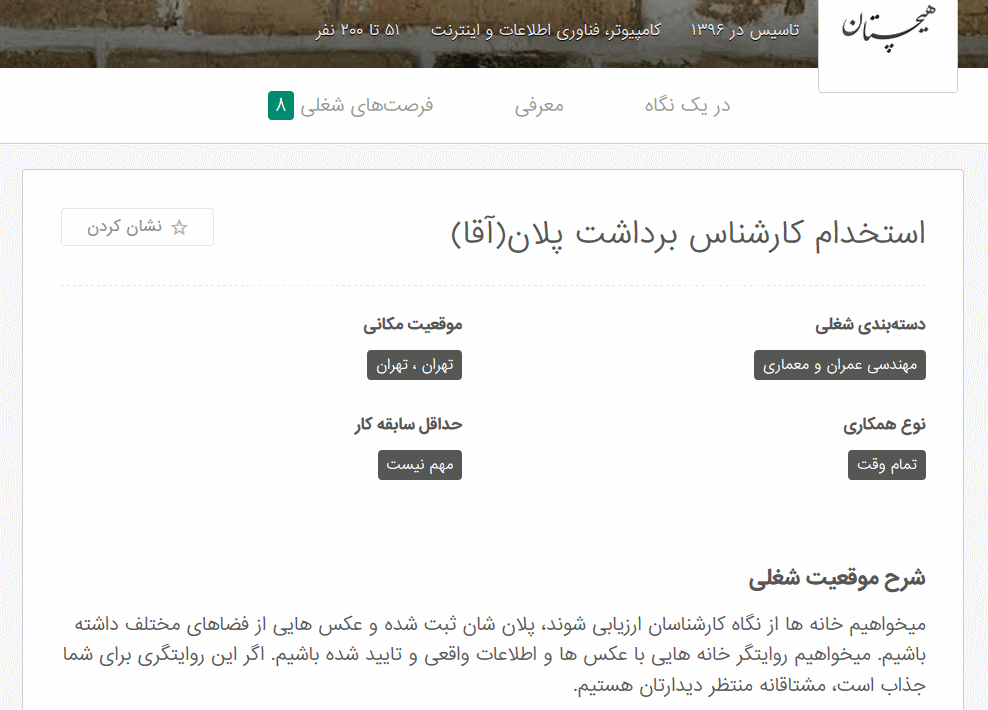
تمام اطلاعات مورد نیاز هر آگهی در همین صفحه قرار گرفته است و بنابراین باید راهی برای رسیدن به این صفحه پیدا کنیم. راهی که از طریق آن، بتوانیم اسکرپی و خزنده وب سفارشی خود را به سمت این آگهیها هدایت کنیم. هدف ما استخراج تمامی آگهیهای موجود در جابینجا شامل آگهیهای تاریخ گذشته و قدیمی هم هست و بنابراین باید روشی پیدا کنیم که ما را به این مقصود برساند. کمی که در سایت به گشت و گذار مشغول شویم، متوجه میشویم که در صفحه معرفی شرکتها، لینک تمامی شرکتها (البته به صورت صفحه به صفحه) وجود دارد:
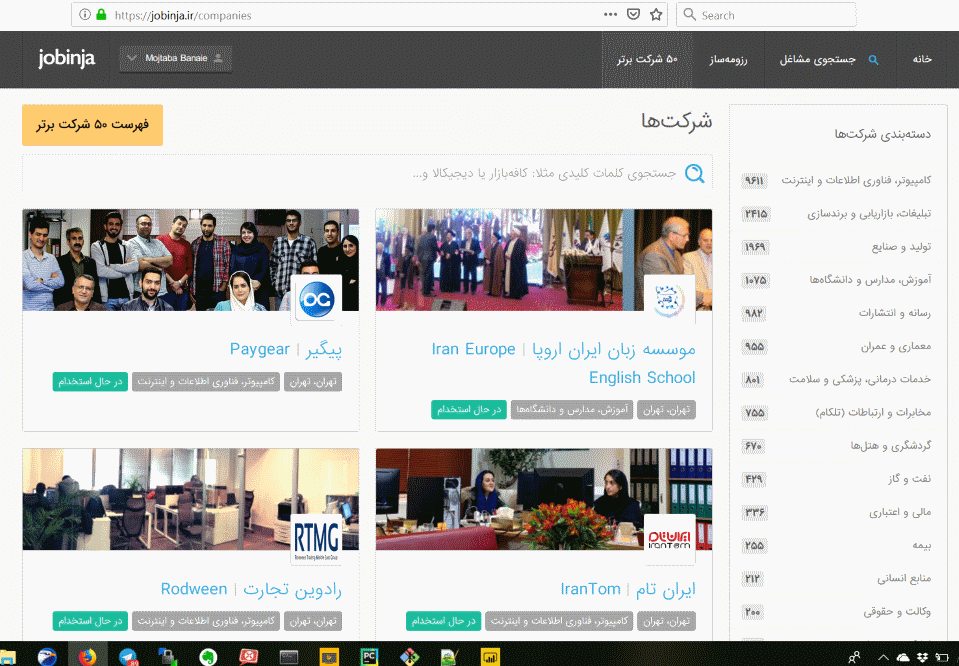
با کلیک بر روی هر شرکت، به صفحه معرفی خود شرکت هدایت میشویم :
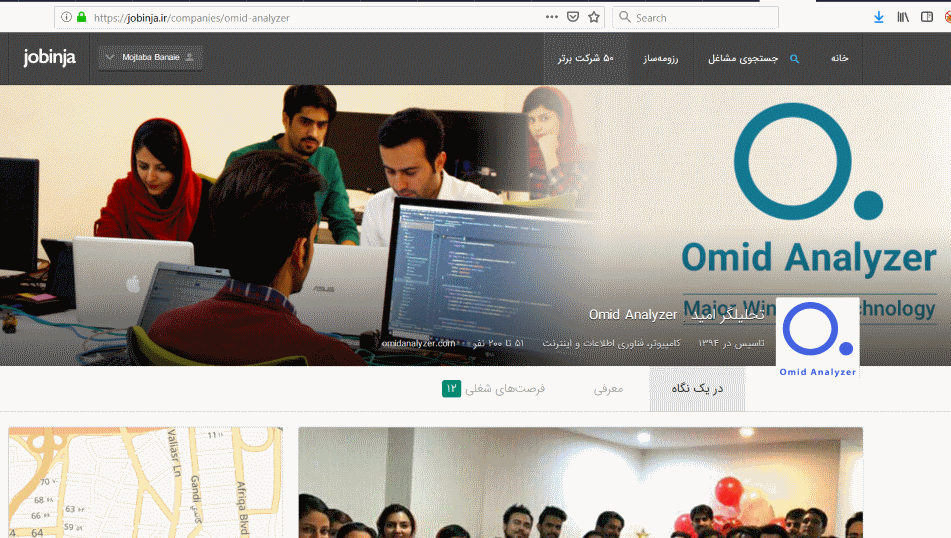
و سرآخر با کلیک بر روی لینک فرصتهای شغلی، صفحه آگهیهای استخدامی آن شرکت، برای ما باز میشود :
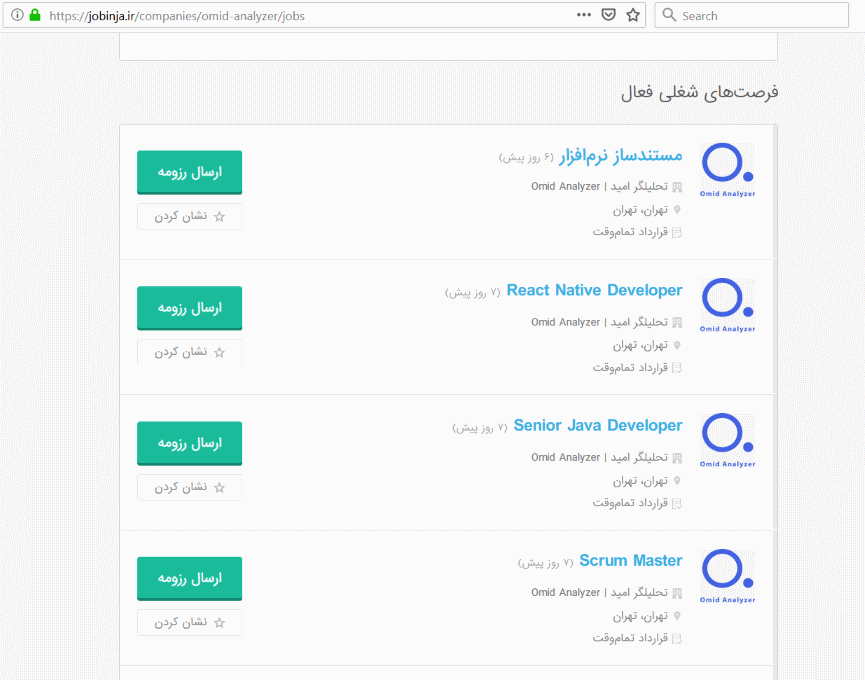
ادامه مسیر هم که مطابق بالاست یعنی کافی است بر روی هر آگهی (آگهیهای منقضی شده هم در این صفحه موجود هستند) کلیک کنیم تا به صفحه خود آگهی برسیم.
برای انجام این پروژه، مجبور شدم توضیحات قبلی که برای پروژه استخراج اطلاعات ایسنا به کمک اسکرپی داده بودم را به طور کامل بازنویسی کنم و مطالب جدیدی به آن بیفزایم. بنابراین در این قسمت، خوانندگان عزیز را به آن مقاله ارجاع میدهم و به بیان چند نکته را راجع به کدهای آن، بسنده میکنم.

دست به کد – استخراج متن وب سایتها با Scrapy
در این مقاله به نحوه ساخت یک خزنده وب برای استخراج اطلاعات سایتها به کمک کتابخانه معروف اسکرپی میپردازیم و با زدن یک مثال کاربردی برای استخراج اخبار سایت ایسنا، روند کار را به صورت مرحله به مرحله توضیح دادهایم.
توضیحاتی راجع به کدهای استخراج دادههای جابینجا در اسکرپی
اگر با اسکرپی، این کتابخانه محبوب پایتون برای خواندن دادههای وبسایتها آشنا هستید، میدانید که در این کتابخانه کافی است دو چیز را مشخص کنیم :
- خصوصیات داده مورد نیاز
- قوانین استخراج لینکها و تعیین آدرس هر قلم داده فوق
خصوصیات مورد نیاز به ازای هر موجودیت درون یک کلاس از نوع scrapy.Item درون فایل items.pyقرار میگیرند. قوانین استخراج لینکها هم درون پوشه spiders و داخل یک کلاس از نوع (معمولاً) CrawlSpider تعریف میشوند. با توجه به اینکه قصد ذخیره اطلاعات شرکتها و مشاغل را به صورت جداگانه داریم، دو کلاس مختلف به صورت زیر برای ذخیره اطلاعات هر یک از اینها در فایل items.py تعریف کردهایم :
همانطور که میبینید تقریباً برای تمام اطلاعاتی که قابل استخراج بوده است در دو کلاس فوق، خصوصیتی در نظر گرفته شده است که JobinjaCompanyItem برای ذخیره دادههای هر شرکت و JobinjaJobItem برای ذخیره دادههای هر آگهی منظور شده است.
برای قوانین استخراج لینکها هم از الگوریتم ساده زیر تبعیت کردهایم که از صفحه معرفی شرکتها شروع کنیم، اگر لینک موجود در این صفحه به آدرس /jobs ختم میشد، تابع parse_company_info را صدا میزنیم و اطلاعات شرکتها را استخراج میکنیم و follow=True را تنظیم میکنیم که به استخراج سایر لینکهای این صفحه که حاوی لینکهای آگهیهاست بپردازد. اگر لینک یک شرکت به صفحه معرفی شرکت ختم میشد ، آنرا به صورت دستی با تابع yield_company_jobsبه صفحه آگهیهای همان شرکت هدایت میکنیم و از آنجا که این صفحه آگهیها به /jobs ختم میشود، به طور خودکار تابع parse_company_infoصدا زده شده، لینک آگهیهای آن شرکت استخراج میشود.
اگر هم لینک استخراج شده حاوی یک آگهی باشد، با صدا زدن تابع parse_jobs عمل اصلی استخراج دادههای آن آگهی را انجام میدهیم. لیست نهایی قانونهای فوق به صورت زیر است :
در جلوی پارامتر allow قوانین فوق به صورت عبارات باقاعده ( Regex ) نوشته شدهاند که اگر با این عبارات بسیار پرکاربرد برای یافتن الگوهای متنی آشنا نیستید، به کمک این ابزار آنلاین، به سرعت میتوانید از طریق مشاهده مثالهای مختلف و سعی و خطا، اصول اصلی آنها را فرابگیرید. کدهایی که برای سه تابع فوق و ذخیره دادههای شرکتها و مشاغل نوشتهایم، کدهای مرتبط با اسکرپی هستند که اگر برایتان ناآشنا به نظر میرسند، مقاله اسکرپی در این زمینه را به دقت مطالعه کنید و بخش سلکتورهای XPath و CSS و لینکهای کمکی داده شده برای آموزش آنها را مرور کنید.
برای ذخیره اطلاعاتی که مقادیر مختلفی را برای یک ویژگی خاص از یک موجودیت نشان میدهند مثل مهارتهای مورد نیاز هر آگهی استخدام که خود بیش از یک مهارت است، از علامت ^ برای جدا کردن مقادیر استفاده کردهایم تا مرحله استخراج به سادهترین شکل ممکن انجام شود. بعداً در مرحله تحلیل، اصلاحات لازم را روی دادهها انجام خواهیم داد.
با دانلود کدهای فوق، اگر اسکرپی و پایتون روی سیستمتان نصب باشد، کافیست درون پوشه اصلی پروژه یعنی پوشه jobinja_crawler در خط فرمان، دستور scrapy crawl jobinja را بزنید تا اطلاعات شرکتها و مشاغل در دو فایل csvذخیره و آماده پردازش شود. اگر به صورت آنلاین قصد اجرای این کدها را دارید، همانطور که در بالا اشاره شد، این پروژه را کلون کرده، درون پوشه jobinja_crawler فایل start_crawler.ipynb را اجرا کنید. با اجرای اسکرپی و خزنده وب جابینجا، خروجیای مشابه زیر مشاهده خواهید کرد :
حال دو فایل companies_info.csv و companies_jobs.csv که حاوی اطلاعات مورد نیاز ما هستند، آماده استفاده است.
این فایل خروجی را بارها با دقت بررسی کنید تا نواقص کار را قبل از شروع تحلیل شناسایی و اصلاح کنید. شرطهای مختلفی که در کدهای خزنده وب مربوط به جابینجا میبینید، نتیجه همین بررسیها، مشاهده خطاها، بررسی آدرس آگهی یا شرکتی که دادههای آن ناقص یا اشتباه استخراج شدهاند در Scrapy Shell و اصلاح مداوم کدها بوده است.
تحلیل اطلاعات شرکتها به کمک پاوربیآی
در این مرحله فرض میکنیم که فایل csv اطلاعات شرکتها با نام companies_info-1398-01-05.csv در اختیار ماست (آنرا از این آدرس میتوانید دانلود کنید) و به عنوان اولین گام، فقط قصد تحلیل اولیه اطلاعات ساده شرکتهایی را داریم که متقاضی نیروی کار در چند سال گذشته در جابینجا بودهاند.
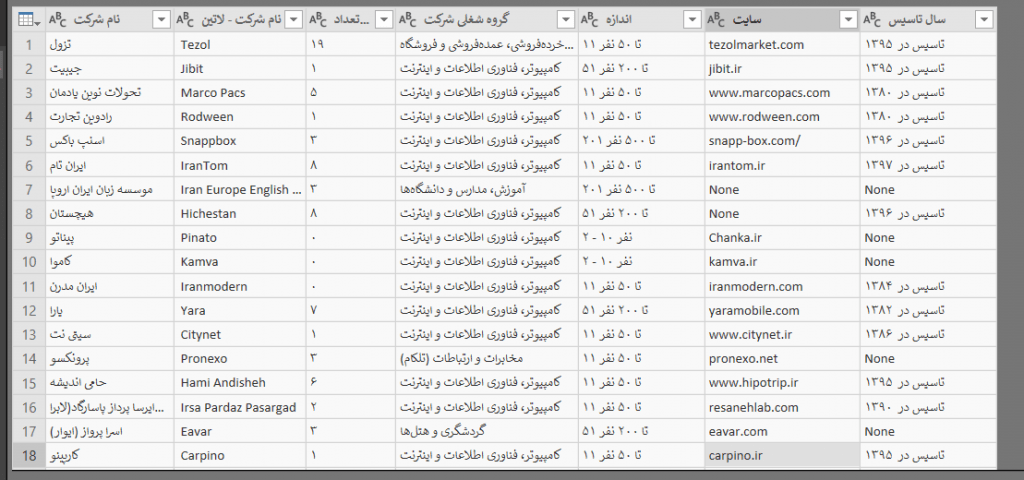
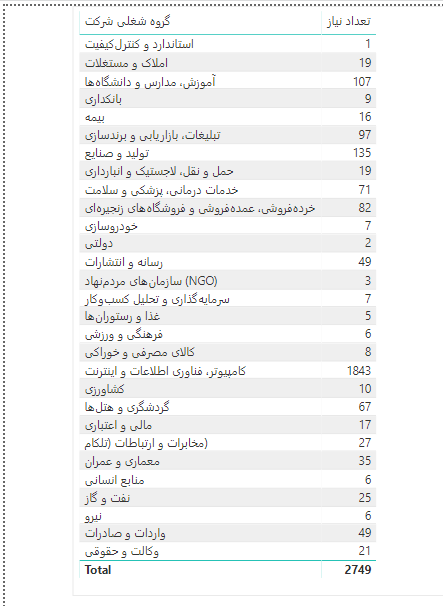
اطلاعاتی که توانستهایم از پروفایل یک شرکت در جابینجا کسب کنیم، اقلام زیر است :
همانطور که میبینید، اطلاعات چندانی راجع به شرکتها به دست نمیآوریم و فقط اندازه ، تعداد مشاغل مورد نیاز، سال تاسیس، گروه شغلی و سایت شرکت را به دست آوردهایم که برای شروع کار ما و آشنایی با فرآیند تحلیل دادهها و استخراج اطلاعات مفید از آنها کافی است. در بخش دوم این مقاله به صورت حرفهای تر به دادههای آگهیها و تحلیل بازار کار ایران (البته آنلاین) خواهیم پرداخت .
نصب و راه اندازی PowerBI
در گام اول، اگر هنوز نرم افزار هوش تجاری مایکروسافت یعنی پاوربیآی را نصب نکردهاید، آنرا از این آدرس دانلود و نصب کنید (۲۰۰ مگابایت) . برای دستگرمی و راه افتادن با این نرمافزار ساده و بسیار کاربردی که در ابتدای سال ۲۰۱۹ به عنوان یکی از پرچمداران ابزار هوش تجاری دنیا توسط گارتنر معرفی شد و نیز آشنایی با امکانات متنوع آن، تحلیل جام جهانی فوتبال ۲۰۱۴ را که قبلاً در این سایت منتشر شده است، به صورت عملی انجام دهید تا در ادامه این مقاله که چندان وارد جزییات کار نشده است، به مشکل خاصی برنخورید.
حتماً با باز کردن پاوربیآی یک حساب کاربری در آن ایجاد کنید.محدودیت مهمی که در این مرحله با آن احتمالاً مواجه میشوید عدم امکان ساخت اکانت در پاوربیآی با ایمیلهای عمومی مانند گوگل و یاهو است. توصیه بنده استفاده از ایمیل چاپار ایرانی و یا ایمیل شرکتی و اداری، برای غلبه بر این محدودیت است.
تحلیل جام جهانی ۲۰۱۴ برزیل با Power BI – بخش دوم
در ادامه سری آموزشی نرم افزار های هوش تجاری، در بخش دوم آموزش نرم افزار Power BI مایکروسافت به رسم نمودارهای مختلف با این ابزار و مصورسازی داده ها می پردازیم . مصورسازی یا نمایش گرافیکی داده ها در این بخش به مصورسازی و رسم چند نمودار به کمک مدل داده ای که در آموزش …
وارد کردن دادهها و تنظیمات اولیه
پاوربیآی را باز کنید و گزینه Get Data را بزنید و از لیست منابع مختلف دادهای که امکان اتصال و خواندن آنها را دارد، text/CSV را انتخاب کنید.
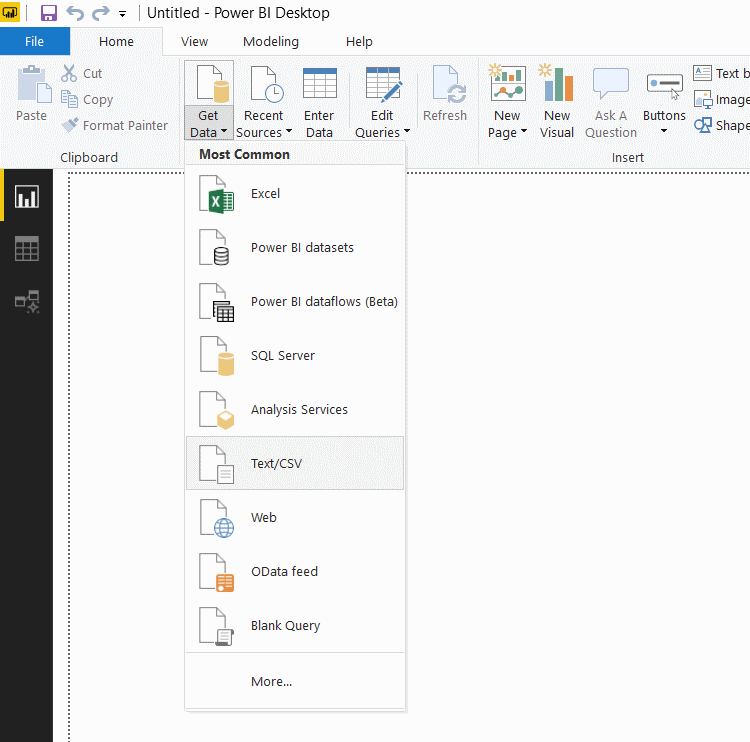
آدرس فایل اکسل را که وارد کنید، با صفحهای مشابه زیر مواجه میشوید :
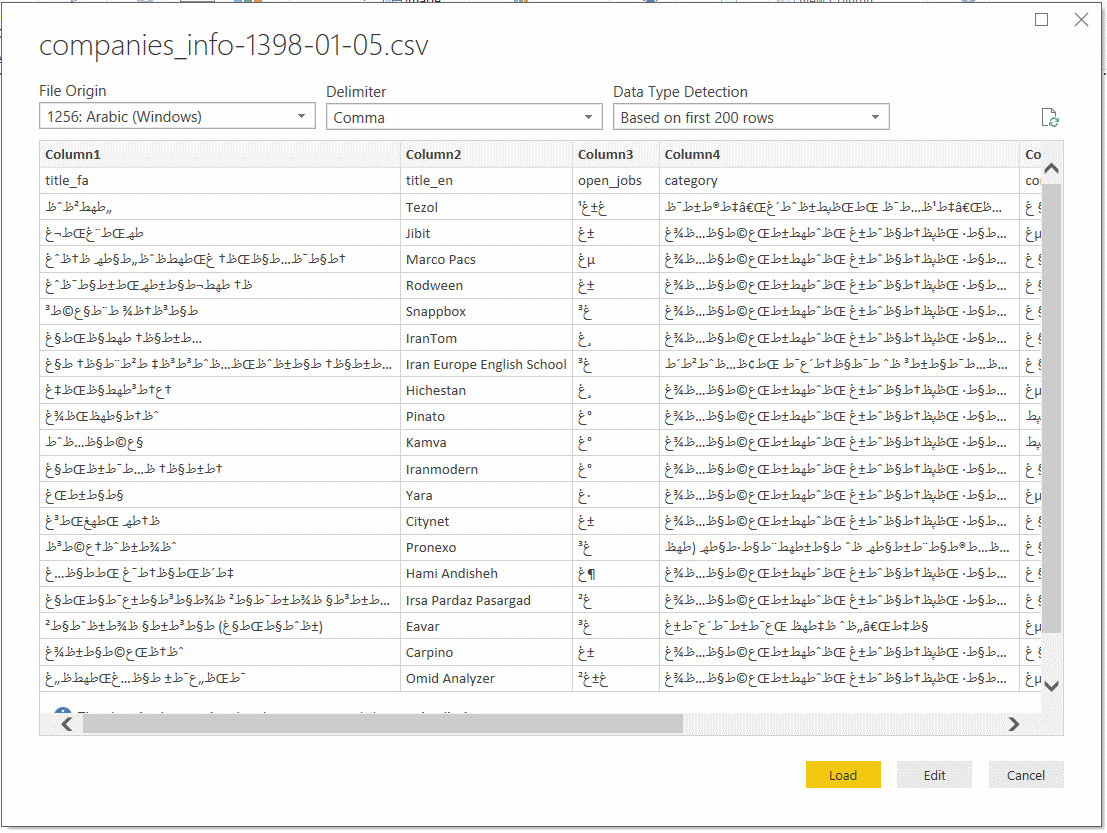
گزینه File Originرا به UTF-8به صورت زیر تغییر دهید تا دادهها را به درستی نمایش دهد :
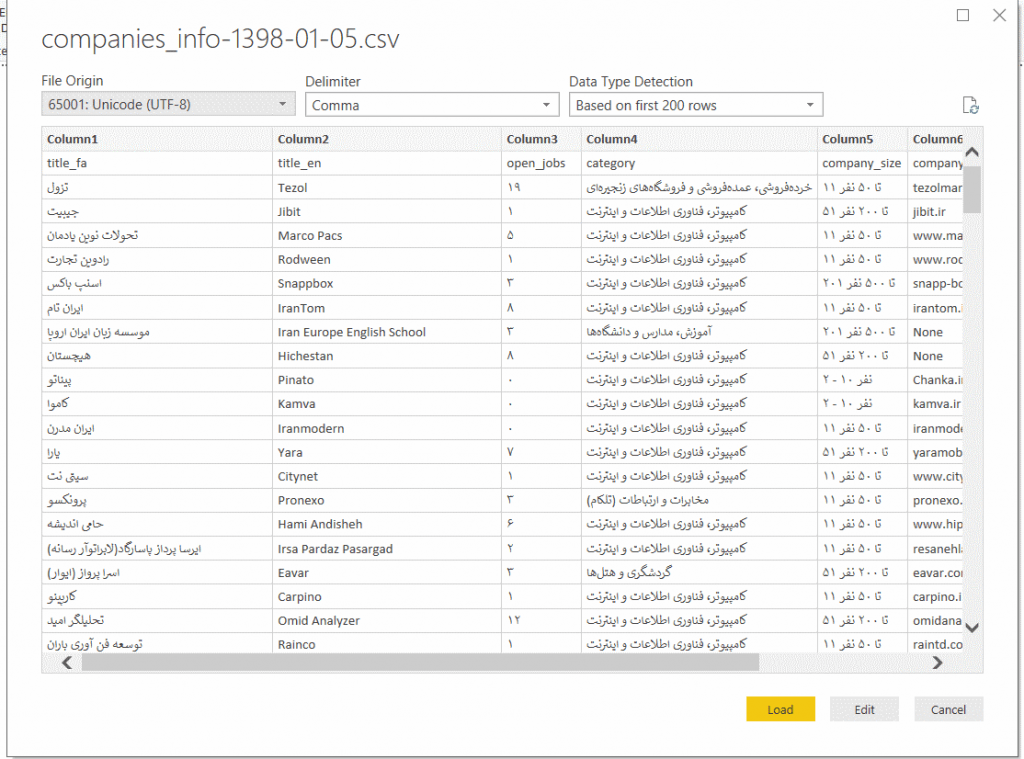
تا اینجا همه چیز، بدون اشکال پیش رفته است فقط نام ستونها که خط اول فایل CSV است باید به پاوربیآی داده شود. بنابراین روی گزینه Edit کلیک میکنیم تا به صفحه ویرایش دادهها منتقل شود. در منوی بالای همین صفحه، آیکون Use First Row As Header را کلیک کنید تا نام ستونها اصلاح شود.
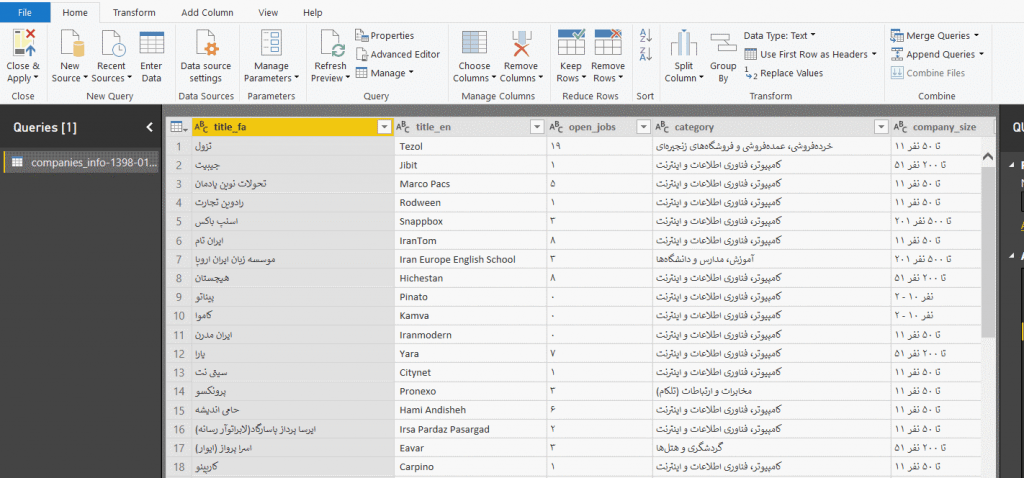
بهتر است نام ستونها را هم به دلخواه تغییر دهیم و نام فارسی مناسبی برای آنها انتخاب کنیم. بر روی نام ستون دوبار کلیک کنید و یا گزینه Rename را با کلیک راست بر روی نام ستون، بزنید و به صورت زیر نامها را تغییر دهید :
اولین آیکون یعنی Close & Apply را کلیک کنید تا عملیات بارگذاری دادهها انجام شود. مرحله اول کار ما، تمام شده است.

رسم اولین نمودار
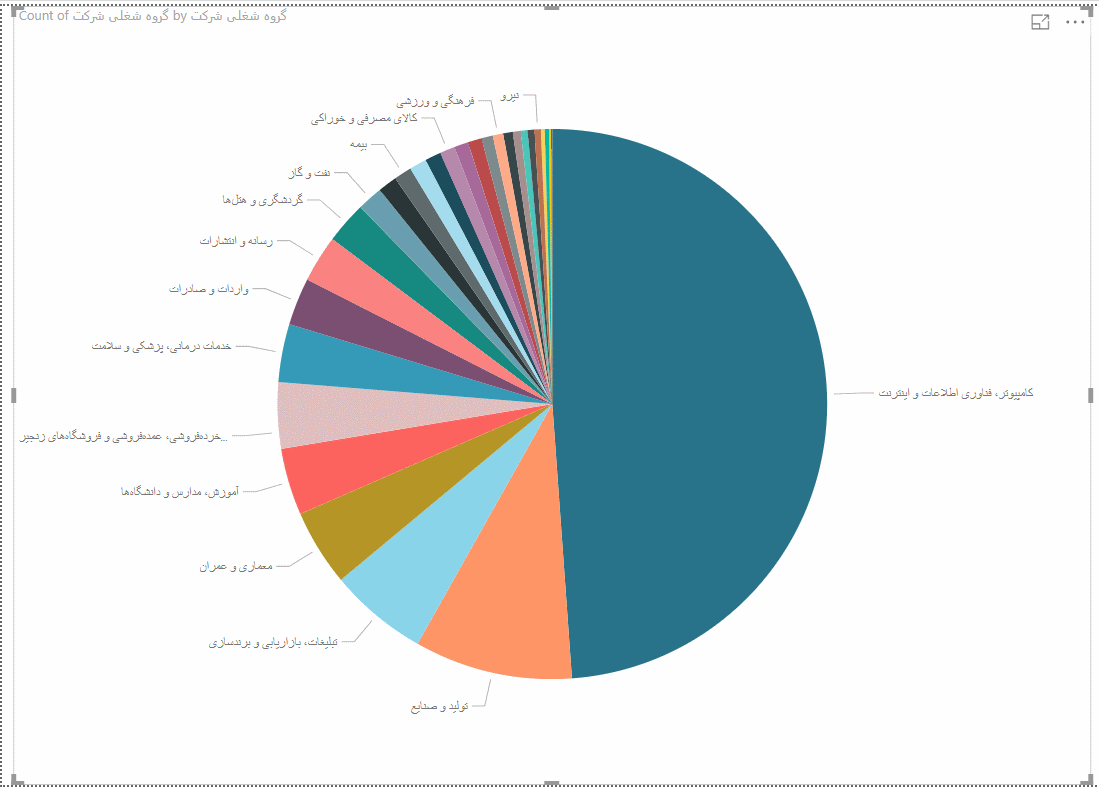
اکنون و با لودشدن دادهها، یک صفحه سفید مقابل خود میبینید و لیست ویژگیها و انواع نمودارهای قابل رسم هم در سمت راست قابل مشاهده است. برای شروع میخواهیم ببینیم تعداد شرکتهای هر گروه شغلی چقدر است و کدام گروه شغلی، بیشترین رواج را دارد. از نمودار Pie Chart برای این منظور استفاده میکنیم. این نمودار را روی صفحه بکشید. سپس ویژگی گروه شغلی را به قسمت Details و همین ویژگی را به قسمت Values هم بکشید که چون نوع دادهها، رشتهای است، تعداد آنها را به صورت پیش فرض محاسبه میکند.
اولین تحلیل بصری ما به صورت زیر نمایان خواهد شد :
حال میخواهیم با همین نمودار ساده که به راحتی توزیع گروههای شغلی را در بین شرکتها نمایش میدهد، کمی بازی کنیم. اگر یادتان باشد یکی از ویژگیهای دادهها، تعداد مشاغل مورد نیاز بود که برای بسیاری از شرکتها این مقدار، صفر است. میخواهیم شرکتهایی با تعداد نیاز صفر را از نمودار فوق حذف کنیم. برای اینکار ویژگی تعداد مورد نیاز را از سمت راست به قسمت Filters و زیر بخش Visual Level Filter می کشیم. سپس با کلیک بر روی آن در قسمت فیلترها، ابتدا گزینه select all را می زنیم تا همه تعداد نیازها انتخاب شود و سپس صفر را از لیست انتخاب شدهها حذف میکنیم :

تعداد مشاغل مورد نیاز هر گروه شغلی
در ادامه کار، میخواهیم ببینیم توزیع مشاغل مورد نیاز بر اساس هر گروه شغلی به چه صورت است. برای این منظور نیاز به یک نمودار ستونی داریم که محور افقی آن، گروههای شغلی و محور عمودی آن مجموع تعداد مشاغل موردنیاز هر گروه باشد. اما در اینجا دو تا مشکل وجود دارد :
- نوع داده تعداد مشاغل مورد نیاز، عددی نیست
- اعداد موجود با فونت فارسی وارد شدهاند
برای مشکل اول، کافیست وارد Query Editor شویم و با کلیک راست بر روی نام ستون، نوع داده را عوض کنیم اما به دلیل وجود مشکل دوم که اعداد، به صورت فارسی وارد شدهاند این کار با خطا مواجه خواهد شد. بنابراین ابتدا باید مشکل اعداد فارسی را حل کنیم. از آیکونهای بالای صفحه، Edit Queries را انتخاب کنید تا وارد صفحه ویرایش دادهها شود.
بر روی نام ستون کلیک راست کرده و از منوی ظاهر شده گزینه Replace Values را انتخاب کرده و تک تک ارقام فارسی را با ارقام انگلیسی جایگزین کنید.(برای هر رقم فارسی یک بار باید اینکار را انجام دهید- ده بار ).
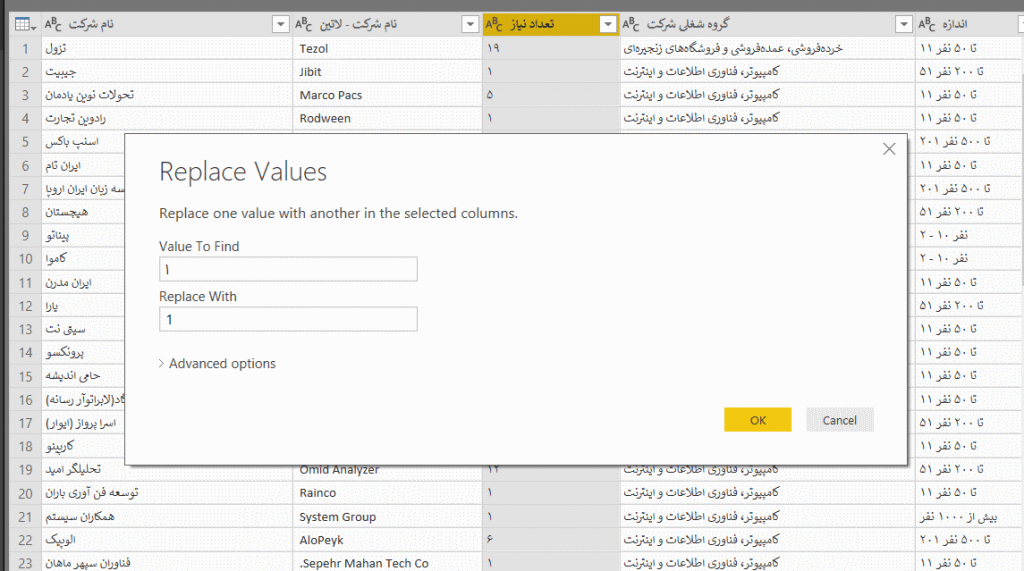
حال به راحتی با کلیک راست بر روی نام ستون، انتخاب گزینه Change Type و سپس Whole Number این ستون را به نوع داده عددی تبدیل کنید. با زدن گزینه Close & Apply به صفحه اصلی پاوربیآی برگردید. در پایین صفحه با زدن علامت + یک Page جدید باز کنید.
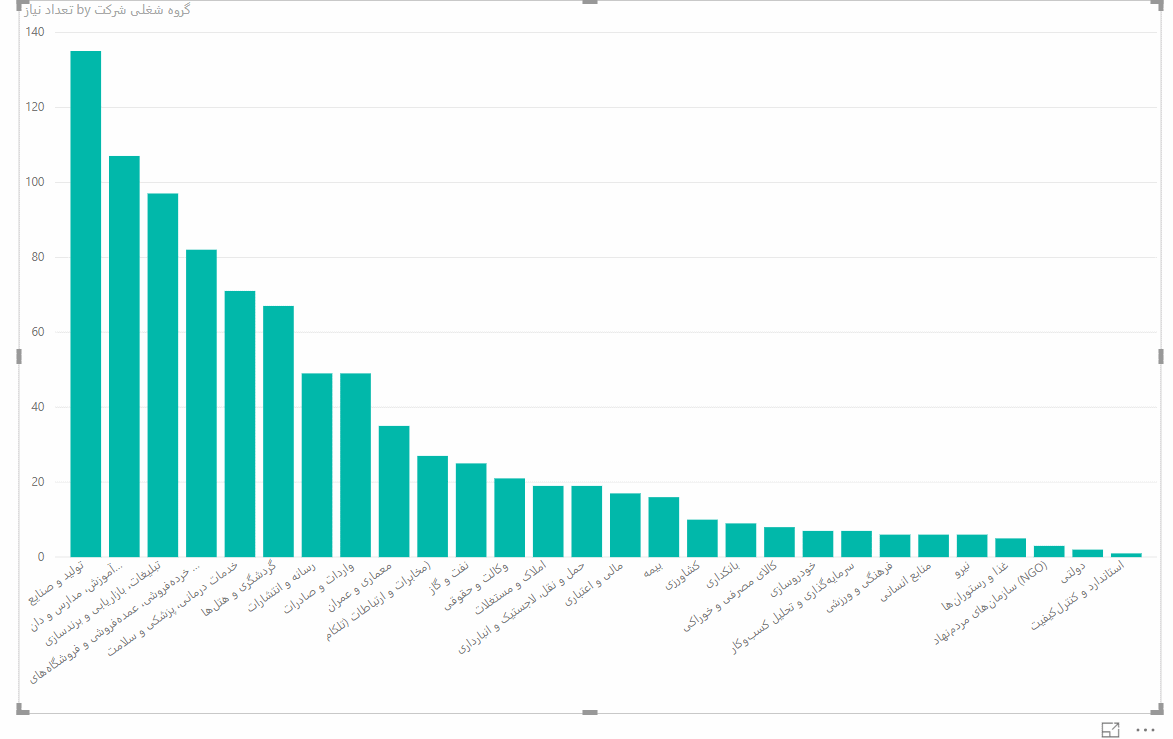
یک راه ساده برای ایجاد نمودار، این است که ابتدا دادههای مورد نیاز برای آن نمودار و تحلیل بصری را آماده کرده، فیلترهای لازم را اعمال کنیم و نهایتاً بر روی نمودار مربوطه کلیک کنیم تا بر اساس این دادهها، نمودار نهایی به سرعت ایجاد شود. بنابراین این دفعه، خود گروه شغلی را از سمت راست به وسط صفحه بکشید تا یک جدول حاوی دادههای این گروه شغلی ایجاد شود. سپس تعداد نیاز را هم به روی همین جدول بکشید.
از قسمت Values در سمت راست، بر روی تعداد نیاز کلیک کنید تا مطمئن شوید که تابع sum بر روی آن اعمال شده است. حال کافیست بر روی یکی از انواع نمودارهای ستونی کلیک کنید تا همین جدول را به صورت نموداری به شما نمایش بدهد. میبینیم که گروه شغلی کامپیوتر و فناوری اطلاعات با تعداد مشاغل مورد نیاز بسیار بالا، نمودار را تحث تاثیر قرار داده است و بنابراین بهتر است حال که متوجه شدهایم گروه فناوری اطلاعات بیشترین تعداد نیاز به نیروی کار را دارد، این گروه را از نمودار حذف کنیم. برای این منظور، گروه شغلی را به قسمت Filters بکشید و مشابه فوق، همه گروهها بجز این گروه را انتخاب کنید تا توزیع مشاغل مورد نیاز بر حسب سایر گروههای شغلی را مشاهده کنیم :
تحلیل نوع دامنه سایت شرکتهای ایرانی
کار دیگری که میتوانیم بر روی دادهها انجام دهیم، بررسی این موضوع است که سایتهای شرکتهای ایرانی، چه نوع دامنههایی را برای خود برگزیدهاند. برای اینکار، ابتدا باید نوع دامنه را از انتهای نام سایت شرکت، جدا کنیم و سپس تحلیل خود بر روی آنها را انجام دهیم.
در سمت چپ صفحه بر روی آیکون جدول یا Data کلیک کنید تا ابتدا به صورت چشمی، نام دامنهها را بررسی کنیم و اگر ایرادی هست و اصلاحی باید انجام شود، آنها را انجام دهیم.
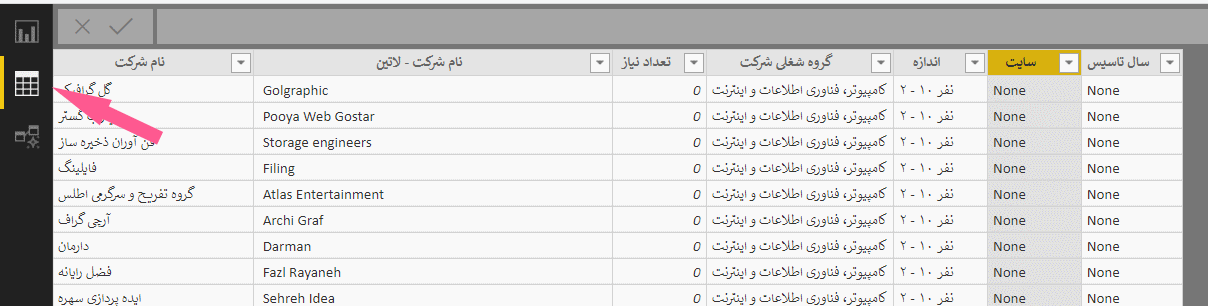
با دقت در نام سایتهای شرکتها متوجه میشویم دو ایراد در این بخش وجود دارد. اول اینکه خیلی از دامنهها علامت / را در انتهای نام خود دارند که باید حذف شود و دوم اینکه خیلی از سایتها علاوه بر /، دادههایی را هم بعد از /دارند مثل fa , aboutus که آنها هم باید حذف شوند. روی Edit Queries کلیک کنید تا وارد بخش ویرایش دادهها شویم.
با توجه به اینکه کاراکتر /فقط در انتهای نام دامنهها آمده است (البته ممکن است چند عدد / در انتهای نام یک سایت آمده باشد که به آن میپردازیم) و در هیچ بخش دیگری از نام سایت، تکرار نشده است، روش ساده تجزیه ستون نام سایت بر اساس این کاراکتر به دو ستون و حذف ستون اضافی را در پیش میگیریم. از بخش home آیکون Split Column و سپس زیرگزینه By Delimiter را انتخاب میکنیم :
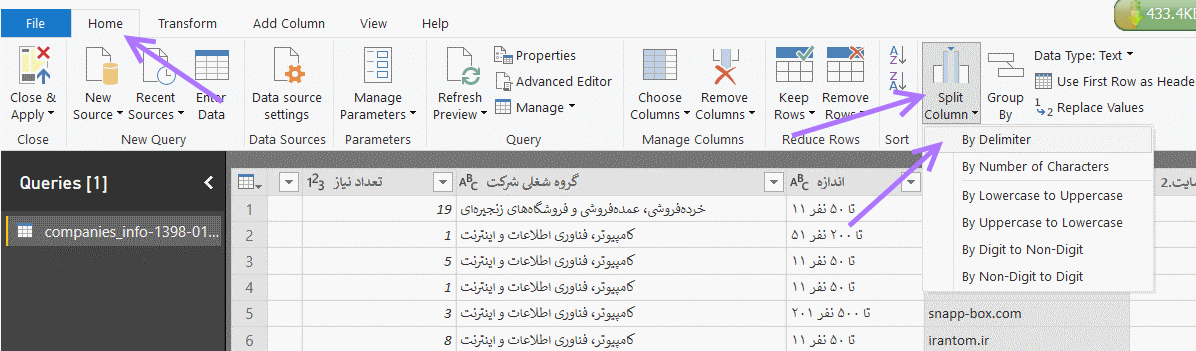
پنجره ظاهر شده را به صورت زیر پر میکنیم :
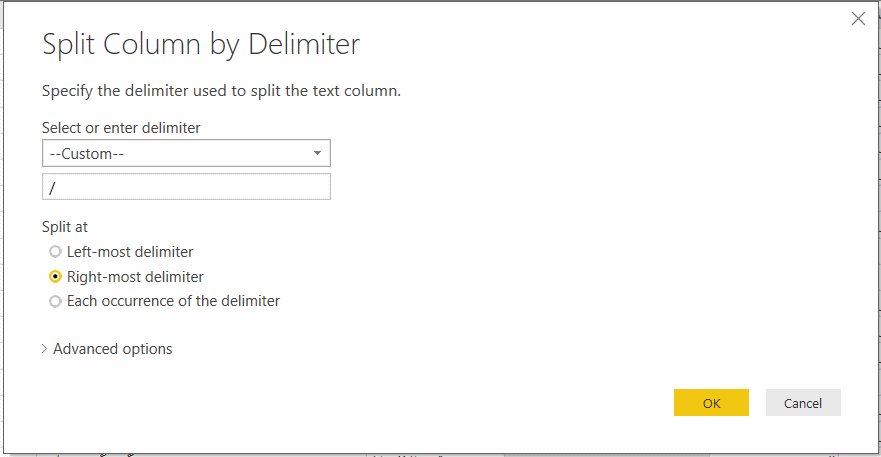
با زدن دکمه OK ستون سایت به دو ستون سایت ۱ و سایت ۲ تبدیل میشود که سایت ۲ حاوی هر آنچیزیست که بعد از / در نام سایتها آمده است. این ستون را لازم نداریم. بنابراین با کلیک راست روی نام ستون، آنرا حذف میکنیم (Remove) و نام ستون سایت ۱ را به همان نام سایت بر میگردانیم (عدد یک را حذف میکنیم)
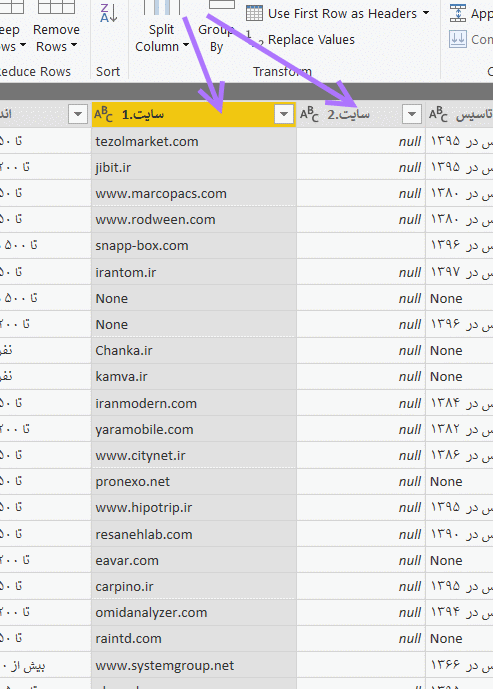
مجدا که بررسی میکنیم می بینیم هنوز برخی سایتها، در انتهای نامشان علامت /و بعد از آن هم چند کاراکتر آمده است. روال فوق را یکبار دیگر تکرار میکنیم تا مطمئن شویم کاراکتر اضافی از انتهای تمام نامها حذف شده است. حال به کار اصلی خود که استخراج نوع دامنهها (کاراکترهای بعد از آخرین نقطه در نام سایت) بود برمیگردیم. برای اینکار هم از توابع Extract که برای استخراج بخشی از یک رشته به کار میروند استفاده میکنیم. از قسمت Add Column آیکون Extract و سپس زیر گزینه Text After Delimiter را انتخاب می کنیم.
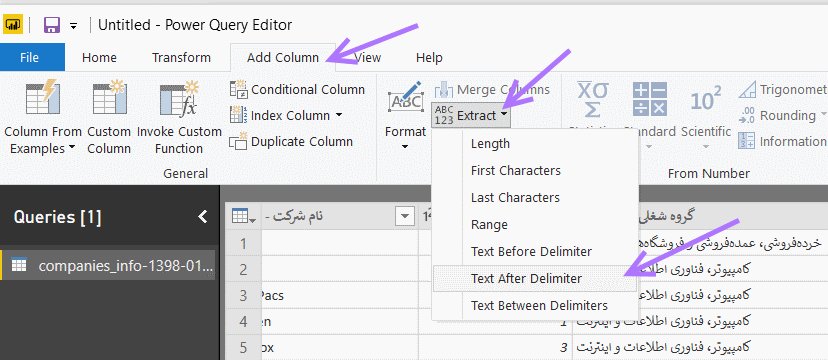
در پنجره ظاهر شده، جداکنندهای که متن بعد از آنرا می خواهیم استخراج کنیم برابر . و نحوه جستجو را از انتهای رشته تعیین میکنیم :
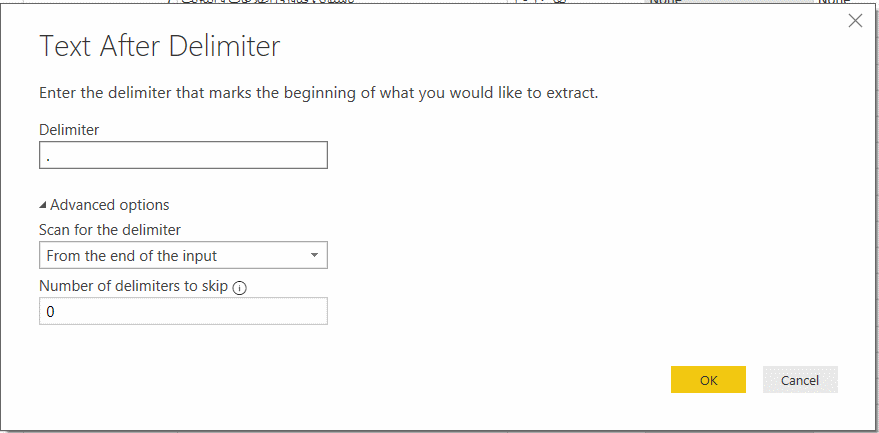
با زدن دکمه OKستونی با نام Text After Delimiter حاوی نوع دامنه شرکت ایجاد میشود. بر روی آن دوبار کلیک کنید و نام آنرا را برابر نوع دامنه بگذارید. با زدن دکمه Close & Apply ، تغییرات را نهایی کنید و به صفحه اصلی پاوربی آی برگردید. دقت کنید که احتمالاً در حالت نمایش جدولی دادهها هستید. از سمت چپ آیکون نمودار را بزنید تا وارد حالت گزارش سازی شود.
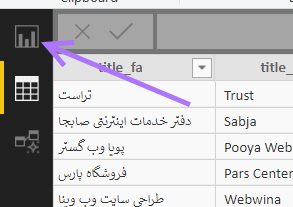
دکمه + در پایین صفحه را بزنید تا صفحه داشبورد جدیدی باز شود، سپس ستون نوع دامنه را از سمت راست به وسط صفحه بکشید. حال تعداد شرکتهای دارای هر نام را هم لازم داریم. مجدداً نوع دامنه را به روی این جدول ایجاد شده بکشید. سپس از قسمت Values با کلیک بر روی نوع دامنه دوم، گزینه Count را مطابق شکل زیر انتخاب کنید :
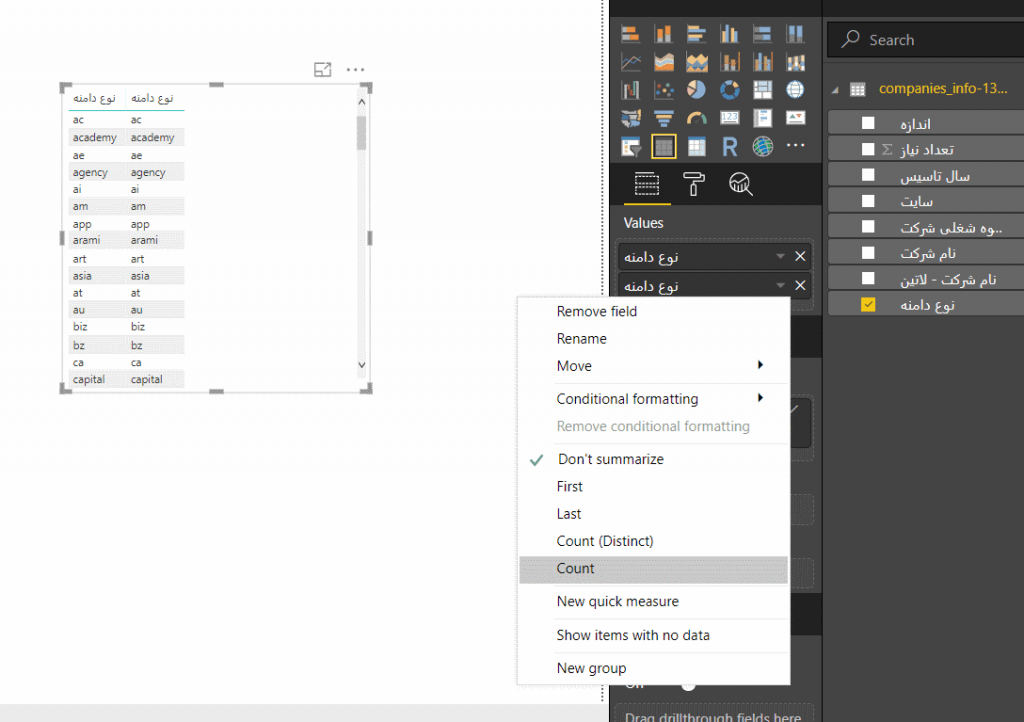
حال جدول ایجاد شده، حاوی نوع دامنهها و تعداد هر یک است. بهتر است نوع دامنه هایی که تعدادشان بالای ۱۰ عدد است را انتخاب کنیم تا نمودار شلوغی در خروجی کار تولید نشود. این کار را به صورت زیر و با استفاده از قسمت Filters و انتخاب ستون دوم دادهها یعنی Count of نوع دامنه انجام دهید :
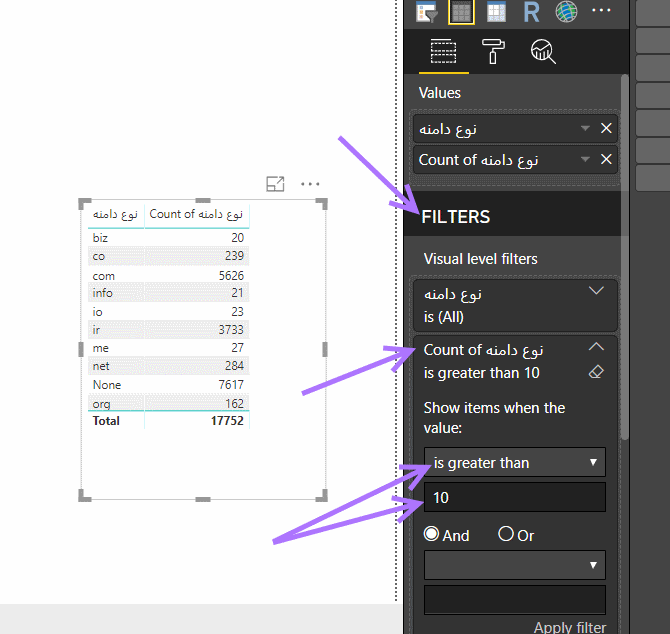
حال در حالتی که جدول دادهها انتخاب شده است، نمودار HeatMap را انتخاب کنید تا توزیع نوع دامنه را با این نمودار مشاهده کنیم :
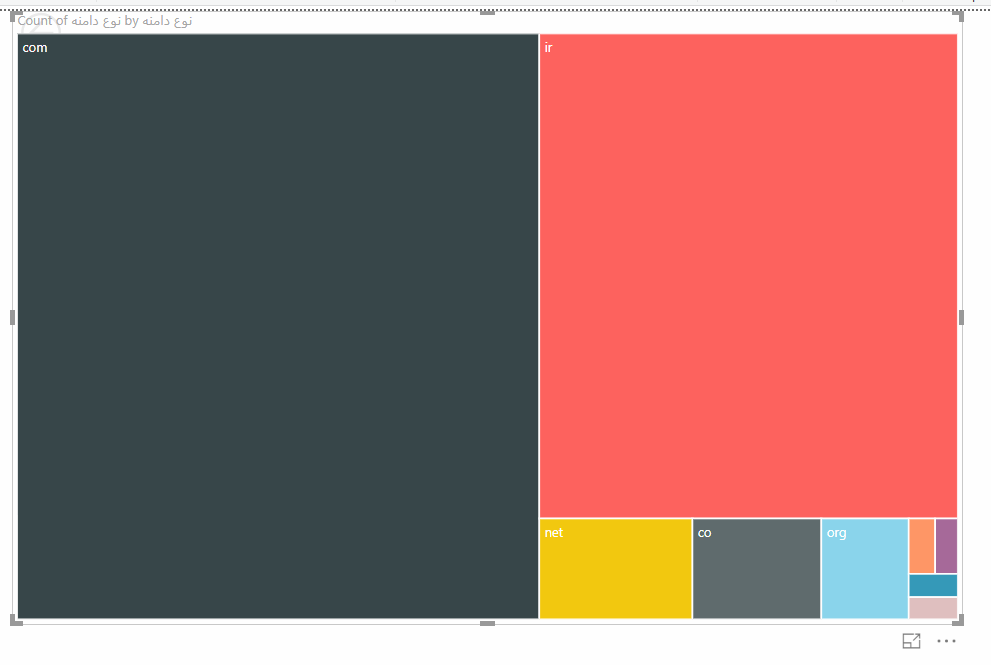
همانطور که میبینید بیشترین نوع دامنه در اختیار com و irاست. حالا که تا اینجا را بررسی کردهایم بهتر است یک مرحله دیگر هم پیشروی کنیم و ببینم گروه شغلی شرکت هم تاثیری در انتخاب نوع دامنه دارد یا نه. فقط کافیست گروه شغلی شرکت را به قسمت Drillthrough در زیر قسمت Filtersبکشیم تا امکان انتخاب هر گروه شغلی و تغییر نمودار بر اساس آن برای ما فراهم شود. با بررسی سرسری گروههای مختلف متوجه میشویم که اکثر گروههای شغلی، تنها دو دامنه irو comرا انتخاب میکنند و دامنههای متنوع بیشتر متعلق به گروه کامپیوتر و فناوری اطلاعات است.

تحلیل اندازه شرکتها و نیاز آنها به نیروی کار
برای آخرین تحلیل این آموزش، میخواهیم اندازه شرکتها را در تعداد نیاز آنها به نیروی کار هم بررسی کنیم. اگر به این ستون دقت کنیم میبینیم که دادهها به صورت رشتهای و در یک بازه عددی بیان شده است. به جدول زیر دقت کنید :
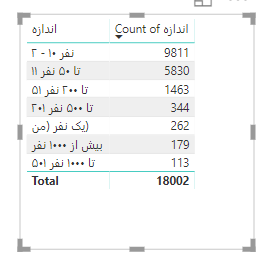
می خواهیم به شرکتهای زیر ۵۰ نفر ، برچسب خرد، به شرکتهای تا ۲۰۰ نفر برچسب کوچک ، تا ۵۰۰ نفر برچسب متوسط، تا هزار نفر برچسب بزرگ و بیش از ۱۰۰۰ نفر برچسب خیلی بزرگ اختصاص دهیم و بر اساس آن، تعداد نیاز نیروی کار را تحلیل کنیم. برای این کار، میتوانیم از قسمت Add Column استفاده کنیم و با استفاده از قابلیت ساخت ستونهای شرطی، این کار را به صورت زیر انجام دهیم (یادتان باشد که باید وارد قسمت Edit Queries شوید) :
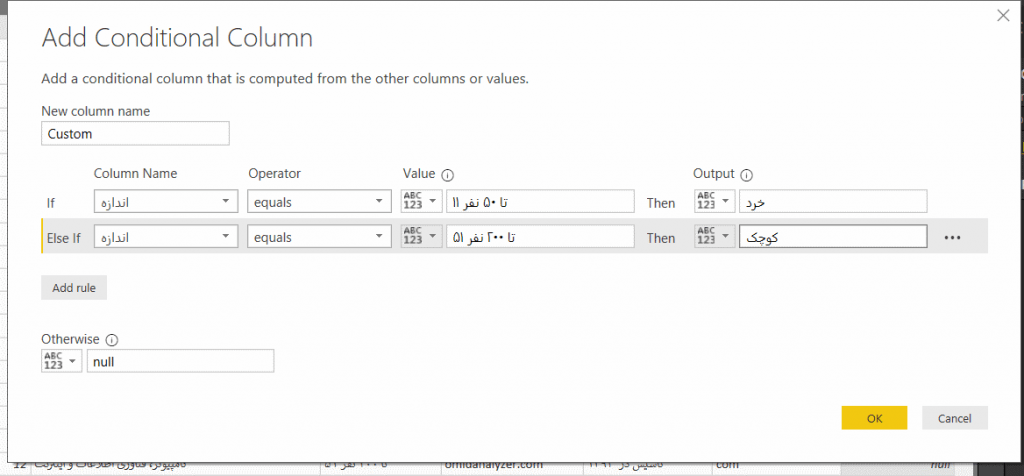
اما راه خیلی سادهتری هم برای اینکار وجود دارد. بر روی نام ستون اندازه کلیک راست کنید و گزینه Add Column From Examples را بزنید تا صفحه زیر باز شود و به ازای هر مقدار از مقادیر فوق، یکی از برچسبهای فوق را تایپ کنید تا آنرا برای همه دادههای مشابه با آن مقدار،تکرار کند.
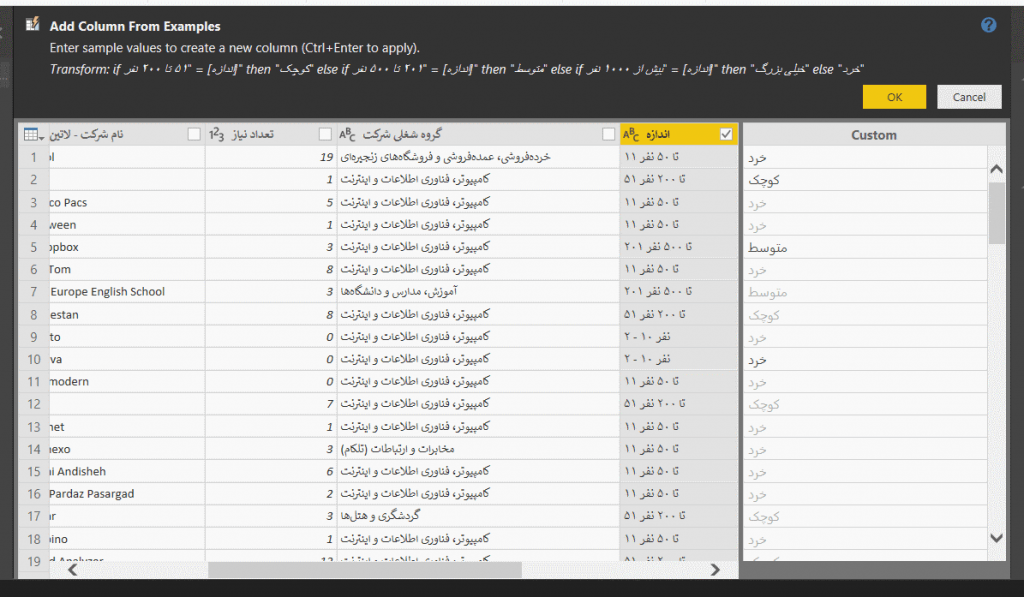
اعمال تغییرات را با زدن ok به اتمام رسانده، نام ستون جدید را به اندازه شرکت تغییر دهید و با Close & Apply از قسمت ویرایش دادهها خارج شوید.
حال کافیست یک page جدید به بخش Reports اضافه کنید، ابتدا اندازه شرکت را به این صفحه بکشید و سپس تعداد نیاز را به همین صورت به روی دادههای فوق بکشید و مطمئن شوید که تابع sum برای این ستون جدید، انتخاب شده است. حال کافیست که نمودار Donutرا انتخاب کنید :
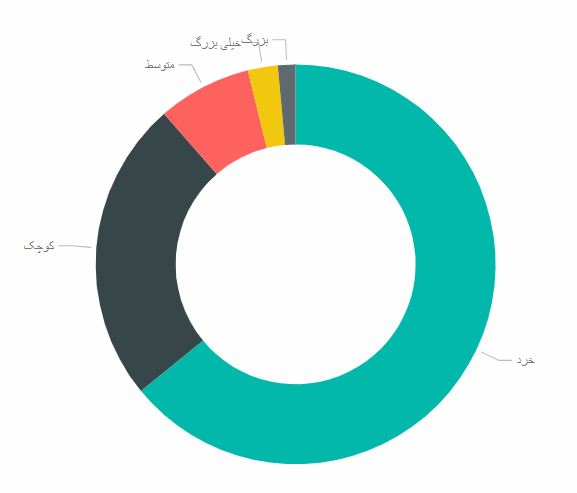
سخن پایانی
امیدوارم که مطالب فوق اشتیاقی به شما برای تحلیل دادههای روزمرهای که با آنها سروکار دارید ایجاد کرده باشد. در قسمت دوم این مقاله، به ادامه کار و تحلیل بازار کار ایران بر اساس دادههای جابینجا خواهیم پرداخت.