
در ماه های انتهایی سال ۲۰۱۷ بعد از چندین سال کار مداوم، نسخه ۳ هدوپ به صورت رسمی عرضه شد. در این مقاله به قابلیتهای نوین این نسخه از چارچوب پردازشی محبوب کلان داده خواهیم پرداخت.
تغییرات اصلی که در این نسخه شاهد هستیم عبارتند از :
- ارتقا به نسخه ۸ جاوا
- پشتیبانی از الگوریتم کدگذاری Erasure در HDFS
- ارتقای سرویس خط زمان YARN و سهولت استفاده از داکر
- بازنویسی کدهای اسکریپت ها و دستورات خط فرمان
- رفع ناسازگاری کتابخانه های هدوپ با سایر کتابخانه های عمومی جاوا
- پشتیبانی از محفظه های اجرایی فرصت مند
- بهینه سازی فرآیند توزیع و تجمیع در سطح Task
- تغییر پورت های پیش فرض بسیاری از سرویس های پایه هدوپ
- اتصال به سیستم فایل های جدید(اتصال به سرویس های ابری آمازون و مایکروسافت و .. .به صورت مستقیم)
- توزیع بار خودکار بین گره های داده (Data Node Load Balancer)
- بازنویسی مجدد برنامه های پشت صحنه هدوپ و ارتقای مدیریت حافظه آنها

با هم این تغییرات را به صورت جزئی تر مرور می کنیم :
ارتقای نسخه کامپایل شده هدوپ به جاوای ۸
با توجه به اینکه چند سال است دیگر جاوی ۷، رسما پشتیبانی نمی شود (از آوریل ۲۰۱۵) و از طرفی بسیاری از کتابخانه های مطرح و مورد استفاده هدوپ هم با جاوای نسخه ۸ سازگار هستند، اولین تغییر مشاهده شونده در هدوپ، ارتقای آن به جاوای ۸ است.
پشتیبانی از کدگذاری اِرِیژر (Erasure Coding)
یکی از تغییرات اساسی صورت گرفته در هدوپ ۳، پشتیبانی از کدگذاری اِریژر برای کاهش فضای ذخیره سازی فایل هاست. Erasure به معنای پاک شدن و پاک کردن است و منظور از کدگذاری اِریژر، کدگذاری داده ها به گونه ای است که حتی با پاک شدن و از بین رفتن برخی از داده ها، بتوان آنها را بازیابی نمود.
الگوریتم کدگذاری اریژر، به صورت گسترده در دیسکهای RAID و برای کاهش فضای ذخیره سازی در عین محافظت از آنها در هنگام رخداد خطا در مراکز داده مورد استفاده قرار می گیرد. در این روش، هر فایل به بلاک هایی تقسیم می شود، بلاک های متوالی در دیسک های جداگانه ذخیره می شوند و به ازای هر چند بلاک داده متوالی، چند بلاک توازن (Parity) هم تولید و جداگانه ذخیره می شود تا در صورت حذف یک یا چند بلاک ، بتوان به کمک بلاکهای باقیمانده و نیز بلاک های توازن، آنها را بازتولید کرد.
برای درک بهتر موضوع، فرض کنید کدگذاری اریژر انتخاب شده برای محافظت از داده ها، تابع XOR معمولی باشد. در XOR اگر تنها یکی از دو بیت، یک باشند نتیجه یک و در غیر اینصورت، نتیجه ۰ است.
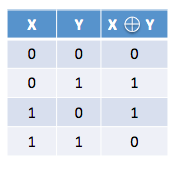
حال اگر بلاک X از بین برود یا در دسترس نباشد، با مقایسه مقادیر متناظر بلاک Y و بلاک توازن و XOR کردن آن دو، مقدار X را می توان به راحتی پیدا کرد. شکل زیر این مفهموم را نشان می دهد :

البته در سیستم های واقعی و در هدوپ، از کدگذاری رید-سالامون برای ایجاد بلاک های توازن استفاده می کنند. توصیفی که در ویکی پدیا برای این کدگذاری می توانیم بیابیم از قرار زیر است :
«این روش توسط ایروینگ اس رید و گوستاو سولومون ابداع شد، این نوع کدگذاری تنها روش غیرباینری در بین کدگذاریها محسوب میشود. کدگذاری ریدسالامان روشی سیستماتیک برای ساختن کدهایی با قابلیت شناسایی چندین خطای نشانه تصادفی است که توانایی تشخیص هر ترکیب از t نشانه خطادار و تصحیح تا t/۲⌋ ⌊ نشانه را دارا است. کدگذاری رید سالامان برای استفاده به صورت تصحیح خطای بیتی مسلسلوار مناسب است.»
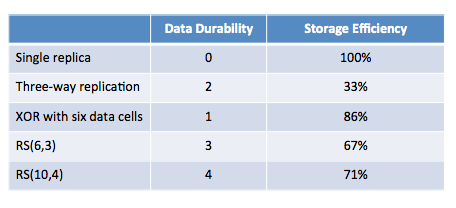
کدگذاری رید-سالامون را به اختصار به صورت RS نشان می دهیم و از پراستفاده ترین الگوریتم های کدگذاری رید-سالامون در هدوپ، به ترکیب RS(6,3) و RS(10,4) می توان اشاره کرد که در آن، پارامتر اول تعداد بلاک های داده و پارامتر دوم، تعداد بلاک های توازن (تصحیح خطا) است. در حالت کلی کدگذاری RS(k,m) می تواند تا m بلاک را در صورت حذف یا از دست رفتن، بازیابی کند. میزان استفاده موثر از فضای ذخیره سازی (یعنی حجمی که به داده ها اختصاص دارد)، از فرمول زیر قابل محاسبه است :

پیکربندی های معمول رید-سالامون یعنی RS (6,3) and RS (10,4) در مقایسه با روش تکرار داده ها، هم استفاده موثرتری از فضای ذخیره سازی انجام میدهند و هم تا سه و چهار خطای پیش آمده در بلاک های داده را می توانند به راحتی تصحیح کنند . مقایسه کاملتر روشهای ذخیره سازی از لحاظ بهینه سازی فضا و میزان تحمل خطا (یا پایداری داده : durability) در جدول زیر صورت گرفته است (منبع ):
برای کدگذاری داده ها به روش اریژر، دو رهیافت اصلی خواهیم داشت :
- کدگذاری پیوسته یا کذگذاری هر بلاک از فایل
- کدگذاری نواری (stripe)
در روش اول، هر فایل به چندین بلاک بزرگ تقسیم شده و هر بلاک، کدگذاری می شود .
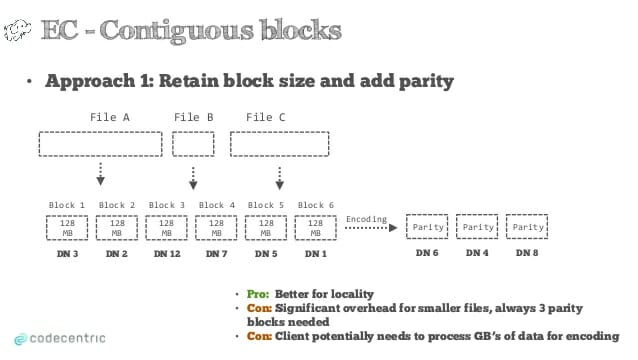
همانطور که از شکل فوق مشخص است، داده ها در بلاک هایی با اندازه زیاد مانند ۱۲۸ مگابایت ذخیره می گردندو هر بلاک هم درون یک DataNode (DN) قرار می گیرد. به ازای هر بلاک داده، بسته به نوع کدگذاری رید-سالامون، تعدادی بلاک توازن هم همزمان ایجاد و ذخیره می گردد. این روش، محلی بودن داده ها را تضمین می کند یعنی داده های یک فایل معمولاً کنار هم ذخیره می شوند و کارآیی خواندن و نوشتن سریال داده ها بالا می رود اما از آنجا که در روش های فایلینگ، شروع هر فایل از یک بلاک جدید صورت میگیرد، سربار سیستم برای فایلهای کوچک بسیار زیاد خواهد بود. چون به ازای هر فایل کوچک هم به چندین بلاک توازن نیاز خواهیم داشت و خود بلاک های داده هم فضای خالی زیادی را شامل خواهند شد.
از طرفی کدگذاری هر بلاک، نیاز به چندین بلاک مجاور دارد که گاها به چندین گیگابایت داده خواهد رسید و منابع زیادی از سیستم برای کدگذاری و کدگشایی مصرف خواهد شد.
در روش تقسیم نواری، یک فایل به بخش های کوچکی تقسیم می شود (حدود یک مگابایت) و مبنای کدگذاری، این بخش های کوچک که به آنها سلول میگوییم، خواهد بود و هر سلول در یک گره داده مجزا (Data Node) ذخیره خواهد شد. هر نوار (stripe) شامل بخش های داده ای و بخش های توازن متناظر خواهد بود. (شکل زیر)
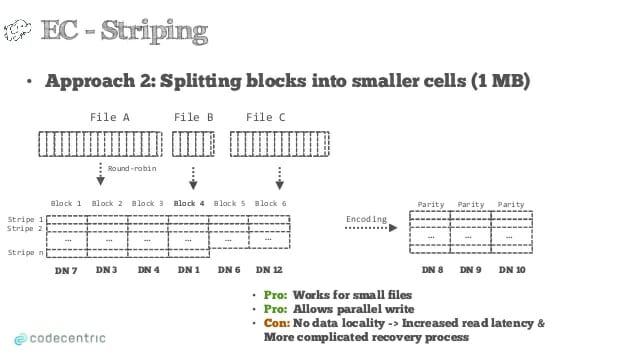
این روش برای فایلهای کوچک بسیار خوب عمل می کند و نوشتن موازی و همزمان یک فایل را هم ممکن می سازد چون هر بخش در یک گره داده در شبکه باید ذخیره شود و امکان ارسال همزمان بخشهای مختلف یک فایل برای ذخیره به سیستم های مختلف فراهم است. اما مشکل بزرگ این روش، از بین رفتن خاصیت محلی بودن داده هاست یعنی اگر یک برنامه به داده های مجاور هم نیاز داشته باشد، در بسیاری از اوقات باید منتظر خواندن آنها از گره های مختلف در شبکه باشد که باعث افزایش تاخیر و انتظار در عملیات خواندن فایل خواهد شد. از طرفی اگر اشکالی در یک گره داده در شبکه ایجاد شود و آن گره از دسترس خارج یا داده های آن حذف گردد، با توجه به اینکه بخش های زیادی از فایلهای مختلف در آن ذخیره شده است، عملیات بازسازی بلاک ها بسیار شبکه را درگیر خواهد کرد.
بنابراین روش کدگذاری اریژر، باعث بهره وری فضای دیسک می گردد اما سرعت خواندن و نوشتن اطلاعات را تحت تاثیر قرار خواهد داد.
جدول زیر این مزایا و معایب را به صورت یکجا نمایش می دهد :
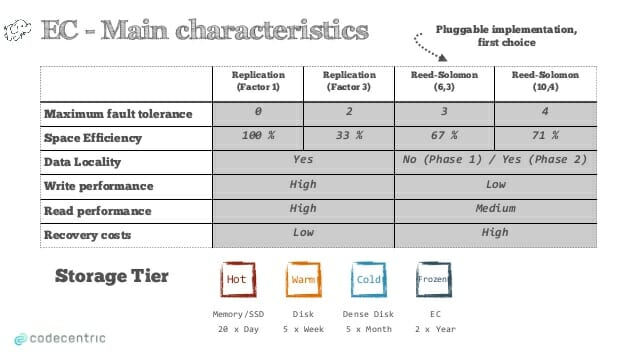
پیشنهاد می شود که برای داده های عملیاتی و داده هایی که در حال تغییر مداوم آنها هستید از روشهای دیگر ذخیره سازی استفاده کنید و برای داده های زمانمند و آرشیوی (Frozen) از کدگذاری اریژر استفاده شود.
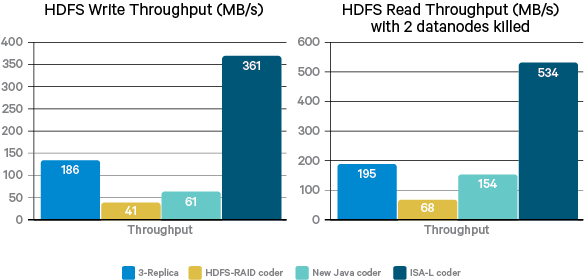
البته اینتل کتابخانه ای برای کدگذاری و کدگشایی اریژر با نام ISA-L ایجاد کرده است که کارآیی بسیار بالایی را هنگام کدگذاری و کدگشایی اریژر از خود نشان داده است و می توان در سیستم های عملیاتی هم از این کدگذاری استفاده کرد، هر چند مباحث لوکالیتی و سایر معایب این روش هم باید در نظر گرفته شود :
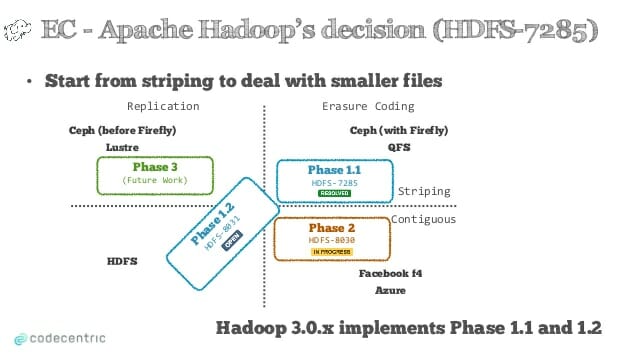
در حال حاضر تنها از کدگذاری نواری در HDFS پشتیبانی می شود اما در آینده ای نزدیک می توان بسته به نوع کاربرد و اندازه فایلها، استراتژی مناسب را اتخاذ کرد (شکل زیر ) :
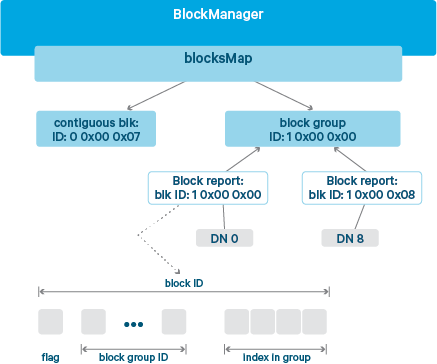
در روش ذخیره سازی نواری، واحد آدرس دهی فایل ها از بلاک به سلول تغییر پیدا می کند و چون هر بخش از یک فایل در یک سلول ذخیره شده است، تعداد واحدهای مورد نیاز برای آدرس دهی افزایش پیدا می کند و گره مدیر نام (NameNode) نیاز به حافظه بسیار بیشتری برای نگهداری آدرس تک تک این سلول ها خواهد داشت. برای رفع این مشکل، هدوپ ۳ از پروتکل نامگذاری سلسله مراتبی استفاده می کند (Hierarchical block naming protocol) که در آن هر چندین بلاک که شامل بلاک های داده و توازن متناظر با هم دیگر هستند، یک گروه بلاک را تشکیل می دهند و هر بلاک درون این گروه که بلاک داخلی نامیده میشود، یک اندیس و شماره منحصر بفرد با شروع از عدد صفر دارند. شکل زیر یک گروه بلاک را نشان می دهد که شامل نه بلاک داخلی است (RS(6,3))

آدرس هر سلول از سه قسمت اصلی تشکیل می شود : شناسه گروه بلاک، اندیس بلاک داخلی حاوی سلول و نهایتاً شماره یا اندیس خود سلول درون بلاک .
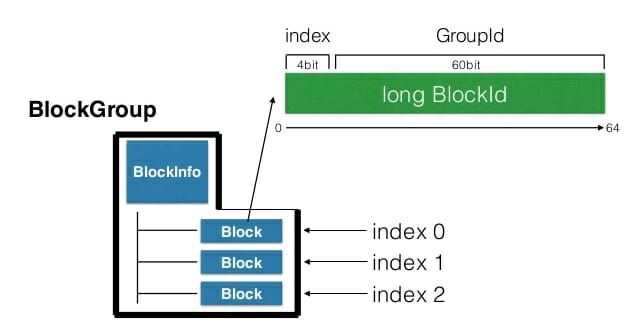
برای صرفه جویی در مصرف حافظه، کافیست که آدرس گروه بلاک در حافظه گره مدیر نام ذخیره گردد و سایر اطلاعات مورد نیاز برای دسترسی به هر سلول از خود آدرس درخواست شده، قابل محاسبه خواهد بود :
برای آگاهی از تغییرات انجام شده در پشت صحنه هدوپ برای پشتیبانی از کدگذاری اریژر و آشنا شدن با روند جدید خواندن و نوشتن در HDFS به این مقاله مراجعه کنید.
به جای عنوان نگاهی به تغییرات هدوپ در ورژن ۳ عنوان مقاله را به کدگذاری اریژر در هدوپ ۳ تغییر دهید
وقتی می گویید نگاهی به تغییرات … این انتظار می رود که لیست از ۵ یا ۶ تغییر با خلاصه توضیحی داده شده باشد نه اینکه همش در مورد کدگذاری صحبت شده باشد.
ممنون از دقت نظر و وقتی که برای ارسال نظر گذاشته اید. عنوان متن شامل عبارت بخش ۱ هست و انشالله تا پایان هفته بخش دوم و نهایی که شامل سایر تغییراتی که در ابتدای این مقاله فهرست شده اند، آماده و بر روی سایت قرار خواهد گرفت