
اسپارک : موتور نوین پردازش کلان داده
چند صباحیست که در دنیای کلان داده، سامانه پردازش جدیدی پا به عرصه وجود نهاده است با نام اسپارک که امروزه یکی از فعالترین پروژه های بنیاد آپاچی است. تا قبل از اسپارک، برای پردازش حجم عظیم داده ها از هدوپ به صورت معمول استفاده میشد و همانطور که احتمالاً آشنا هستید در مدل پردازشی هدوپ، داده ها در کل شبکه یا کلاستر توسط سیستم فایل HDFS توزیع میشوند و برای پردازش داده ها از مکانیزم نگاشت و تجمیع (MapReduce) استفاده می شود یعنی پردازش مورد نیاز بر روی داده ها مثلا آمارگیری یا یافتن یک الگوی خاص در متن به هر نود محاسباتی ارسال میشود (عمل نگاشت یا Map) و روی هر سیستم فایلهای داده ای پردازش شده و نتایج به شکل استاندارد در آمده و به یک نود محاسباتی دیگر برای تجمیع (Reduce) ارسال میشود. این عمل با تجمیع تمام نتایج در یک نود و نمایش آن به کاربر به پایان می رسد. این مدل، برای بیش از ده سال، رایجترین مدل پردازشی کلان داده و مبتنی بر اکوسیستم هدوپ بوده است .
در سال ۲۰۰۹ دانشگاه برکلی مدلی جدید برای پردازش کلان داده با نام اسپارک ارائه داد که تمرکز آن بر روی انجام محاسبات درون حافظه ای بود یعنی تا حد امکان و با وجود ظرفیت رم دستگاه، محاسبات درون حافظه انجام میشود. این امر باعث می شود سرعت پردازش داده ها نسبت به هدوپ معمولی در پردازش های دیسک محور تا ده برابر و در پردازش های درون حافظه ای تا صد برابر افزایش پیدا کند که خود بهبود بسیار زیادی را نشان می دهد و برای الگوریتم های تکرار شونده بسیار عالی عمل می کند.
مزیت دیگر اسپارک، پشتیبانی آن از انواع توابع مورد نیاز برای پردازش داده ها مانند مرتب سازی، فیلتر کردن، انجام یک تابع روی تک تک عناصر لیست، شمارش عناصر و …. است که کار برنامه نویس را بسیار ساده می کند.
RDD : مجموعه داده های توزیع شده برگشت پذیر
نقطه قوت اصلی اسپارک استفاده از مجموعه داده های توزیع شده برگشت پذیر یا RDD است. تمام داده ها در اسپارک برای پردازش باید به شکل RDD در آیند که البته به کمک توابع خود اسپارک این امر به راحتی امکان پذیر است . RDD ها فقط خواندنی هستند و با هر تراکنش جدیدی که روی یک مجموعه داده برگشت پذیر انجام میشود یک RDD جدید ساخته می شود و محاسبات با این مجموعه جدید ادامه پیدا می کند. دو نوع کار می توان روی این مجموعه داده ها انجام داد :
- تبدیلات : عمل تبدیل یک RDD را به یک RDD جدید تبدیل می کند. مانند فیلتر کردن و انجام یک تابع سراسری روی تک تک عناصر (map)
- عملیات : منظور از عملیات، توابعی است که روی یک RDD اعمال میشود و یک مقدار را بر می گرداند. مثلا شمارش عناصر، بیشینه یا کمینه عناصر
نکته مهم در مورد اسپارک این است که هر RDD اشاره گری به مجموعه داده پدر خود به همراه عمل انجام گرفته برای تبدیل را داراست و برگشت پذیر بودن این مجموعه ها هم دقیقاً به همین روال اشاره دارد چون با داشتن مجموعه داده اولیه و مجموعه تبدیلات انجام گرفته روی آن،می توان به راحتی یک مجموعه را از پایه دوباره ساخت و اگر سیستم به هر دلیلی مجموعه داده فعلی خود را از دست داد، به راحتی آنرا با پیمایش زنجیره تبدیلات از اولین مجموعه تا الان، می تواند بازیابی کند بنابراین RDD ها برگشت پذیر هستند.
نکته دیگر در باره RDD ها اینکه تا عملیاتی روی این مجموعه ها صورت نگیرد (توابع عملیاتی صدا زده نشوند) عملاً تبدیلی هم انجام نمی شود یعنی تبدیلها زمانی انجام میشوند و مجموعه های جدید را تولید می کنند که یکی از توابع عملیاتی روی آنها صدا زده شوند.
به مثال زیر که به زبان پایتون نوشته شده است نگاه کنید :
[cc_python]
text_file = spark.textFile(“hdfs://…”)
errors = text_file.filter(lambda line: “ERROR” in line)
# Count all the errors
errors.count()
# Count errors mentioning MySQL
errors.filter(lambda line: “MySQL” in line).count()
# Fetch the MySQL errors as an array of strings
errors.filter(lambda line: “MySQL” in line).collect()
[/cc_python]
در خط اول به کمک کتابخانه اصلی اسپارک اولین RDD با خواندن یک فایل متن در حافظه ایجاد میشود. خط دوم ، روی RDD اول خطوطی را می یابد که در آنها کلمه ERROR به کار رفته است . با این توصیف، متغیر errors یک RDD جدید است .
در دستور سوم، یک عملیات روی خطاها صورت می گیرد و خطاها شمرده می شود. در دستور چهارم ، در مجموعه برگشت پذیر errors خطوطی جدا می شوند که کلمه MySQL در آن به کار رفته باشد و یک RDD بی نام جدید شکل می گیرد که در انتهای دستور، تابع شمارش روی آن صدا زده می شود و خروجی یک عدد خواهد بود .
در خط چهارم هم مجدداً RDD مرحله قبل تولید شده و تابع عملیاتی collect روی آن صدا زده میشود و تمام خطاها به صورت یک رشته به کاربر برگشت داده میشود. البته می توان با دستور cache این مجموعه های برگشت پذیر را یک باز ذخیره کرد تا برای دفعات بعد، تولید RDD ها از ابتدا صورت نگیرد.
معماری اسپارک
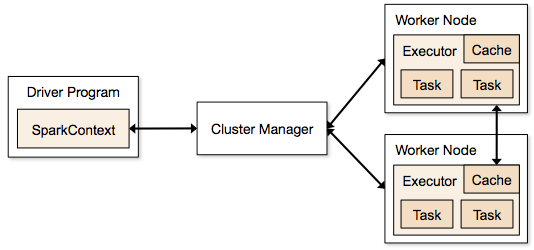
برای آشنایی بیشتر با اسپارک بهتر است نگاهی به معماری آن هم بیندازیم . شکل زیر اجزای تشکیل دهنده اسپارک را در یک کلاستر نمایش می دهند.
همانطور که می بینید، اصلی ترین مولفه اسپارک برنامه راه انداز (Driver) است که اجرای عملیات بر روی RDD ها را بین شبکه توزیع کرده و نتایج را دریافت می کند.
برنامه راه انداز از طریق مولفه مدیریت کلاستر، با رایانه ها و گره های محاسباتی شکبه ارتباط برقرار می کند. هر گره محاسباتی که به آنها گره های کاری (Worker Node) می گوییم، از دو بخش مدیریت حافظه و اجراکننده تشکیل شده است که اجراکننده، وظیفه انجام پردازش ها را روی RDD ها برعهده دارد.
برگشت پذیری و تحمل خطا
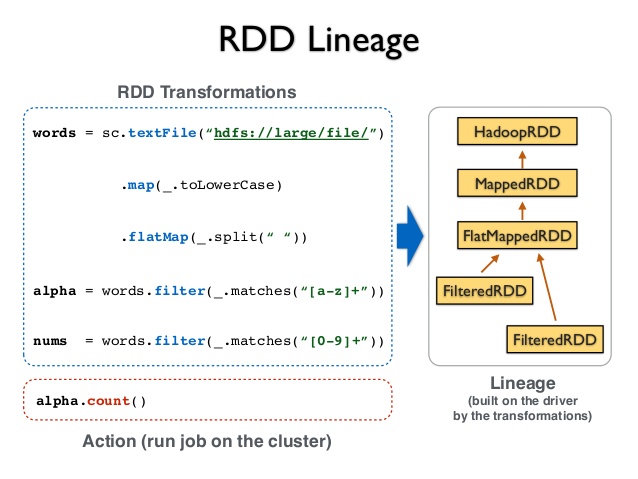
برای توضیح مکانیزم برگشت پذیری و تحمل خطا در اسپارک ، مثال زیر را که یک کد اسکالا برای شمارش کلمات در اسپارک است را در نظر بگیرید :

در این مثال در خط اول یک RDD پایه (ساخته شده از روی یک منبع داده اصلی ) ساخته می شود. در خط دوم تا چهارم ، سه عدد RDD جدید به کمک تبدیلات از روی مجموعه های قبلی ساخته می شود. در خط پنجم، عملیات collectAsMap روی مجموعه برگشت پذیر counts صدا زده میشود. در اینجا، برنامه راه انداز یک گراف جهت دار بدون حلقه (DAG) از RDD ها و نحوه ارتباطاتشان (RDD Lineage) می سازد که در آن هر RDD با عمل تبدیل و مجموعه برگشت پذیر پدر شناخته می شود.
حال این گراف جهت دار توسط راه انداز به تمام نودهای شبکه ارسال می شود و هرگره محاسباتی، این گراف وظایف را به مجموعه ای از کارهای کوچکتر (به چند مرحله یا Stage) تقسیم کرده و به همراه مرحله فعلی کار، به اجراکننده ها تحویل میدهد. اجرا کننده ها ها هم با در نظر گرفتن مرحله فعلی گراف، از RDD تحویل گرفته در این مرحله شروع کرده، به ترتیب تمام تبدیلات را روی آن انجام میدهند تا تمام کارهای یک مرحله انجام شود و نتیجه را تحویل می دهند تا مرحله بعد از کار شروع شود و نهایتاً به عملیات مورد نظر (دراینجا collectAsMap ) برسند و نتیجه را به برنامه راه انداز ارسال کنند.
در هر مرحله اگر اشکالی در کار پیش آمد، می توان از روی این گراف جهت دار، مجموعه های برگشت پذیر را از اول ساخت . برای افزایش کارآیی سیستم هم میتوان به ازای هر چند عمل تبدیل، نتیجه را در حافظه یا دیسک ذخیره کرد ویک نقطه کنترل(Check Point) ایجاد کرد که درصورت وجود خطا، از این نقطه کار ادامه پیدا کند و نیاز به محاسبه از اول نباشد.
مثالی دیگر از گراف وظایف که نقش اصلی را در تقسیم وظایف و برگشت پذیری RDD ها در اسپارک دارد را در شکل زیر می توانید ببینید :
هدوپ یا اسپارک ؟
سوالی که به غلط مطرح میشود این است که امروزه از اسپارک استفاده کنیم یا هدوپ ؟ و جواب این است که اسپارک هم می تواند در هدوپ مورد استفاده قرار گیرد و داده های خود را از HDFS بخواند و در آن هم ذخیره کند و برای مدیریت کلاستر یا شبکه هم از YARN کمک بگیرد. یعنی از سه بخش اصلی تشکیل دهنده اکوسیستم هدوپ، یعنی بخش ذخیره سازی توزیع شده ، اجرای توزیع شده و مدیریت شبکه تنها در بخش اجرای توزیع شده هدوپ، اسپارک جای نگاشت و تجمیع(MapReduce ) را می گیرد. . یعنی این دو تا مدل پردازشی مکمل هم هستند و می توانیم اسپارک را به یک اسب و هدوپ و مکانیزم نگاشت و تجمیع آنرا به یک فیل تشبیه کنیم که درست است که اسب همه جا سریعتر از فیل حرکت می کند اما گاهی اوقات ما به قدرت فیل نیاز داریم مثلاً اگر حجم داده ها بالا و میزان حافظه ما کم باشد، شاید همان مکانیزم نگاشت و تجمیع برایمان مناسب تر باشد .
آینده اسپارک :
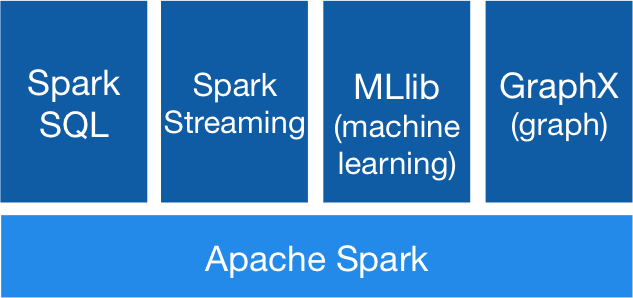
امروزه اسپارک به سرعت در حال گسترش در جوامع آکادمیک و تجاری دنیاست و روی آن، چهار کتابخانه مهم ساخته شده است شامل SQL روی اسپارک، کار با داده های گراف ، یادگیری ماشین و پردازش داده های جریانی که پشته اسپارک را امروزه شکل داده اند و تقریبا تمام نیازهای پردازشی یک مهندس داده روی حجم عظیم داده ها با اسپارک قابل پاسخگویی است .
رقبای اسپارک در دنیای کلان داده :
یکی دیگر از پروزه های سطح بالای آپاچی، پروژه فلینک است (Flink) که دقیقاً ماموریتی مشابه با اسپارک در اکوسیستم هدوپ دارد و به عنوان جایگزین مدل نگاشت و تجمیع هدوپ معرفی شده است .
این پروژه که بسیاری از مفاهیم آن شبیه اسپارک است (مثلا به جای RDD ما در فلینک مجموعه داده داریم که عملیات مختلفی روی آنها انجام می گیرد و مجموعه داده جدید تولید میشود و یا مشابه با اسپارک می توان اس کیو ال ،گراف ، یادگیری ماشین و پردازش جریان هم با آن انجام داد)، ترکیبی از دیسک محور بودن نگاشت و تجمیع و حافظه محور بودن اسپارک را در بردارد و نتایج پردازش توزیع شده با فلینک در بعضی مسائل ، کارآیی بیشتر فلینک را نسبت به اسپارک نشان می دهد.
از جمله مزایای فلینک نسبت به اسپارک می توان به موارد زیر اشاره کرد :
- ماهیت خط لوله ای آن در پردازش داده ها و انتخاب بهینه ترین روش انجام این خط لوله توسط فلینک
- مدیریت مناسب تر حافظه
- کاملا بلادرنگ در مقایسه با مدل شبه بلادرنگ در اسپارک (در اسپارک ما micro batch داریم و رخدادها به صورت مجموعه ای پردازش می شوند و تک تک وارد مرحله تحلیل نمی شوند.)
- کارآیی مناسب تر برای پردازش های تکراری
- امکان اجرای پردازش های کلاسیک نگاشت و تجمیع و امکان تلفیق با آپاچی TEZ
به نظر می رسد فلینک هم با توجه به مزایایی که دارد در آینده رقیبی جدی برای اسپارک خواهد بود ….
شروع کار با اسپارک
توصیه می کنم برای شروع کار با اسپارک از کتابخانه PySpark در پایتون استفاده کنید که برای یادگیری و شروع کار نسبت به اسکالا و جاوا ساده تر خواهد بود . بخصوص اینکه اگر از IPython (کتابچه های پایتون که به آنها اسناد قابل اجرا هم می گویند و ترکیبی از متن و توضیحات، کدهای پایتون و خروجی آنها و گرافیک است ) هم استفاده کنید، مراحل یادگیری و آموزش خودتان را می توانید با توضیحات مناسب برای مراجعه بعدی یا استفاده سایرین ذخیره کنید .
البته جدیداً پروژه ای در بنیاد آپاچی در مرحله رشد مقدماتی پذیرفته شده است با نام زپلین (Zepelin) که یک سیستم مشابه IPython بر روی بستر جاوا برای انجام پردازش های تعاملی با اسپارک است که با نصب آن روی سیستم خودتان، می توانید کدهای اسپارک را با زبانهای اسکالا ،پایتون ،جاوا و … وارد کرده و خروجی ها را به صورت لحظه ای مشاهده و نتایج را ذخیره کنید.
سلام علیکم،
اگه امکان داره در مورد برگشتپذیری آردیدیها بیشتر توضیح بدین.
مخصوصاً این قسمت از متن که نوشتین « با هر تراکنش جدیدی که روی یک مجموعه داده برگشت پذیر انجام میشود یک RDD جدید ساخته می شود و محاسبات با این مجموعه جدید ادامه پیدا می کند. »
اگه با مثال این موضوع رو توضیح بدین، ممنون میشم.
با سلام.
قطعه کدی که با پایتون در متن آورده ام دقیقاً با همین هدف آورده شده است که با یک مثال عملی این مفهوم توضیح داده شود. اگر مثال گویا نیست یا جایی ابهام دارد بفرمایید که شفاف سازی شود.
مثالتون در مورد برگشتپذیری گویا نیست. در این مثال دارین توضیح میدین که چطور میشه روی آردیدیها فیلتر و کانت و کالکت و اینها زد. خب اینها که مشخصه. همچنین مشخصه که کجاها آردیدی جدیدی تولید میشن. اما سؤال من اینه که برگشتپذیری یعنی چی؟ اگه یه آردیدی برگشتپذیر نباشه چه اتفاقاتی ممکنه بیفته؟ و …
با سلام مجدد.
متن را ویرایش کردم و بخش بازگشت پذیری و تحمل خطا را به آن اضافه کردم . اگر جایی ابهام داشت بفرمایید تا اصلاح شود.