
آشنایی با OpenRefine- ابزاری برای پیش پردازش و پاکسازی داده ها – بخش اول
همانطور که میدانید یکی از وقت گیر ترین کارها در عملیات پردازش داده و ساخت مدلهای یادگیری ماشین روی آنها، پاکسازی و پیش پردازش داده هاست. این آموزش به معرفی نرم افزار OpenRefine که قبلاً با نام Google Refine شناخته میشد، به عنوان یکی از ابزارهای متن باز پاکسازی و پیش پردازش داده ها می پردازد .
برای این منظور امروزه نرم افزارهای بسیار زیاد و گاهاً رایگان و متن بازی هم وجود دارند که از بین آنها می توان به Talend data Preparation و Trifacta اشاره کرد اما سادگی، کم حجم بودن و عدم محدودیت در تعداد رکوردها و اجرای مبتنی بر مرورگر، آنرا به یکی از ابزارهای مناسب برای عملیات پاکسازی و تبدیل نوع و قالب داده ها تبدیل کرده است. در این آموزش قصد داریم به کمک یک مثال ساده، قابلیت های این نرم افزار را با هم مرور کنیم .
نصب و راه اندازی OpenRefine
از سایت رسمی OpenRefine، آخرین نسخه آنرا بارگذاری کرده و از حالت زیپ خارج کنید . با کلیک بر روی openrefine.exe نرم افزار اجرا شده و پنجره مرورگر با آدرس http://127.0.0.1:3333 باز خواهد شد.
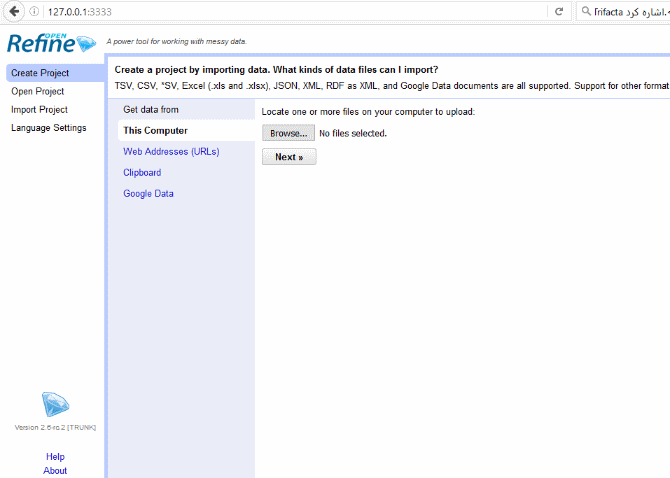
تهیه داده های مورد نیاز
در این آموزش، می خواهیم با بررسی داده های ویکی پدیای دانشگاه های جهان،ارتباط بین تعداد دانشجو و میزان جذب کمک های مردمی را در آنها بررسی کنیم و نتابج را به صورت گرافیکی نمایش دهیم . داده ها را از این آدرس، بارگیری (دانلود) کنید. درون این فایل زیپ، فایلی با نام universityData.csv وجود دارد. آنرا از حالت زیپ خارج کنید تا برای مراحل بعد، آماده باشد. (این داده ها از کجا به دست آمده است؟)
داده های استخراج شده از دانشگاه ها، ایرادات کوچک و نیاز به رفعی دارند که در انتهای این آموزش، تمام آنها را برطرف کرده، روابط بین داده ها را نمایش داده و از نقشه برای جانمایی دانشگاه ها استفاده خواهیم کرد.
برخی از ایراداتی که باید رفع شوند از قرار زیر است :
- ایرادات املایی و ناسازگاری داده های همسان مانند USA,U.S.A,US,United States که همه باید به یک مقدار تبدیل شوند.
- نمایش داده های عددی به صورت متنی مثلاً ۱۲۳Milion باید به ۱۲۳٫۰۰۰٫۰۰۰ تبدیل شود.
- استخراج و اصلاح داده های زمان و تاریخ . مثلاً ساعت و زمان از تاریخها حذف شود.
- حذف سطرهای تکراری
بارگذاری داده ها و ساخت پروژه
از آدرس Create Project->Get Data From -> This Computer گزینه Choose File را انتخاب کنید. آدرس فایلی که در مرحله قبل دانلود کرده اید را در این بخش وارد کنید و گزینه Next را بزنید. (شکل زیر)
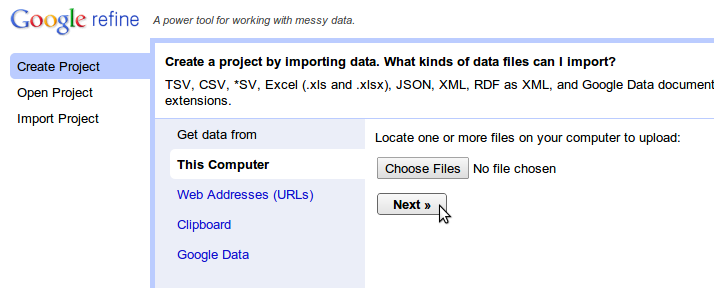
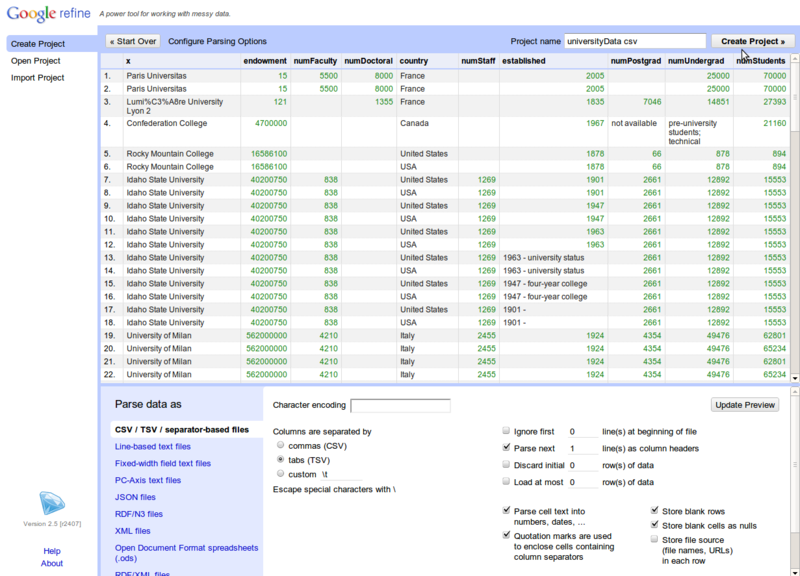
داده ها باید بدون اشکال خوانده شده و در صفحه بعد، گام آخر بارگذاری داده ها نمایش داده شود : تنظیماتی مانند نوع فایل، تعداد سطرهایی که از اول فایل باید جاگذاشته شوند، نام پروژه و مانند آن .
یادتان نرود که گزینه Parse cell text into numbers, dates, etc را حتماً تیک بزنید که تا حد امکان OpenRefine از روی داده ها، نوع آنها را حدس بزند. با زدن دکمه Create Projet این مرحله به اتمام خواهد رسید و اکنون آماده پردازش اولیه داده ها هستید. این داده ها باید ۷۵۰۴۳ سطر باشند.
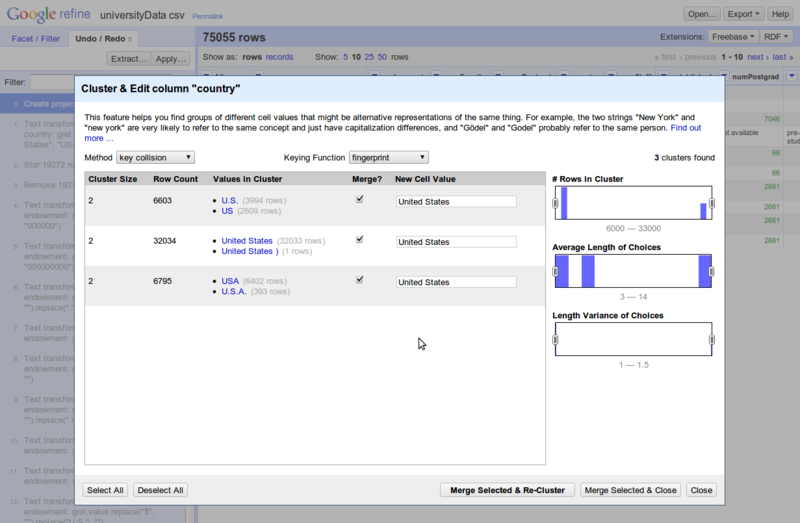
یکسان سازی نام کشورها
اکنون که داده ها بارگیری شده اند، می توانید یک نگاه سرسری به داده ها بیندازید تا با کلیت کار آشنا شوید. برای اولین کار، به ستون Country که حاوی نام کشورهاست یک نگاه بیندازید. همانطور که می بینید کشور آمریکا با دونام United States و USA ذخیره شده است که باید اصلاح شود. این امر ممکن است برای بقیه کشورها هم اتفاق افتاده باشد.
برای اینکار،گزینه ای داریم به نام Cluster & Edit که مقادیر داده ها را بر اساس الگوریتم هایی که پارامترهای آنها هم توسط کاربر قابل تغییر است، بررسی کرده و آنهایی که تاحدودی بهم شبیه هستند را به ما اعلام می کند و می توانیم آنها را ویرایش کرده ، یکسان سازی لازم را انجام دهیم. روی ستون Country کلیک کنید و از منوی Edit Cells این گزینه را پیدا کرده و آنرا انتخاب کنید . همانطور که در زیر می بینید سه گروه مختلف از داده هایی که کشور آنها آمریکاست اما املای متفاوتی دارند، توسط این نرم افزار شناسایی شده است. مقدار همه اینها را United States بگذارید، تیک Merge یا ادغام را زده و گزینه Merge Selected & Re-Cluster را انتخاب کنید. اکنون این داده ها یکسان سازی شدند اما هنوز یک مشکل دیگر در داده های کشور آمریکا وجود دارد (۶۱۵ سطر حاوی مقدار United States of America هستند!) و سایر کشورها هم نیاز به اصلاح دارند (Rossija و Russia باید یکسان شوند) که کافیست وقتی وارد این صفحه شدید، سایر الگوریتم ها و توابع مقایسه داده ها را هم بررسی کنید.
تمیزکاری تعداد دانشجویان
ستون تعداد دانشجویان ، نیاز به کمی اصلاح دارد چون در بعضی سطرها، کنار مقدار عددی آن مقدار رشته ای و غیر عددی هم قرار گرفته است که باید تمیزکاری شود. برای یافتن این که چه سطرهایی باید اصلاح شوند، از Numerical Facets استفاده می کنیم. (Facet به معنای وجه، منظر و شکل است). روی ستون numStudents کلیک کرده ، Facet و سپس Numerical Facet را انتخاب کنید. (مطابق شکل زیر)
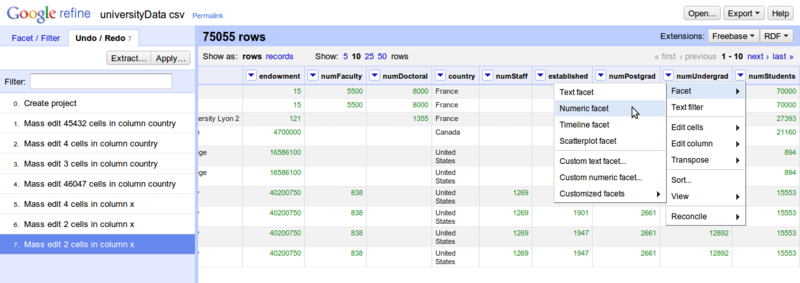
دقت کنید که بعد از انتخاب گزینه Numerical Facets از منوی سمت چپ، فقط تیک Non Numeric را بزنید که فقط داده های غیر عددی در ستون numStudents نمایش داده شود.
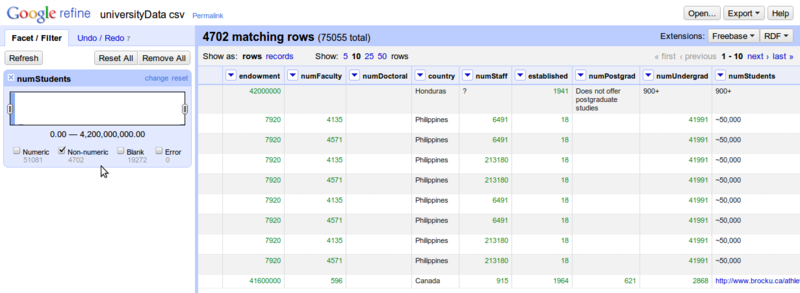
با اینکار، فقط سطرهایی با مقادیر غیر عددی نمایش داده می شوند که به ترتیب شروع به اصلاح آنها می کنیم. در مرحله اول، مقادیر ~ یا + و – را از این داده ها حذف می کنیم. روی ستون numStudents کلیک کرده، گزینه Edit Cells و بعد گزینه Transform… را انتخاب می کنیم .
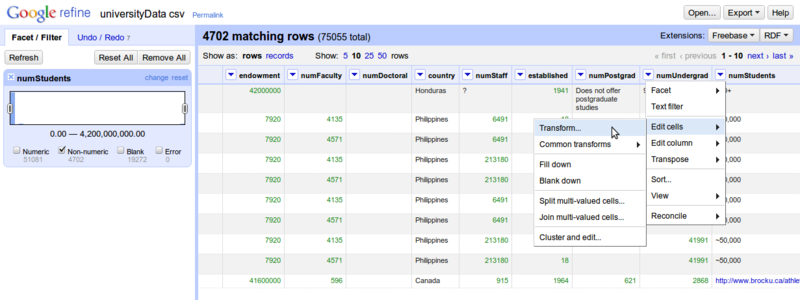
با انتخاب گزینه Transform صفحه زیر ظاهر خواهد شد :
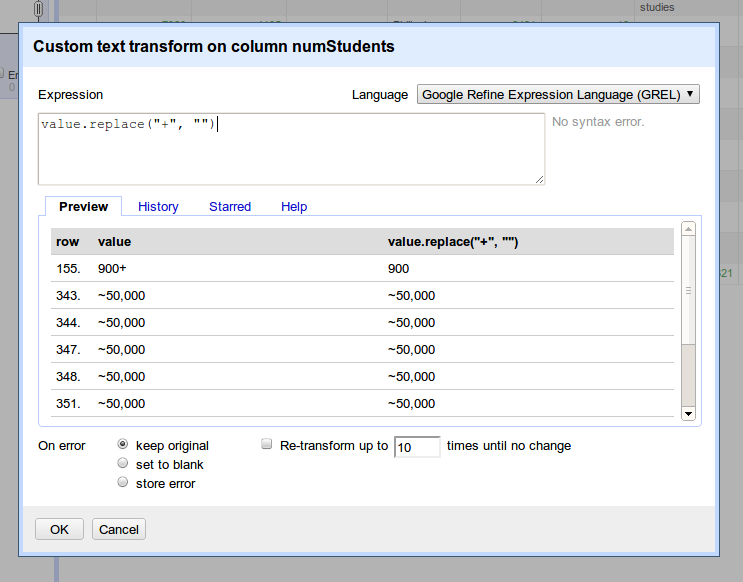
در این مرحله باید کمی دست به کد شوید و به کمک توابعی که جزئی از General Refine Expression Language یا زبان عمومی توصیف OpenRefine هستند، این مقادیر را اصلاح کنید. برای شروع این مقدار را وارد کنید :
value.replace("+","")
که درون مقادیر ستون انتخاب شده، تمام + ها را با رشته خالی جایگزین میکند (به عبارتی آنها را حذف می کند) . می توانید این عمل را به صورت زنجیره ای و در یک دستور انجام دهید تا مجبور نشوید برای هر جایگزینی ساده این مسیر را از اول طی کنید :
value.replace("-","").replace("~","").replace(",","").replace("total","")
قبل از ادامه کار به لیست توابع مورد نیاز برای اصلاح رشته ها حتماً یک نگاه بیندازید . این توابع ، قدرت مانور بسیار زیادی را روی داده ها به شما می دهند . مثلاً خیلی از داده های استخراج شده از اینترنت، حاوی رشته هایی شبیه به این هستند : Lumi%C3%A8re University Lyon 2 که با تابع
value.unescape('url')
به راحتی اصلاح و به شکل مناسب ( “Lumière University Lyon 2”) در خواهند آمد.
بعد از انجام هر تمیزکاری، برای حذف داده های اصلاح شده، از تبدیلات مناسبی باید استفاده کنید تا بتوانید به سایر مشکلات برسید. در این مثال و در این مرحله، داده هایی که اصلاح شده اند، هنوز در قالب متن هستند و باید به عدد تبدیل شوند. هر چند توابع تبدیل متن به عدد هم موجود هستند (value.toNumber) اما راحت تر این است که با کلیک بر روی numStudents گزینه Edit Cells ، گزینه Common Transforms ، گزینه To number را انتخاب کنید تا داده های عددی شما از فیلتر Non-Numeric Facet شما حذف شوند و بتوانید سایر مشکلات را بررسی کنید.
برای بقیه اصلاحات، شما احتمالاً نیاز به استفاده از توابع Regex خواهید داشت که در بین داده های رشته ای، اعداد را یافته و آنها را با کل رشته، جایگزین کند. در ادامه آموزش با این توابع تا حدودی آشنا خواهیم شد اما برای ادامه کار، می خواهیم تمام سطرهایی که داده های غیرعددی و نیز خالی (Blank) برای تعداد دانشجویان خود دارند، حذف شوند. بنابراین ابتدا از سمت چپ،گزینه Blank را هم تیک بزنید .
حال برای حذف تمام داده های فیلتر شده، روی ستون اول که نام ALL دارد،کلیک کنید و All -> Edit rows -> Remove all matching rows را بزنید . (مطابق شکل زیر )
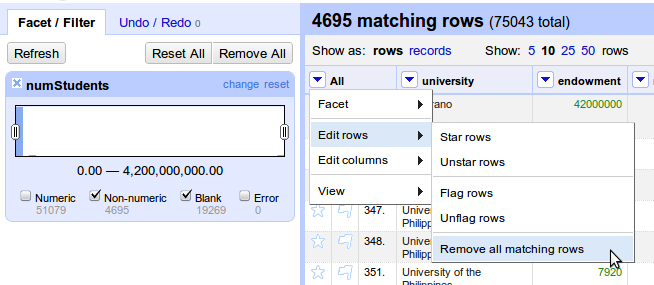
بعد ازاین کار، تعداد داده های حذف شده به شما نمایش داده خواهد شد و هیچ سطری هم نخواهید دید. از تب یا زبانه Facet/Filter ، گزینه Remove All را بزنید تا تمام فیلترها حذف شده و مجدداً داده های اصلی به شما نمایش داده شوند.
تا اینجا با اصول کلی کار با OpenRefine آشنا شدیم . در بخش دوم و پایانی این آموزش، مطالب پیشرفته تر آنرا با هم مرور خواهیم کرد.