
Import.io + OpenRefine + Google Fusion Tables = یک مثال عملی جادویی
در ادامه آموزشهای کاربردی در زمینه جمع آوری، پردازش و نمایش داده ها، در این مقاله، با یک مثال ساده تمام این مراحل را با هم انجام خواهیم داد. داده هایی را از وب سایت داده های آزاد شهر اتاوای کانادا با استفاده از نرم افزار ارائه شده در سایت import.io استخراج می کنیم، با OpenRefine آنها را پاکسازی و با امکانات (جداول ترکیبی گوگل) Google Fusion tables آنها را نمایش خواهیم داد. امیدواریم این آموزش الهام بخش کاوش ها و آزمایش های بیشتر برای شما دوستان باشد.
مقدمه: شروع کار با import.io
در این نوشتار ما از ابزار ارائه شده در وبسایت import.io جهت استخراج اطلاعات وب سایت های اطلاعاتی استفاده خواهیم کرد. برای کار با import.io می توانید از دو نسخه ی آنلاین و دسکتاپ این محصول استفاده کنید. وب سایت ارائه دهنده محصول، خدماتش را در حال حاضر به صورت سرویسی و آنلاین ارائه می کند که شما می توانید از طریق ثبت نام در سایت از امکانات آن بهره مند شوید. اما نسخه ویندوزی آن که دیگر پشتیبانی نمیشود، از طریق نسخه های پیشین هنوز قابل استفاده است (نسخه پیشین از طریق سایر وب سایت ها قابل دسترسی است) و نسبت به نسخه ی آنلاین دارای امکانات بیشتری می باشد. در نسخه آنلاین شما قادر به استخراج داده به صورت معمول هستید اما در نسخه ویندوزی محصول شما می توانید از Crawler و سایر خدمات نرم افزار بهره مند شوید. ما هم این اموزش را بر اساس نسخه ویندوزی این نرم افزار ساده و کاربردی نوشتیم. در اولین گام بایستی نسخه ویندوزی نرم افزار import.io را از اینجا دانلود و نصب کنید.
پس از نصب نرم افزار و اجرای آن، شما قادر به مشاهده محیط زیر خواهید بود.

برای شروع کار، بر روی دکمه صورتی رنگ new در بالای صفحه کلیک کرده و اولین API را بسازید.
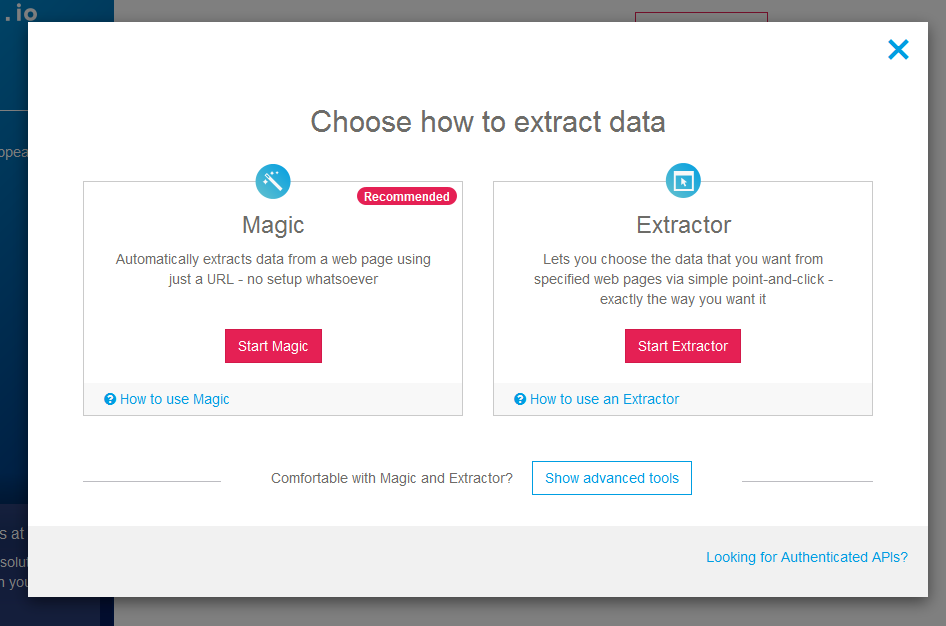
برنامه import مشابه یک مرورگر عمل می کند. شما می توانید آدرس صفحه مدنظر خود را وارد کرده و داده های آن را استخراج نمایید. در این صفحه، مطابق تصویر بالا دو انتخاب داریم. با انتخاب حالت magic شما می توانید به صورت خودکار داده های یک آدرس وب را بدون نیاز به هیچگونه تنظیماتی استخراج نمایید. در صورت انتخاب Extractor شما می توانید داده هایی که قصد استخراج انها را دارید از میان چندین صفحه وب انتخاب کنید و این کار تنها با انجام چند کلیک امکان پذیر است.
چنانچه شما بر روی گزینه ی show advance tools کلیک کنید دو گزینه دیگر نیز به انتخاب های شما افزوده می شود. با انتخاب Crawler شما قادرید یک خزنده وب طراحی کنید یعنی الگویی را ایجاد کنید و این ابزار تمام صفحات سایت که مشابه با الگوی شما باشند مثلا تمام اخبار، تمام کالاها و …. را برای شما جستجو و اطلاعات آنها را طبق الگوی شما برایتان استخراج کند. حتی اگر آدرس تمام صفحات وب سایت مدنظر را نداشته باشید.
با انتخاب connector با استفاده از یک macro ، به شما اجازه ی ذخیره سازی عملیات را به صورت متوالی به شما میدهد برای مثال می توانید ابتدا داخل یک وب جستجو کنید و بعد اطلاعات یافت شده را پردازش کنید. این ماکرو همین روال را فراخواهد گرفت و به جای شما، عمل جستجو و استخراج را انجام خواهد داد. در این آموزش ما از Crawler استفاده خواهیم کرد. برای آشنایی با نحوه استفاده از سایر ابزارها به این آدرس مراجعه کنید.
مرحله ۱: دریافت داده ها
در این آموزش ما از فهرست داده های آزاد شهر اوتاوا به عنوان منبعی برای به دست آوردن داده ها استفاده می کنیم. یعنی می خواهیم یک بررسی سریع روی خود مجموعه داده ها انجام دهیم و ببینیم که چه قالبهایی برای نمایش داده ها در این مجموعه ها استفاده شده اند و ارتباطات بین مجموعه داده ها چگونه است و این اطلاعات را در یک نمودار با بقیه به اشتراگ بگذاریم. از آنجایی که ما می خواهیم داده ها را از صفحات مشابه در همین وب سایت جمع آوری کنیم، از Crawler استفاده خواهیم کرد. (آموزش ایجاد یک Crawler)
پس از اینکه آدرس داده های مدنظر را در نوار آدرس Crawler وارد کردیم و تنظیمات لازم را روی خزنده وب ایجاد شده انجام دادیم، می توانیم آنها را در یک فایل ذخیره نماییم. به صورت کلی می توان گفت پس از انتخاب crawler در import.io و درج آدرس داده ها در نوار ابزار بایستی گزینه ی I’m Here را انتخاب نمایید تا عملیات کاوش در سایت آغاز شود. با انتخاب گزینه ی Detect Optimal Settings، موارد اضافی مانند جاوا اسکریپت در سایت غیر فعال خواهد شد تا به روال استخراج سرعت ببخشیم. در صورتی که پس از اعمال این تغییر داده های مدنظرتان در صفحه قابل مشاهده نباشد در پنجره انتخاب گزینه No را انتخاب کنید تا به تنظیمات قبل برگردید. در غیر اینصورت Yes را انتخاب کنید. در گام بعد چنانچه داده های شما به صورت سطر به سطر در هر پیج وجود داشته باشند مثلا یک محصول در هر صفحه، شما بایستی از گزینه ی single row استفاده کنید و در صورتی که هر سطر حاوی چندین موجودیت باشد بایستی از گزینه ی Multiple Rows استفاده کنید. در گام بعد روال کار بسیار ساده و دلچسب است. به راحتی سطر و ستون یکی از داده ها را تعیین کنید و پس از آن نرم افزار تمام سطر و ستون های دیگر را یافته و در جدولی در اختیار شما قرار می دهد برای آشنایی به نحوه اجرای Crawler به لینک ذکر شده در بالا برای این ابزار مراجعه نمایید.
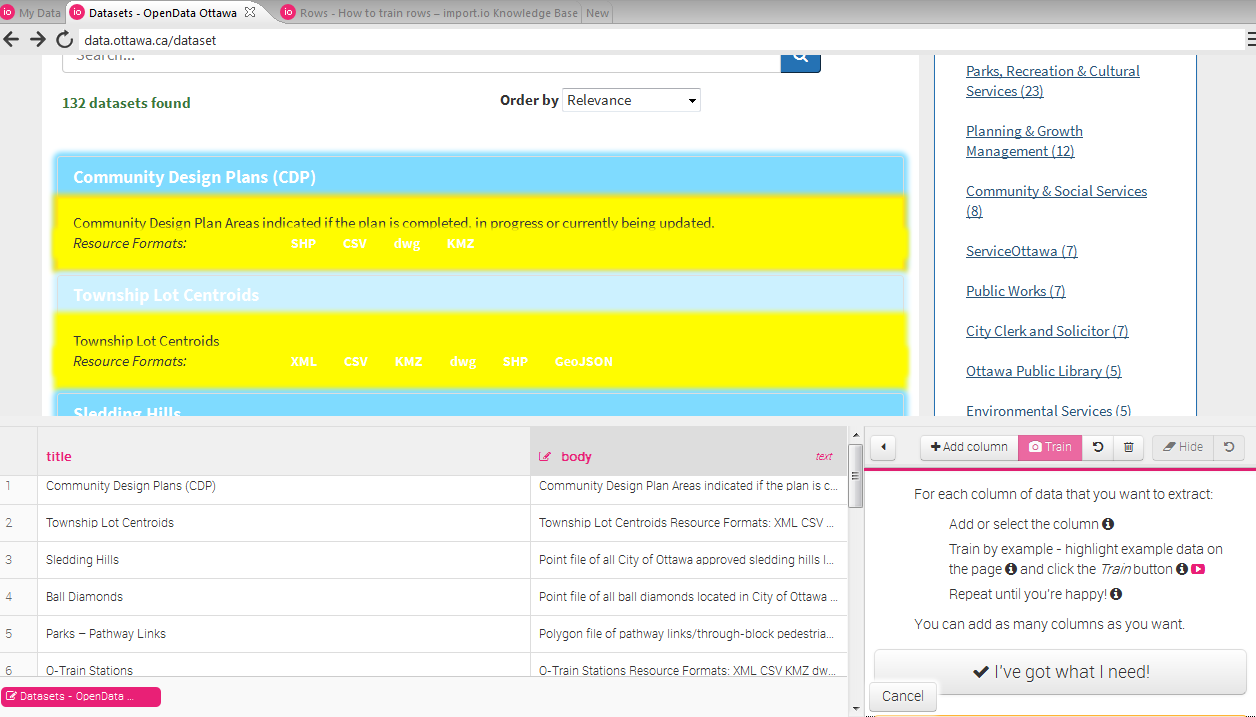
نکته قابل توجه این است که import.io پیش نمایش داده های جمع آوری شده را در قسمت پایین صفحه نمایش نشان می دهد. شما می توانید مطمئن باشید که اطلاعات صحیح ، در فرمت درست جمع آوری شده است.
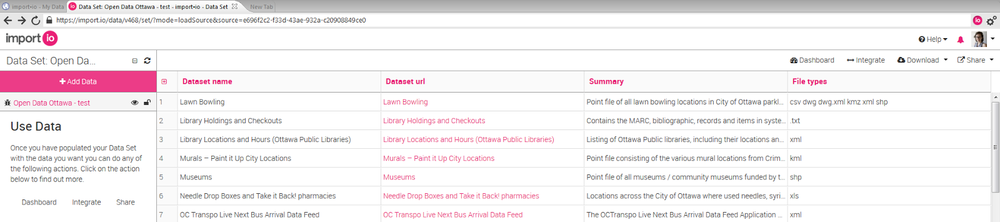
زمانی که داده ها استخراج شدند، از داده ها به صورت یک فایل csv خروجی می گیریم و به انتخاب بهترین تنظیمات ممکن برای شکل دهی به داده ها برای با ارزش کردن آنها فکر می کنیم. برای شروع، هر ستون غیر ضروری( مطابق با اهدافمان) که در فرآیند دانلود اضافه شده است را حذف می کنیم. برای مثال ستون های غیرضروری widgetName و source. پس از مشاهده فایل، متوجه می شویم که در داده های جمع آوری شده برخی تناقضات وجود دارد. به عنوان مثال، فایل های متنی با هر دو شکل .txt و txt و فایل های xml در دو شکل متفاوت با حروف کوچک و حروف بزرگ نمایش داده می شوند. همچنین بعضی تکرار ها وجود دارد که ما تصمیم به حذف آنها داریم.
مرحله ۲: پاک سازی داده ها
در این بخش از openRefine برای پاکسازی انواع داده ها استفاده می کنیم. به وسیله openRefine می توان تغییرات خاص را ایجاد کرد و یا داده ها را گروه بندی نموده و بروزرسانی را در ابعاد بزرگ انجام داد. برای این آموزش، ما به مرور برخی از تبدیلات رایج در دسترس می پردازیم. برای این کار بر روی فلش پایین عنوان ستون مورد علاقه خود کلیک می کنیم. برخی تبدیلاتی که ما بر روی فایل import.io استفاده کردیم در زیر بیان می شود:
- Edit cells > common transformations > to lowercase
- Edit cells > split multi-valued cells (جداسازی روی فضای خالی به صورت دوره ای)
- Edit cells > commons transformations > trim leading and trailing whitespace
- Edit cells > fill down
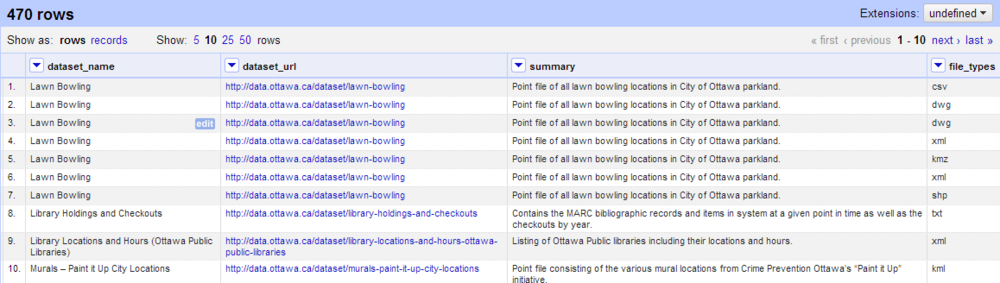
البته، عملیاتی که شما انتخاب می کنید به کاری که قصد انجام آن را بر روی مجموعه داده خود دارید بستگی دارد. اینکه بخواهید یک تصویر از داده ها بسازید یا به سادگی داده های پاکسازی شده را برای دسترسی دیگران قرار دهید؟ هنگامی که شما داده ها را در openRefine پاکسازی می کنید، شما می توانید آن را در هر فرمتی دانلود کنید. با استفاده از آموزش OpenRefine که در سایت قرار گرفته است، داده ها را تا حد ممکن پاکسازی و یکدست کنید.
مرحله ۳: تصویرسازی داده ها
پرشی به گوگل درایو داشته باشید و این صفحه را برای یادگیری بیشتر درباره جداول ترکیبی گوگل بررسی نمایید. (آدرس آموزش کار با جداول ترکیبی).
بر روی create کلیک کرده و more apps را انتخاب کنید سپس fusion Tables را اضافه نمایید. بعد از آن شما می توانید با کلیک بر روی create و fusion tables نوع فایل را انتخاب کنید. جهت دسترسی سریع به بخش fusion tables می توانید از اینجا اقدام نمایید. و سپس بر رویcreate a fusion table کلیک نموده و فایل دانلود شده از openRefine را انتخاب و آپلود کنید. به این دلیل از دستور command Edit cells > split multi-valued cells در openRefine استفاده می کنیم زیرا ما قصد داشتیم تا براساس نوع فایل هر مجموعه ی سازمان یافته را با یک نمودار شبکه نمایش دهیم. در جداول ترکیبی گوگل یک ابزار قوی برای این کار وجود دارد که به طور کامل با روشی که ما پاکسازی داده ها را انجام داده ایم کار می کند. برای ایجاد یک نمودار شبکه با جداول ترکیبی، بر روی علامت بعلاوه ی باکس قرمز رنگ، در پنل بالا کلیک کرده و یک نمودار جدید را اضافه می کنیم.
در نهایت این چیزی ست که شما دریافت و مشاهده می کنید.
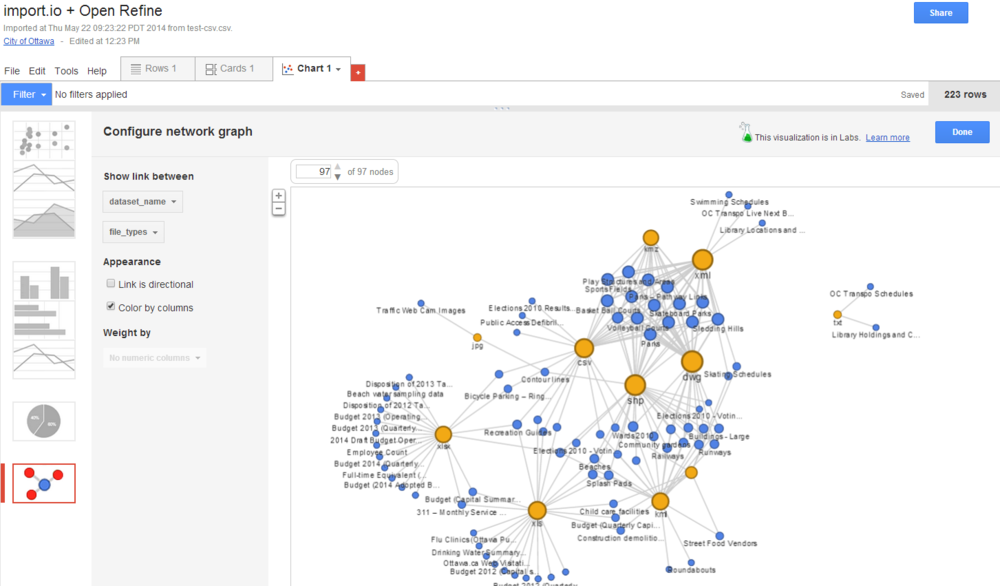
هدف ما در اینجا نمایش اتصال بین نام مجموعه داده و انواع فایل ها است. بنابراین این دو ستون را در سمت چپ انتخاب می کنیم. ما همچنین برای برجسته تر کردن مقایسه با انتخاب گزینه ی Color by column به ستون ها رنگ می دهیم.
و این همه کاری ست که باید انجام دهیم. شما می توانید تصویر سازیی که انجام داده اید را در وب سایت خود قرار دهید و از طریق انتخاب tools > publish آن را به دوستانتان نمایش بدهید. برای مشاهده جداول ترکیبی و جستجوی تصویر شبکه ی مربوط به این آموزش می توانید به اینجا مراجعه نمایید.