معیارهایی برای انتخاب نوع فایل در پردازشهای کلان داده
مقدمه
بعد از حدود ۱۳ سال از معرفی هدوپ به عنوان اولین سامانه عمومی پردازش کلان داده، این اکوسیستم به بلوغ رسیده است به گونهای که امروز با معرفی نسخه ۳ هدوپ، بسیاری از اشکالات و نواقص آن برطرف شده است. در این بین، نحوه ذخیره فایلها در اکوسیستم هدوپ هم بسیار متنوع شده است و برای سامانه های تحلیلی امروزی، آشنایی با قالب فایلهای موجود و معایب و مزایای هر کدام، یک ضرورت است. توضیح اینکه برای پردازش انبوه دادهها (batch)، هدوپ از سه مولفه اصلی زیر تشکیل شده است:
- سیستم فایل توزیع شده (HDFS)
- مدیریت تخصیص و پایش مداوم منابع مانند پردازنده، هارد، حافظه و مانند آنکه باید به صورت توزیع شده مدیریت شود (YARN)
- بخش پردازش و تحلیل اطلاعات (توزیع و تجمیع – Map/Reduce)
که در این مقاله به بخش اول آن یعنی نحوه ذخیره فایلها خواهیم پرداخت .روش سنتی و معمول، ذخیره فایلها به صورت متنی درون HDFS است که هم توزیع شدگی دادهها را تضمین می کند و هم خوانایی دادهها در آن محفوظ میماند به گونهای که انواع سامانههای پردازشی و ابزارهای کلان داده، می توانند مستقیماً با این فایلها ارتباط برقرار کنند. رایجترین این نوع از فایلها، فایلهای CSV یا فایلهایی هستند که دادههای یک رکورد را درون یک خط به گونهای ذخیره میکنند که بین هر فیلد یک ویرگول (یا یک جداکننده استانداراد) قرار گیرد.
ذخیره متنی دادهها درون فایلها، حتی با وجود ایجاد ساختارهای درختی و پوشه بندی درست درون HDFS، یافتن یک داده خاص یا جستجوی موردی را زمان بر میکند چون هیچ گونه ایندکسی روی دادهها نداریم و باید تک تک رکوردها برای یافتن یک داده خاص جستجو شوند. برای حل مشکل سرعت جستجوی یک داده خاص یا پرس و جوهای موردی (Ad-Hoc)، معمولاً سراغ بانکهای اطلاعاتی توزیع شده و ستون گرا مانند HBase و کاساندرا میرویم. این کار، پردازش انبوه دادهها را تحت الشعاع قرار میدهد و استخراج اطلاعات تحلیلی مانند میانگین فروش ماهیانه و هفتگی، تعداد ویزیتها، سفارشها و کنسلیهای یک محصول، با این دیتابیسها به دلیل ساختار خاص مدلسازی دادهها در آنها، به سرعت امکان پذیر نیست.
مشکل دیگری که ذخیره داده ها در فایل های متنی دارد، حجم بالاییست که آنها اشغال می کنند و اگر بتوان آنها را به نحوی فشرده کرد، حجم عظیمی از دیسک، صرفه جویی خواهد شد. البته منظور ما فشرده سازی معمول متن (که آنهم البته مفید است اما بار اضافی بر دوش استفاده کنندگان از سیستم می گذارد که برای هر کاری، ابتدا باید داده ها را از حالت زیپ خارج کنند و سپس آنها را پردازش کنند) نیست بلکه فشرده سازی بر اساس نوع داده های ذخیره شده است مثلاً اگر بدانیم فیلد دوم داده ها یک فیلد عددیست آنرا به صورت باینری ذخیره می کنیم و اگر بدانیم یک فیلد متنی مانند نام محصول است، از کدگذاریهای بهینه متن برای ذخیره آن استفاده خواهیم کرد.
با این مقدمه، از آنجا که قالب فایل و نوع ذخیره داده ها، در سرعت و بهره وری پردازش آنها بسیار موثر است، قالب های مختلفی در سالهای اخیر برای ذخیره موثر فایلها در اکوسیستم بیگ دیتا پیشنهاد شده است و حتی اکثر سامانه های پردازشی مانند هدوپ، اسپارک و فلینک، امکان خواندن مستقیم داده از این قالبها را برای کاربران فراهم کرده اند. هدف اصلی این قالب های فایل، کاهش حجم داده ها و بهینه سازی عملیات آماری در عین حفظ سرعت مناسب جستجوی یک قلم داده خاص است.
در ادامه مقاله، ابتدا به معرفی قالب های ذخیره سازی ستونی می پردازیم و سپس ضمن معرفی قالب فایلهای نوین،نقاط ضعف و قوت هریک و نتایج تستهای صورت گرفته روی آنها را جداگانه مورد بررسی قرار خواهیم داد.
قالب های ستونی ذخیره داده ها
در پردازش های انبوه و هنگام نیاز به تحلیل های آماری داده ها، معمولاً به یک فیلد خاص از داده ها نیاز داریم . به عنوان مثال اگر میانگین فروش سه ماهه محصولات را بخواهیم به دست آوریم، تنها به فیلد فروش داده ها (علاوه بر کد محصول و زمان فروش) نیاز داریم. بنابراین برای امور تحلیل داده، شاید بهتر باشد داده ها به جای سطری به صورت ستونی و موضوع محور، ذخیره شوند. یعنی به جای اینکه داده های یک شخص یا محصول خاص کنار هم ذخیره شود، میزان فروش این محصول در یک بازه زمانی ، میزان بازدید یک محصول در روزهای ماه های سال و مانند آن، کنار هم ذخیره شوند که بتوان به سرعت به آنها دسترسی داشت و اطلاعات آماری مورد نیاز را سریعاً به دست آورد. شکل زیر به خوبی تفاوت روش سطری و ستونی داده ها را نمایش می دهد :
![]()
در دو مقاله معرفی Kudu و آشنایی با Apache Arrow در مورد فلسفه داده های ستونی با ذکر شکل های مربوطه صحبت کرده ایم که می توانید به آنها نیز رجوع کنید. به طور خلاصه، هدف از ذخیره داده ها به صورت ستونی، آماده کردن آنها برای استخراج اطلاعات آماری و تحلیلی است که البته با تمرکز روی هر ستون به دلیل نوع داده مشخصی که دارد، فشرده سازی داده ها بسیار موثرتر می تواند صورت گیرد.
![]()
فرض کنید می خواهیم به پرس و جوی زیر پاسخ دهیم یعنی می خواهیم تمام اطلاعات تعدادی از کاربران سایت را نمایش دهیم :
Select * from USERS where user_id in (Some_arbitrary_list_of_users);
در روش ستونی، پاسخگویی به این کوئری، بسیار زمان بر است چون داده های مربوط به هر فرد در بلاکهای مختلفی در سیستم فایل ذخیره شده است. برای رفع این مشکل، در قالب های جدید ذخیره فایل ستونی، هم از ایندکس گذاری داده ها استفاده کرده اند و هم اجازه داده اند که چندین ستون، کنار هم ذخیره شود که به این ترتیب داده های مرتبط با یک ستون، کنار آن موجود باشد. از جمله اولین قالبهای فایلی که این امکان را فراهم کرد، Parquet بود. معرفی Apache Parquet و بهره وری مناسب آن، به رواج این نوع از قالبهای فایل، بسیار کمک کرد.
نکته دیگری که باید در مورد قالبهای فایل اشاره کنیم، مکانیزم نوشتن در فایل آنهاست. اکثر قالبهای ستونی و به صورت عمومی زمانی که با حجم عظیم داده ها سروکار داریم، نوشتن در فایل به صورت Append-Only یا همان «نوشتن در انتها» است که باعث می شود سرعت نوشتن در فایل بسیار بالا باشد چون همیشه در بافر فایل ما می تویسیم و سرفرصت این داده ها به دیسک منتقل می شوند اما برای به روزرسانی یا حذف داده از این فایلها، معمولاً بازنویسی کامل فایل از ابتدا تا انتها باید انجام پذیرد که خود عملی زمان بر و مصرف کننده منابع سیستم است .
قالبهای ذخیره فایل غیر متنی
فهرستی از قالبهای نوین فایل که می تواند در پروژه های کلان داده شما به کار برود، در زیر به صورت مختصر تهیه شده است :
Apache Avro
این قالب فایل که جزء ساده ترین قالبهای موجود با محبوبیت زیاد است، یک قالب ستونی نیست بلکه تنها یک موتور فشرده سازی بسیار خوب و با قابلیت حفظ مدل داده های ماست. اگر بخواهیم دقیق تر صحبت کنیم، Avro یک پروتکل ذخیره باینری داده هاست (Data Serialization) که در اصل برای انتقال داده ابداع شده است اما می توان برای ذخیره داده ها هم از آن استفاده کرد.
اگر قصد دارید داده های خود را به صورت JSON در هدوپ ذخیره کنید که بعدها به راحتی بتوانید داده ها را ویرایش کرده و تغییر دهید، Avro مناسب کار شماست. البته در مقایسه با قالب های فایل ستونی، میزان فشرده سازی آن کمتر است اما قابلیت انعطاف پذیری زیادی را به شما هدیه می کند.
ضعف اصلی این قالب فایل هم، سطری بودن داده ها در آن است که برای تحلیل های داده که معمولاً روی یک ستون خاص تمرکز دارد، غیربهینه و کند است.
Apache Parquet
این قالب فایل بر خلاف Avro، با هدف افزایش سرعت جستجو و کاهش زمان مراجعه به دیسک طراحی شده است. Parquet که امروزه محبوب ترین و رایج ترین قالب ستونی ذخیره اطلاعات به حساب می آید، با نوع داده های مشخص و محدود خود، فرآیند فشرده سازی را تسهیل می کند و از طرفی برای افزایش بازدهی پرس و جوهای تحلیلی، اجازه ذخیره چندین نوع داده را در یک ستون به ما می دهد. مثلاً می توانید علاوه بر نام محصول، گروه و تاریخ فروش آنرا هم در یک ستون ذخیره کنید تا فیلتر کردن شما بر اساس گروه و بازه زمانی معین، بتواند به سرعت و بدون مراجعه به ستون های دیگر، قابل انجام باشد.
Optimized Row Columnar (ORC)
در سال ۲۰۱۳ برای افزایش بازدهی Hive که یکی از ابزار پرکاربرد حوزه کلان داده است، قالبی ستونی با قابلیت ایندکس زنی داده ها و نیز پشتیبانی از ACID (برای اجرای تراکنش ها ) ابداع شد با نام ORC که امروزه جزء پروژه های بنیاد Apache هم قرار گرفته است. این قالب فایل، مشابه پارکت (Parquet)، نوع داده های از پیش تعیین شده ای را برای ذخیره داده ها پیشنهاد می کند و بنابراین با انتخاب انکودینگ مناسب برای هر نوع داده،میزان فشرده سازی بسیار خوبی دارد . پشتیبانی از داده های جریانی و کش سمت کلاینت هم از دیگر مزیت های این قالب فایل است.
در این مقاله که به بررسی مقایسه ای دو قالب ستونی ORC و پارکت پرداخت است، تفاوت معناداری بین این دو گزارش نشده است و فقط برای کوئری هایی که فیلترهای مختلف را روی داده ها اعمال می کنند، سرعت پاسخگویی ORC به دلیل ساختار ایندکس گذاری مناسب که نیاز به خواندن کل فایل را از بین می برد، بیشتر ذکر شده است.
این فرمت بسیار جدید که توسط شرکت هواوی ابداع و اکنون جزء زیرمجموعه های آپاچی قرار گرفته است، علاوه بر اینکه یک قالب ستونی است، با ساختار بسیار حرفه ای ایندکس زنی خود، برای جستجوهای موردی روی داده ها هم بسیار مناسب است یعنی یک قالب ترکیبی موثر و کارآ.
![]()
این قالب فایل از ACID پشتیبانی نمی کند اما امکان حذف و به روزرسانی داده ها و نیز بخش بندی مناسب داده ها توسط آن که سرعت جستجوی و پویش را بسیار بالا می برد، از جمله نقاط قوت آن است. امکان به روز رسانی و حذف داده ها به صورت بهینه برای قالب های فایل استفاده کننده از مکانیزم «نوشتن در انتها» بسیار حیاتی است چون در دنیای واقعی معمولاً به این موضوع نیاز خواهید داشت (Kudu هم البته این قابلیت را دارد). البته بخاطر داشته باشید که برای ذخیره لاگ ها و رخدادهایی که به صورت مداوم در حال تولید هستند، ما نیاز به تغییر و حذف داده ها نداریم یعنی همه جا هم نمی توان روی این قابلیت، مانور داد.
ایندکس گذاری چندلایه داده ها در Carbondata که در آن، کل فایل، هر بخش و نیز مقدار ماکزیمم و می نیمم هر ستون، جداگانه ایندکس می شود، باعث افزایش سرعت جستجوی داده ها شده است.
![]()
دو نقطه ضعفی که می توان برای این قالب جدید و خوش آتیه هدوپ و کلان داده، برشمرد، یکی میزان فشرده سازی کمتر آن نسبت به ORC و پارکت (که البته به خاطر ایندکس گذاری چند لایه آن قابل توجیه است) و دومی هم جدید بودن آن و عدم پشتیبانی از آن در حال حاضر توسط بسیاری از پروژه های کلان داده بنیاد آپاچی است.
Apache Kudu
کیودو که یک قالب ذخیره جدولی و توزیع شده داده هاست، اجازه ذخیره و بازیابی سریع داده ها را شبیه به بانکهای اطلاعاتی به ما میدهد. این قالب فایل که کمی جاافتاده تر از Carbondata است، امکان بروز رسانی داده ها را هم مشابه آن، فراهم می کند و برای کارهای ترکیبی پردازش داده ، بسیار مناسب عمل می کند.
![]()
برای آشنایی دقیق تر با معماری این قالب فایل، می توانید به این مقاله از سایت مهندسی داده، مراجعه کنید.
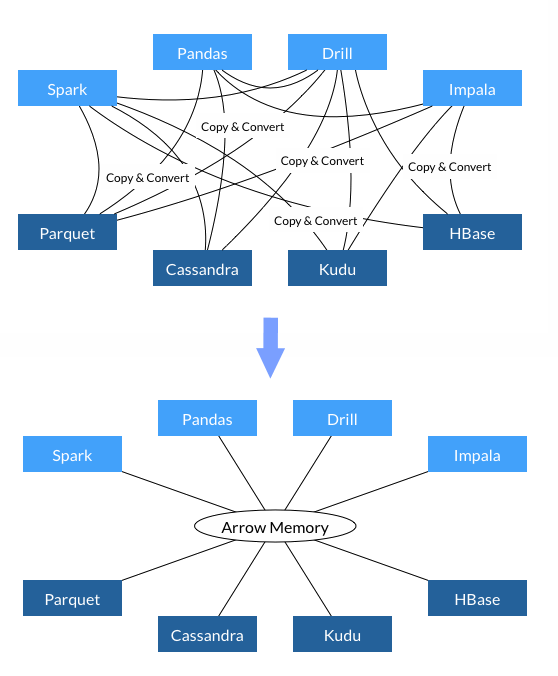
Apache Arrow
از آنجا که قالبهای فایل مختلفی در اکوسیستم کلان داده وجود دارد، نیاز به مکانیزمی برای استاندارد شدن اتصال به انواع منابع داده ای تحلیلی وجود داشت که باعث شد پروژه Arrow، پا به عرصه وجود نهد. این پروژه با هدف یکسان سازی قالب نمایش داده ها در حافظه توسعه داده شده است و به عنوان یک واسط یا اینترفیس مابین ابزارهای پردازش داده و قالب های ذخیره فایل قرار می گیرد.
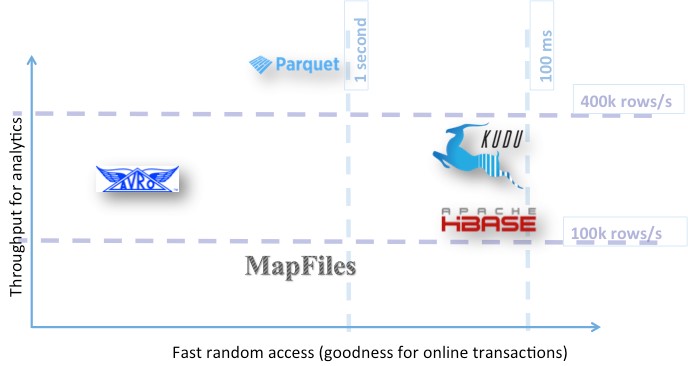
مقایسه و نتیجه گیری
یک مقایسه کامل و همه جانبه که تمام فرمت های فوق را دربر داشته باشد، پیدا نکردم اما در مقاله «کدامین قالب فایل هدوپ را باید به کار ببریم؟» ، جدول زیر به عنوان نتیجه بحث پیشنهاد شده است :
![]()
در مقاله دومی که با نام «مقایسه میزان کارآیی قالب فایلها و موتورهای ذخیره سازی اکو سیستم هدوپ» برای انتخاب فرمت فایل مناسب در پروژه عظیم شتابدهنده CERN به بررسی دقیق تر این قالبها از طریق انجام تستهای گوناگون، پرداخته بود، نتایج زیر به دست آمده است که برای علاقه مندان می تواند مفید باشد و برای اخذ تصمیم مناسب به آنها کمک کند. هر چند این نتایج بر روی داده های به کار رفته در مقاله، به دست آمده است و برای داده های مختلف می تواند تا حدودی متفاوت باشد و باید دقیق تر بررسی شود.
میزان بهره وری از فضای ذخیره سازی
با دو نوع الگوریتم فشرده سازی Snappy و GZip نتایج زیر به دست آمده است :
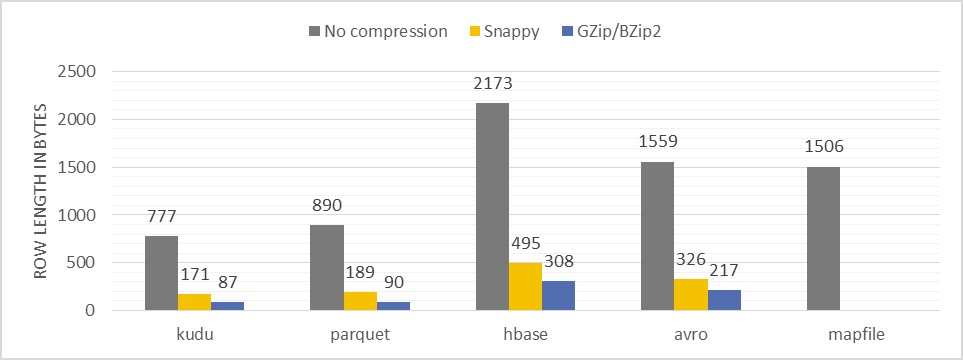
Description of the test: Measuring the average record size after storing the same data sets (millions of records) using different techniques and compressions
سرعت درج اطلاعات
میزان ورود داده و سرعت نوشتن نیز از دیگر پارامترهای مورد بررسی بوده است :
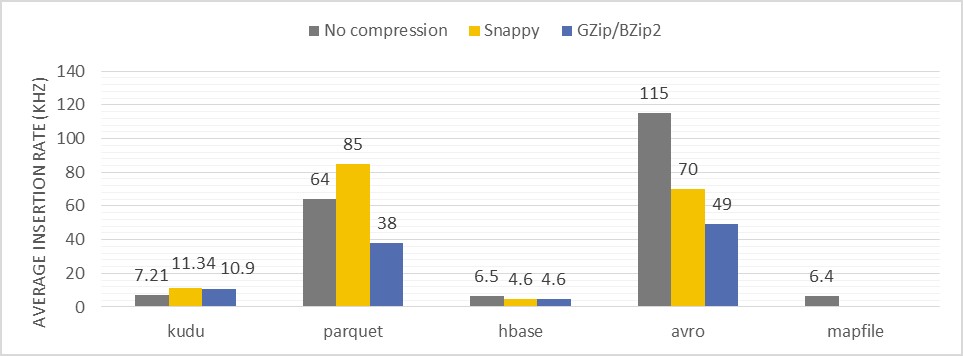
Description of the test: Measuring of records ingestion speed into a single data partition
دسترسی تصادفی به یک داده
سرعت جستجوی موردی یک داده خاص در دیتاست هم از معیارهای مهم انتخاب قالب فایل است که نتایج زیر در این خصوص به دست آمده است :
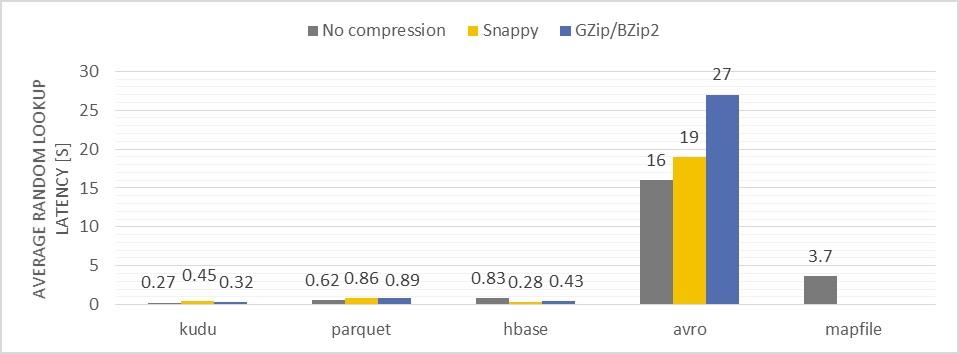
Description of the test: Retrieving a non-key attribute from a record by providing a record identifier (a compound key)
خواندن انبوه اطلاعات
خواندن پشت سرهم اطلاعات برای استخراج آمارهای مختلف، از دیگر پارامترهای تست شده در این آزمایش است :
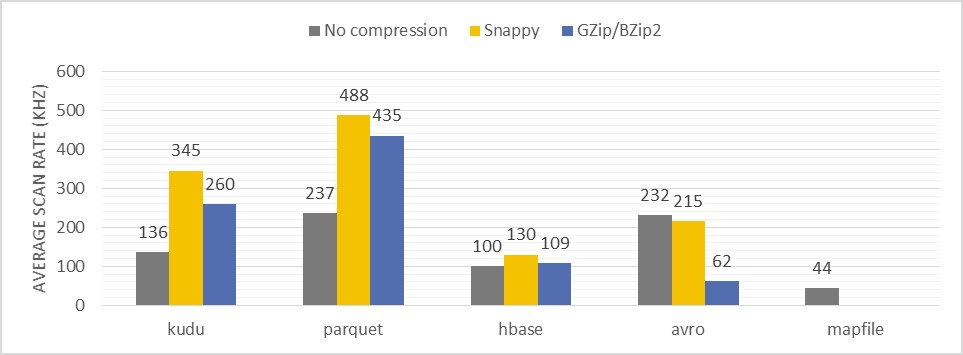
Description of the test: Counting the number of records having certain substring in one of the non-key columns in entire record collection
در مورد هر کدام از تست های فوق و نتیجه به دست آمده با جزییات کامل در مقاله اصلی، توضیحات کاملی داده شده است و نهایتاً نتیجه گرفته شده است که برای کاربردهای ترکیبی که همه موارد فوق برایشان اهمیت دارد، Kudu یک گزینه بسیار کامل و مناسب است. برای کاربردهای تحلیلی و پردازش انبوه هم پارکت (و البته ORC) گزینه کارآتری است. Carbondata هم اگر به این تست اضافه میشد، نتیجه ای در خور و کامل به دست می آمد اما شکل زیر را که مقاله دوم در بخش نتیجه گیری نهایی خود آورده است را فعلاً به عنوان یک معیار دم دستی برای خود در نظر بگیرید :