
در قسمت اول این سری آموزشی، با برخی مفاهیم اصلی در یادگیری ماشین مانند مدل، متغیرهای وابسته و متغیرهای مستقل آشنا شدیم و دریافتیم که هدف اصلی یادگیری ماشین که یکی از سه رکن اصلی علم داده است، درک بهتر داده ها و کشف روابط بین متغیرهای وابسته و مستقل و نهایتاً تخمین یک مقدار یا یک پیش بینی است. نیز دسته بندی داده ها به دو قسمت آموزش مدل و تعیین مقادیر پارامترهای آن و بخش آزمایش را هم اشاره کردیم و دو نوع خطای اصلی در مدلسازی یعنی سوگیری و انحراف از معیار که معیاری برای فاصله گرفتن مقادیر تخمین زده شده یا پیش بینی شده مدل از مقادیر اصلی است را با جزییات و زدن مثال، بیان کردیم.
در این مقاله، با کمی برگشت به عقب، به تعریف دقیق تر علم داده، اصول اصلی آن و فرآیندی که توسط دانشمندان علم داده در مواجهه با مسائل دنیای واقعی به کار گرفته می شود، آشنا خواهیم شد و دیدی کلی نسبت به این علم در سطح کلان پیدا خواهیم کرد.
تعریف علم داده
انستیتو ملی استاندارد و فناوری آمریکا، دوره ای هفت جلدی درباره تمام زوایای کلان داده شامل تعاریف، طبقه بندی، کاربردها، امنیت، معماری و نقشه راه تحت عنوان چارچوب همکاری کلان داده منتشر کرده است که در جلد اول آن به تعریف کلان داده و همچنین علم داده پرداخته است. در این استاندارد، علم داده اینگونه تعریف شده است :
علم داده عبارت است از استخراج مستقیم دانش کاربست پذیر از داده از طریق فرآیند تولید فرضیه (کاوش) و سپس آزمایش فرضیه.
چیکیو هایاشی در کتاب «علم داده چیست؟ مفاهیم اصلی و یک مثال مکاشفه ای» علم داده را فرآیند یکی کردن علم آمار و تحلیل داده و استفاده از روشهای این دو علم برای درک و تحلیل پدیده های طبیعی از طریق داده ، می داند.
عبارت «علم داده» به قدری در سالهای اخیر در مقالات و نوشته های گوناگون و به شکل های مختلف به کار گرفته شده است که شاید تعریف یکسان و یکنواختی برای آن نتوانیم پیدا کنیم اما می توانیم به صورت کلی علم داده را اینگونه تعریف کنیم :
علم داده عبارتست از فرآیند استخراج دانش از داده های موجود برای بهبود فرآیندهای زندگی که ماحصل آن، درک بهتر داده های یک سازمان و اتخاذ تصمیمات مناسب در زمان مناسب و بهبود فرآیندها است .
مهارتهای لازم برای علم داده را طبق تعریف موسسه استاندارد آمریکا می توان به صورت زیر نمایش داد :
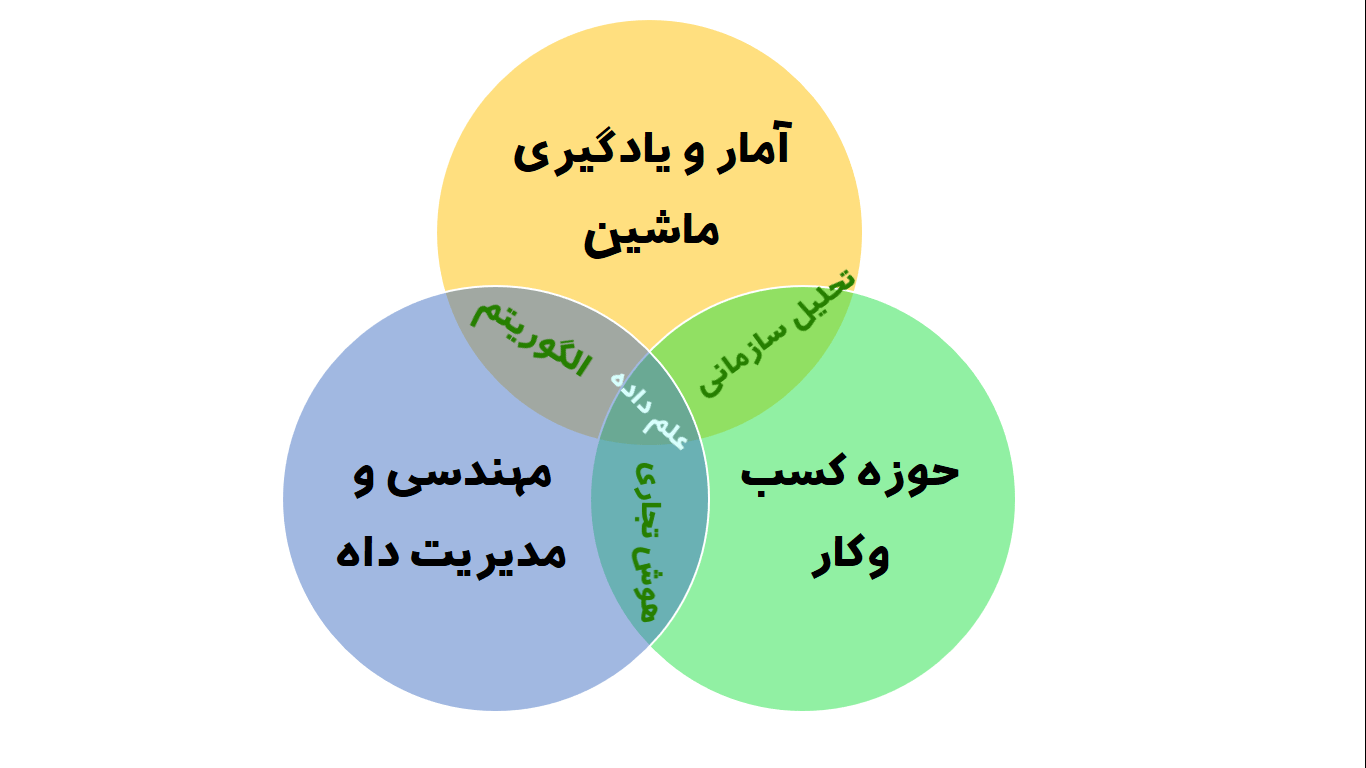
در هر صورت علم داده،هر چه که باشد اصول زیر را در آن می توانیم به عنوان اصول بنیادین قبول کنیم :
- داده یک سرمایه استراتژیک است : این اصل از پیش زمینه سازمانی برخوردار است. با این نگاه باید یکسره از خود بپرسیم «آیا همه سرمایه های داده ای که روزانه جمع آوری و ذخیره می کنیم، استفاده می شود؟ » جواب اکثر مدیران فناوری اطلاعات به این پرسش «نه» خواهد بود . بنابراین قبل از هر چیز باید به اهمیت داده در سازمان واقف باشیم تا بتوانیم فرآیندهای مختلف علم داده برای بهبود کار را در آن به کار گیریم .
- استخراج دانش یک فرآیند سیستماتیک و مشخص است : برای استخراج دانش از داده های موجود، باید از فرآیندی شفاف و کاملا مشخص استفاده کنیم که روند کار در هر مرحله و نیز خروجی و دستاوردهای هر بخش آن، کاملا مشخص و از پیش تعیین شده باشد . استاندارد CRISP در داده کاوی یکی از این فرآیندهای استخراج دانش است. بنابراین اینکه به صورت تصادفی و با سعی و خطا بخواهیم به دانش جدید از داده ها برسیم، امری خطاست.
- پردازش داده به عنوان یک هنر و فرآورده عاشقانه نگریسته شود : سازمانها باید هر چه بیشتر روی افرادی که علاقه مند به داده باشند، سرمایه گذاری کنند. تبدیل داده به ارزش و دانش مفید، کیمیا نیست و نیاز به کیمیاگر و جادوگر هم ندارد. بلکه بار اصلی آن برعهده افرادیست که هم اصول آنرا بلد باشند و هم کار با داده را دوست داشته باشند و هم از چاشنی خلاقیت بهره مند باشند. افرادی که بتوانند داده، فناوری و تجارت را به هم متصل کنند.
- استقبال از عدم قطعیت : علم داده یک شاه کلید نیست و توقع معجزه از آن نباید داشته باشید. مشابه با گزارشات و KPI در داشبوردهای مدیریتی، این علم تنها به اخذ تصمیمات بهتر کمک می کند و در حوزه قلمرو احتمالات قرار میگیرد نه حوزه قطعیت و یقین . یعنی نمی توان خروجی های آنرا یقینی و صددرصدی شمرد و اگر با استفاده از روشهای علم داده به دانشی دست یافتید و آنرا به کار بستید و بهبودی مشاهده نکردید، از آن استقبال کنید و بدانید که حتماً متغیر یا پارامتری را از قلم انداخته اید و این فرآیند با دقت بیشتر باید مجددا انجام شود. بهتر است رهیافت اشتباه زیاد – تجربه زیاد را به کار ببندید.
- اصل کسب و کار-تحلیل- کسب و کار : به نظرم ، این اصل مهم ترین اصل در علم داده است . تمرکز بسیاری از دانشمندان علم داده بر یافتن الگوریتم مناسب برای حل یک مساله در کسب و کار است اما مهم تر از این کار، به کار بستن مناسب نتایج آن در کسب و کار است به گونه ای که نتایج آن ملموس شده و به کار آید. بنابراین، ابتدا مشکلی را از کسب و کار شناسایی کنید، آنرا تحلیل کرده و به کمک علم داده، راه حلی برای آن بیابید و سر آخر، این نتیجه را مجددا در کسب و کار به کار بگیرید.
فرآیند علم داده
با در نظر گرفتن اصل دوم، باید به دنبال فرآیندی منظم و شفاف برای مسائل دنیای واقعی و نحوه به کارگیری علم داده برای آنها باشیم. موسسه ملی استاندارد و فناوری آمریکا این فرآیند را شامل چهار مرحله زیر می داند :
- جمع آوری داده : گردآوری داده و ذخیره آن به شکل خام
- پیش پردازش داده : تمام فرآیندی که برای تبدیل داده خام به داده ای پاکسازی شده و بدون خطاهای ابتدایی و سازمان یافته لازم است.
- تحلیل و مدلسازی : تکنیک های استخراج و مدلسازی داده از داده های ساختار یافته و نظام مند.
- اعمال دانش : آماده کردن دانش تولید شده برای استفاده دز کسب و کار
این چهار مرحله بسیار کلی بوده و نیاز به موشکافی و جزئیات بیشتری دارد بنابراین اگر بخواهیم به صورت دقیق تر و جزئی تر به این فرآیند نگاه کنیم، مراحل زیر را در فرآیند علم داده و استخراج دانش باید پیش بگیریم :

- تعریف مساله و مشکل موجود در حوزه کسب و کار : در قسمت قبل جمله مشهوری از انیشتین را نقل کردیم «هر چیزی باید ساده شود اما نه ساده تر از آنچه لازم است». این اصل طلایی در مواجهه با مشکلات و نیازمندیهای کسب و کار هم باید لحاظ شود. مساله و مشکلی که برای یک کسب و کار بوجود آمده است را باید به دقت بررسی و مستند نمود بخصوص شرایط موفقیت از دید صاحبان بنگاه برای راه حل های پیشنهادی باید مشخص و شفاف باشد. پرسنل موجود آن شرکت به حد کافی مشغله کاری دارند و باید شخصی با نگاه بیرون از سازمانی، از طریق مصاحبه، طوفان فکری ، کارگاه های خلاقیت و آموزش، چالشهای آنها را شناسایی و آنها را مستند نموده، تایید و نظر نهایی کارفرما را اخذ کند. فرض کنید یک شرکت مخابراتی با کاهش درآمد سالیانه مواجه شده است. چالش این شرکت باید این گونه شناسایی و مستند شود : شرکت نیاز به افزایش مشتریان خود از طریق شناسایی بازارهای هدف جدید و کاهش نرخ خروج از خدمات را دارد.
- تجزیه مساله به ریزکارهای یادگیری ماشین : زمانی که مشکل حوزه کسب و کار به خوبی شناسایی شد، باید آنرا به رهیافت های مختلفی که در یادگیری ماشین در مواجهه با مسائل می توان در پیش گرفت، تقسیم کرد. به هر کدام از این رهیافتها، یک ریزکار می گوییم (Task) هر ریزکار یک وظیفه خاص را برعهده دارد مثلا مساله قبل را می توانیم به دو ریزکار زیر تجزیه کنیم :
- کاهش نرخ خروج مشتریان تا X درصد
- شناسایی مشتریان بالقوه
- پیش پردازش داده : زمانی که فهمیدیم به دنبال چه هستیم، باید داده هایی که نیاز داریم را جمع آوری و سپس پاکسازی کنیم. منظور از پاکسازی هم یکنواخت کردن داده ها، حذف داده های نامعتبر، تغییر نوع داده ها و مانند آن است که باعث افزایش کیفیت و یک دست شدن داده ها می گردد.
- تحلیل اکتشافی داده ها : قبل از انتخاب الگوریتم نهایی برای هر ریزکار، بهتر است با داده ها بیشتر آشنا شویم و با بررسی های مختلف، سعی در فهم مختلف آنها داشته باشیم. این فرآیند که قبلا مثالی از آنرا هم در این سایت منتشر کرده ایم، باعث کشف الگوهای جدید در داده ها و نیز شناسایی و درک بهتر آنها برای انتخاب الگوریتم مناسب نهایی خواهد بود.
- انتخاب الگوریتم نهایی و مدلسازی داده ها : در این مرحله، به ازای هر ریزکار مشخص شده، الگوریتم های مختلف متناظر با آن را بررسی و با توجه به حوزه کار و داده های موجود و خصوصیات آنها، بهترین الگوریتم رابرای ساخت مدل انتخاب می کنیم. مانند الگوریتم جنگل تصادفی، درخت تصمیم ، رگرسیون و مانند آن.
- ارزیابی و تحویل مدل / پایش مداوم : بعد از ساخت مدل و ارزیابی آن و تنظیم پارامترها، مدل ساخته شده را در کسب و کار به کار می گیریم و به صورت مداوم هم، نتیجه کار را بررسی می کنیم تا اگر مشکل یا بی دقتی در مدل در دنیای واقعی مشاهده شد، به سرعت آنرا برطرف سازیم.
اینکه کدامین الگوریتم و مدل را انتخاب کنیم و اصلا وظایف اصلی و ریزکارهای یادگیری ماشین چه هستند، در ادامه و به تدریج صحبت خواهیم کرد. تا آنزمان می توانید به مقاله «آشنایی با الگوریتم های ضروری یادگیری ماشین» مراجعه نمایید.