
این مقاله از وب سایت فابک با همین عنوان و با قلم محمد جواد سخایی (در سه قسمت)،با هدف جمع آوری مطالب مفید حوزه کلان داده، عیناً بازنشر شده است.
بخش اول
بانک های اطلاعاتی از گذشته تا کنون
از گذشته تاکنون شاهد سه دوران مختلف در عرصه بانک های اطلاعاتی بوده ایم . شکل ۱ ، این دوره های مختلف را نشان می دهد.از سیستم های مدیریت بانک های اطلاعاتی رابطه ای (RDBMS ) برای تراکنش ها و از بانک های اطلاعاتی تحلیلی ( Analytics) برای انبار داده استفاده می گردد . NoSQL قرار است پاسخ گوی چه نیازهایی باشد و یا ما با چه کمبودی در عرصه ذخیره و بازیابی اطلاعات مواجه شده بودیم که ضرورت وجود یک الگوی معماری جدید بانک اطلاعاتی احساس گردید.

شکل ۱ : دوره های مختلف بانک های اطلاعاتی
شکل ۲ ، وضعیت قبل از NoSQL را نشان می دهد .
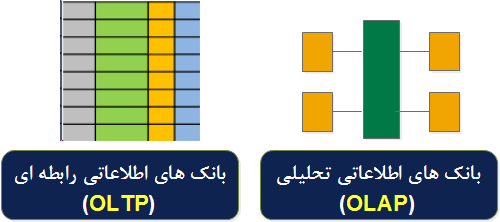
شکل ۲ : وضعیت بانک های اطلاعاتی قبل از NoSQL
به دنبال تحولات عظیم در عرصه فناوری اطلاعات از یک طرف و همچنین تغییرات عمده در نیازهای کسب و کار، معماری مبتنی بر تک گره RDBMS با چالش های متعددی روبرو گردید . در شکل ۳ به برخی از این چالش ها اشاره شده است .
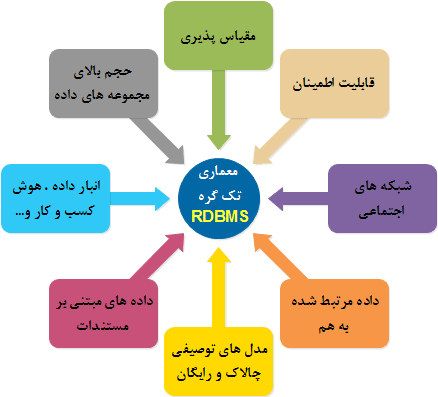
شکل ۳ : برخی چالش های معماری RDBMS تک گره ای
با توجه به موارد اشاره شده ، از سال ۲۰۱۰ به بعد نیاز به یک الگوی جدید معماری در عرصه بانک های اطلاعاتی به شدت احساس گردید . ظهور NoSQL پاسخی به این نیاز بود . شکل ۴ ، وضعیت بعد از NoSQL را نشان می دهد.
شکل ۴ : وضعیت بانک های اطلاعاتی پس از NoSQL
درادامه با الگوهای مختلف معماری داده NoSQL آشنا خواهیم شد .
الگوهای معماری داده NoSQL
در این بخش کار خود را با بررسی ساده ترین نوع معماری داده NoSQL که به آن key-value می گویند شروع خواهیم کرد و در بخش های بعد به بررسی سایر الگوها خواهیم پرداخت . خواهیم دید که چگونه می توان از این الگوی مقرون به صرفه برای حل مسایل کسب و کار متعددی استفاده کرد. در ادامه به بررسی موارد زیر خواهیم پرداخت :
- Key-value store چیست ؟
- مزایای استفاده از key-value store
- نحوه استفاده ازkey-value store
- بررسی یک نمونه مثال کاربردی از نحوه استفاده key-value store
Key-value store چیست ؟
Key-value store یک بانک اطلاعاتی ساده است که با ارایه یک رشته ساده به عنوان کلید، می تواند حجم بالایی از داده ( value ) را برگرداند.ساختار ذخیره سازی فوق دارای یک زبان پرس و جو (query ) نمی باشد و از یک روش خاص جهت اضافه کردن و یا حدف زوج کلید- مقدار استفاده می نماید .یک key-value store را می توان مشابه یک واژه نامه در نظر گرفت که دارای لیستی از کلمات است و هر کلمه دارای یک و یا چندین تعریف است. یک واژه نامه ساده در شکل ۵ نشان داده شده است .

شکل ۵ : یک واژه نامه ساده و شباهت آن به یک Key-value store
واژه نامه یک key-value store ساده است که کلمات key و تعاریف value می باشند . پس از ذخیره واژه ها در واژه نامه به صورت الفبایی ، امکان بازیابی سریع آنها فراهم می شود و لازم نیست برای واژه ای که به دنبال معنی آن هستیم ، تمامی واژه نامه را جستجو کرد .همانند واژه نامه ، یک key-value store توسط key ، ایندکس گذاری می شود . Key مستقمیا به value اشاره می کند. ماحصل این کار بازیابی سریع اطلاعات (values ) ، صرف نظر از تعداد واژه های ذخیره شده است . یکی از مزایای عدم مشخص کردن نوع داده در یک key-value store ، امکان ذخیره سازی هر نوع داده در value است . سیستم ، اطلاعات را به عنوان یک BLOB ذخیره می نماید و زمانی که از دستور GET جهت بازیابی استفاده می گردد ، BLOB مشابه برگردانده می شود . این به عهده برنامه است که مشخص سازد چه نوع داده یی استفاده شده است : یک رشته ، فایل xml و یا binary image .
BLOB از کلمات Binary Large Object اقتباس شده است و نشان دهنده مجموعه ای از داده باینری ذخیره شده به عنوان یک entry در یک سیستم مدیریت بانک اطلاعاتی است که معمولا شامل متن ، تصاویر ، صدا و سایر اشیاء چند رسانه ای است.
کلید( Key ) در یک key-value store ، انعطاف پذیر بوده و می تواند با قالب های مختلفی همچون اسامی مسیر منطقی به تصاویر و یا فایل ها ، رشته های تولید شده هوشمند از مقدار هش شده ، فراخوانی سرویس وبREST و یا SQL queries ارایه شود . مقادیر(Value) نیز نظیر کلیدها ، دارای انعطاف لازم بوده و می توانند شامل هر نوع BLOB داده نظیر تصاویر ، صفحات وب ، مستندات و ویدیوها باشد. شکل ۶ ، نمونه ای از یک key-value store متداول را نشان می دهد .
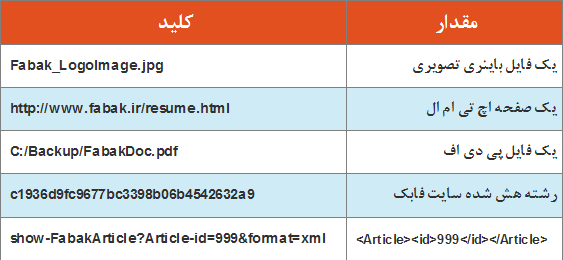
شکل ۶ : چندین زوج کلید-مقدار ذخیره شده در یک key-value store
مزایای استفاده از یک Key-value store
نحوه استفاده از Key-value store
چگونه پیاده کنندگان یک برنامه می توانند از یک key-value store درون برنامه استفاده کنند ؟ بهترین روش برای تصور این که چگونه یک key-value store مقادیر را ذخیره می کند ، در نظر گرفتن آن به عنوان جدولی با دو ستون است . اولین ستون Key و دومین ستون value است . سه عملیات را می توان در ارتباط با key-value store تعریف کرد : put , get و delete . دستورات فوق ، اینترفیس مورد نیاز برنامه نویسان جهت کار با Key-value store را ارایه می نماید که به آن API ( برگرفته شده از Application Program Interface ) گفته می شود . در شکل ۷ اینترفیس فوق نشان داده شده است .

شکل ۷ : سه دستور Put , Get و Delete رابط برنامه نویسی key-value store
در مقابل استفاده از یک query language ، پیاده کنندگان برنامه با بکارگیری put , get و delete قادر به دستیابی و عملیات بر روی یک key-value store می باشند . علاوه بر دستورات فوق، یک key-value store دارای دو قانون کلی زیر است:
- Distinct keys: نمی توان دارای دو سطر با key-value مشابه بود. این بدان معنی است که تمامی کلیدها در key- value store منحصربفرد می باشند.در صورتی که به صورت منحصربفرد یک زوج key-value را مشخص و شناسائی نکنیم ، نمی توان یک مقدار را به عنوان نتیجه کار برگرداند .
- No queries on values: نمی توان بر روی مقادیر موجود در جدول query اجراء کرد. اگر صرفا متمرکز بر روی بانک های اطلاعاتی رابطه ای تمرکز نماییم ، لازم است توضیحات بیشتری در این خصوص داده شود.در یک بانک اطلاعاتی رابطه ای ، می توان با استفاده از where clause محدودیت هایی را در خصوص برگرداندن نتایج حاصل از اجرای یک query اعمال کرد . در صورتی که در یک key-value store ماحصل اجرای query ،برگرداندن یک آیتم خواهد بود .نمی توان یک زوج key-value را با استفاده از value انتخاب کرد . Key-value store این مساله را با ایندکسینگ در لایه برنامه برطرف می نماید. این کار اجازه می دهد ، key-value دارای یک ساختار ساده و انعطاف پذیر باشد .
پس از آشنایی با مزایا و نحوه استفاده از key-value store ، به بررسی یک نمونه مثال کاربردی خواهیم پرداخت . هدف این مثال ، ذخیره صفحات وب در یک key-value store است و نشان می دهد که چگونه یک موتور جستجو نظیر گوگل تمامی وب سایت ها را در یک key-value store ذخیره می کند.
مثال : ذخیره صفحات وب در یک Key-value store
گوگل از ابزاری به نام web crawler برای مشاهده اتوماتیک یک وب سایت ، استخراج و ذخیره سازی محتویات هر یک از صفحات وب استفاده می کند. در ادامه ، کلمات موجود در هر صفحه وب به منظور جستجوی سریع کلمات ، ایندکس گذاری می گردند . زمانی که از یک مرورگر وب استفاده می کنیم معمولا آدرس یک وب سایت را به صورت http:// www.example.com/hello.html وارد می نماییم . این URL ، کلید یک وب سایت و یا یک صفحه وب را مشخص می کند . می توان وب را به صورت یک جدول بزرگ با دو ستون(کلید ، مقدار) در نظر گرفت . شکل ۸ ، نحوه ذخیره محتویات صفحات یک وب سایت به کمک key-value store را نشان می دهد .
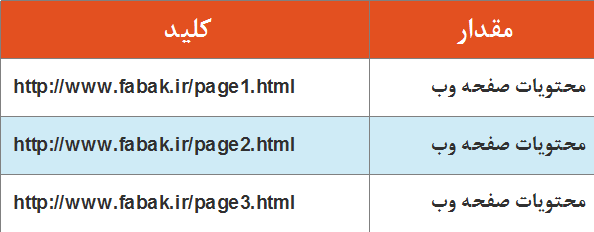
شکل ۸ : استفاده از یک URL به عنوان یک کلید در key-value store
URL ، کلید است و value محتویات صفحه وب در آن آدرس را مشخص می کند. اگر تمامی صفحات وب را در یک سیستم key-value store ذخیره نماییم دارای میلیاردها و یا تریلیون ها زوج key-value خواهیم بود . هر کلید می بایست منحصربفرد باشد همانند یک URL به یک صفحه وب که منحصربفرد است . قابلیت استفاده از URL به عنوان یک کلید به شما اجازه ذخیره تمامی اجزاء استاتیک و غیرتغییر وب سایت را در یک key-value store می دهد . این عناصر شامل تصاویر ، صفحات HTML استاتیک ، فایل های CSS و کد جاوااسکریپت می باشند . تعداد زیادی از وب سایت ها از رویکرد فوق استفاده می کنند و تنها بخش های پویای یک وب سایت را که توسط اسکریپت ها تولید می شوند در key-value store ذخیره نمی کنند .
بخش دوم
رد پای گراف در علم کامپیوتر
تاکنون از گراف در ابعاد گسترده ای در زمان ایجاد فرآیندهای نرم افزار استفاده شده است ولی این روند در حال تغییر است و بسیاری از پیاده کنندگان تمایل دارند ضمن فراموش کردن گذشته ، با نگاهی نو و این مرتبه در جهت نگهداری داده به آن توجه نمایند . ما تاکنون نهایت سعی خود را داشته ایم که داده را درون جداول و ستون های بانک های اطلاعاتی رابطه ای قرار دهیم و در ادامه ساختار آن را نرمالیزه و یا از حالت نرمالیزه خارج کنیم تا به چیزی که در عمل می خواهیم ، دست یابیم .
بانک های اطلاعاتی گراف از مدل گراف جهت ذخیره داده استفاده می نمایند . در این مدل ، ساختار گراف شامل رئوس و یال ها ( به عنوان دو موجودیت مهم مدل سازی هر نوع گراف ) مدل سازی می گردد .علاوه بر این ، می توان از تمامی الگوریتم های موجود تئوری گراف ( با توجه به قدمت طولانی آن ) برای حل مسائل گراف با کارآیی بیشتر و در زمان کمتر نسبت به بانک های اطلاعاتی رابطه ای استفاده کرد. Neo4j ، نمونه ای از یک بانک اطلاعاتی گراف است که به کمک آن می توان مسایل گراف را با کارآیی بهتر و ظرافت بیشتر حل کرد .Neo4j دارای جایگاهی برجسته در خانواده بزرگ NoSQL است .
شکل ۹ ، یک نمونه ساختار گراف جهت ذخیره سازی داده کاربران به همراه دوستان هر یک را نشان می دهد .
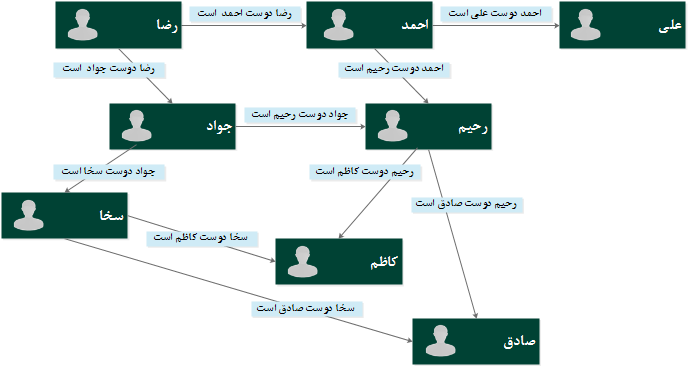
شکل ۹ : یک نمونه بانک اطلاعاتی گراف برای ذخیره کاربران و دوستان مرتبط به هر یک
مروری بر Graph store
Graph store ، سیستمی است که شامل دنباله ای از گره ها و ارتباطات است که با ترکیب آنها با یکدیگر یک گراف ایجاد می گردد. همانگونه که در بخش اول اشاره گردید، معماری داده key-value store شامل دو فیلد key و value است . در مقابل ، در یک Graph store از سه فیلد اساسی داده با نام گره ، روابط و خصلت استفاده می شود. به برخی از گراف ها به دلیل ساختار node-relationship-node ، اصطلاحا triple stores گفته می شود شکل ۱۰ ، ماهیت یک بانک اطلاعاتی گراف را نشان می دهد .
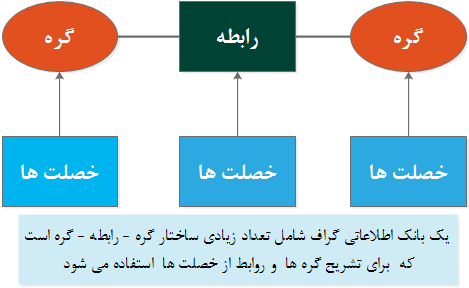
شکل ۱۰ : ساختار یک بانک اطلاعاتی گراف
زمانی که دارای آیتم های زیادی می باشیم که با یکدیگر روابط پیچیده ای دارند و هر یک نیز دارای خصلت های مختص به خود می باشند، استفاده از Graph stores بسیار مناسب است . در Graph store امکان اجرای query ساده وجود دارد و می توان به عنوان نمونه نزدیک ترین همسایه و یا الگوی خاصی را پیدا کرد . مثلا اگر از یک بانک اطلاعاتی رابطه ای برای ذخیره لیستی از دوستان خود استفاده کرده باشید ، می توان لیست مرتب شده ای بر اساس نام خانوادگی از دوستان خود را تولید و در خروجی نمایش داد . در صورت استفاده از graph store ، نه تنها می توان لیستی از دوستان خود را بر اساس نام خانوادگی پیدا کرد ، همچنین می توان لیستی از دوستان خود را که علاقه مند به مطالعه کتاب های علمی می باشند نیز پیدا کرد . Graph stores ، صرفا به این موضوع اکتفاء نمی کند که به شما بگوید بین دو گره یک رابطه وجود دارد بلکه قادر به ارایه گزارشات تکمیلی همراه با جزییات مورد نیاز در خصوص هر یک از روابط موجود است.
گره های گراف معمولا بیانگر اشیاء دنیای واقعی نظیر اسامی می باشند . گره ها می توانند افراد ، سازمان ها ، شماره تلفن ، صفحات وب ، کامپیوترهای موجود بر روی یک شبکه و یا حتی سلول های بیولوژیکی در یک ارگانیزم زنده باشند . ارتباطات را می توان به منزله اتصالات بین اشیاء درنظر گرفت که معمولا به صورت کمان در دیاگرام ها نشان داده می شوند . اجرای یک query بر روی یک گراف ، مشابه حرکت کردن بین گره ها در یک گراف است . به عنوان نمونه می توان با اجرای یک query به درخواست هایی مشابه زیر پاسخ داد:
- کوتاهترین مسیر بین دو گره موجود در گراف چیست ؟
- چه گره ای دارای همسایگانی با خصلت های خاصی است ؟
- با دادن دو گره در گراف ، تا چه میزان همسایگان آن به هم شبیه هستند ؟
- متوسط ارتباطات بین نقاط مختلف گراف با یکدیگر چه میزان است ؟
همانگونه که قبلا اشاره گردید ، در سیستم های مدیریت بانک اطلاعاتی رابطه ای (RDBMS ) از اعداد به عنوان کلید اصلی و خارجی برای ارتباط سطرها در جداولی که در بخش های مختلف یک هارد دیسک ذخیره شده اند ، استفاده می گردد . انجام عملیاتی نظیر Join در RDBMS دارای هزینه بالایی است و علاوه بر تاخیر در انجام عملیات ، I/O زیادی را نیز به دنبال خواهد داشت. Graph store ، گره ها را با یکدیگر مرتبط می نماید و متوجه این موضوع می شود که دو گره با شناسه یکسان ،گره های مشابه هستند . Graph stores به گره ها شناسه های داخلی را نسبت می دهد و از این شناسه ها برای Join شبکه ها به یکدیگر استفاده می کند. بر خلاف RBDMS ، در Graph stores عملیات Join سبک تر بوده و کار با سرعت به مراتب بیشتری انجام می شود . علت این کار به ماهیت کوچک هر گره و قابلیت نگهداری گراف در RAM برمی گردد . این بدان معنی است که گراف درون حافظه بارگذاری می شود و بازیابی داده نیازمند عملیات I/O نمی باشد .
برخلاف سایر الگوهای NoSQL ، مقیاس پذیری Graph stores بر روی چندین سرویس دهنده دارای چالش های مختص به خود است . در چنین مواردی . می توان داده را بر روی چندین سرویس دهنده تکرار کرد تا امکان خواندن و کارآیی اجرای query بهتر گردد . ولی نوشتن بر روی چندین سرویس دهنده و اجرای query بر روی گرافی که گره های آن بین چندین سرویس دهنده توزیع شده اند دارای پیچیدگی ها مختص به خود است .
با این که Graph stores بر اساس واقعیت ساختار داده node-relationship-node ایجاد می گردد ولی می تواند دارای پیچیدگی های مختص به خود باشد و حتی در برخی موارد ناسازگار به نظر آید . روش تعامل با Graph stores مشابه سایر بانک های اطلاعاتی است : داده بارگذاری می گردد ، query بر روی آن اجرا می شود و در صورت لزوم داده بهنگام و یا حذف می گردد. تفاوت به نوع query استفاده شده برمی گردد . یک query گراف ، مجموعه ای از گره های مورد نیاز برای ایجاد یک graph image و نمایش ارتباطات بین داده را برمی گرداند .
واژه ها و اصطلاحات Graph store
اجازه دهید ، نگاهی داشته باشیم به اصطلاحات مختلفی که از آنها جهت تشریح نوع های مختلف گراف استفاده می گردد. همانگونه که در صفحات وب مشاهده کرده اید ، لینک های موجود بر روی یک صفحه وب شما را به سمت صفحه دیگر هدایت می کنند. این لینک ها می توانند توسط یک گراف نمایش داده شوند . صفحه وب موجود اولین و یا گره مبداء است . لینک ، کمانی است که به صفحه دوم اشاره می کند و دومین صفحه مقصد ، گره دوم است. در این مثال ، اولین گره توسط URL صفحه مبداء نشان داده می شود و دومین گره و یا مقصد ، URL صفحه مقصد است . این فرآیند ارتباطی بین صفحات ، می تواند در مکان های مختلفی بر روی وب مشاهده شود. شکل ۱۱ ، یک نمونه Graph store شامل یک صفحه وب و ارتباط آن به دو صفحه وب را نشان می دهد.
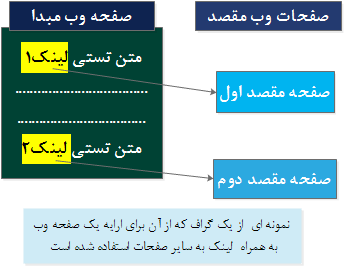
شکل ۱۱ : استفاده از گراف برای ارایه یک صفحه وب به همراه لینک به دو صفحه دیگر
شکل ۱۲ ، نحوه پیاده سازی گراف برای ارایه یک صفحه وب به همراه لینک به دو صفحه دیگر را نشان می دهد .

شکل ۱۲ : نحوه پیاده سازی گراف برای ارایه یک صفحه وب به همراه لینک به دو صفحه دیگر
همانگونه که در شکل ۱۲ ملاحظه می شود، URL صفحه وب مبداء به عنوان یک Property URL ذخیره شده است و هر لینک ، بیانگر یک رابطه است که دارای خصلتی با نام : “points to ” است .هر لینک از طریق خصلت فوق به URL صفحه مقصد اشاره می کند . .مفهوم استفاده از URLs برای شناسایی گره ها جذاب است ، چراکه توسط انسان قابل خواندن است و ساختاری درون URL را ارایه می نماید. W3C این ساختار را به منظور ذخیره اطلاعات لینک های بین صفحات (همانند لینک بین اشیاء درون یک RDF برگرفته شده از Resource Description Format که در واقع یک مدل داده متادیتا می باشد) ، استاندارد کرده است.
مثال
در این بخش به کاربرد Graph store به منظور حل دو نمونه از مسایل کسب و کار اشاره ای مختصر خواهیم داشت .
- Link analysis: زمانی استفاده می شود که قصد جستجو و یافتن الگوها و ارتباطاتی را در مواردی نظیر شبکه های اجتماعی ، تلفن و یا رکوردهای ایمیل داشته باشیم.
- Integrating Linked data: به منظور کار با حجم بالایی از داده لینک شده باز (open Linked data) برای یکپارچه سازی بلادرنگ و ایجاد mashup بدون ذخیره داده استفاده می شود. Mashup ، یک صفحه وب و یا یک برنامه وب است که محتویات خود را از بیش از یک منبع دریافت و یک سرویس جدید را در قالب یک اینترفیس گرافیکی ارایه می نماید. مثلا می توان با ترکیب آدرس ها و تصاویر شعب یک شرکت بزرگ به همراه google map ، یک map mashup را ایجاد کرد.
Link analysis
در برخی موارد ، پیمایش داده گراف بهترین روش برای حل یک مساله کسب و کار است . به عنوان نمونه می توان به شبکه های اجتماعی اشاره کرد . شکل ۱۳ ، نمونه ای از یک شبکه اجتماعی را نشان می دهد . در این شکل هر فرد به صورت یک دایره مشخص شده است و بین دو فرد در صورت وجود ارتباط ، یک لینک برقرار شده است.هر یک از افراد با توجه به تعداد ارتباطات با سایر افراد بر روی گراف نشان داده شده اند . در شکل فوق، وضعیت ارتباطی یک کاربر نسبت به همکاران سابق خود در شرکت یاهو( رنگ سبز) و تحلیل گران گوگل ( رنگ صورتی ) مشخص شده است . همچنین ، وضعیت ارتباط وی با سایر همکاران و دوستان در شبکه اجتماعی LinkedIn ( رنگ آبی ) و هم کلاسی ها در دانشگاه کارنگی ملون( رنگ نارنجی) مشخص شده است .
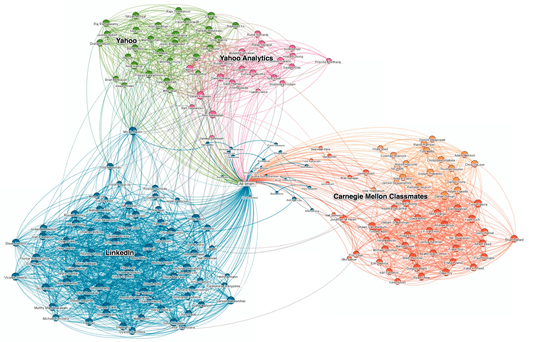
شکل ۱۳ : یک گراف شبکه اجتماعی
به موازات این که به لیست دوستان خود افراد جدیدی را اضافه می کنید ، ممکن است به دنبال این موضوع باشید که آیا دوست مشترکی بین شما وجود دارد . در ابتدا لازم است ، لیستی از دوستان خود را داشته باشد و برای هر یک از آنها که در لیست شما می باشند ، لیست دوستان آنها را داشته باشید (friends-to-friends ) . فرض کنید بخواهیم چنین کاری را توسط یک بانک اطلاعاتی رابطه ای انجام دهیم ، پس از اولین مرحله ، کارآیی سیستم به شدت افت پیدا خواهد کرد . انجام این نوع تحلیل ها به کمک یک سیستم مدیریت بانک اطلاعاتی رابطه ای می تواند خیلی کند باشد. در شبکه های اجتماعی ، شما می توانید جدولی با نام friends برای هر شخص با سه ستون ID نفر اول و ID نفر دوم و نوع ارتباط بین آنها ( خانوادگی ، دبیرستانی و … ) بسازید . در ادامه می توان ، بر روی دو فیلد نفر اول و نفر دوم ایندکس ایجاد کرد تا یک RDBMS بتواند به سرعت لیست دوستان شما و لیست دوستان دوستان شما را در اختیار شما قرار دهد. ولی اگر بخواهیم به سراغ سطح بعدی برویم یک query دیگر لازم است . به موازات این که کار ساخت ارتباطات را ادامه می دهیم ، اندازه query نیز به سرعت رشد پیدا می کند. اگر ما دارای ۱۰۰ دوست باشیم و هر یک دارای ۱۰۰ دوست باشد ، query از نوع friends-of-friends و یا سطح دوم دوستان ، ۰۰۰ ، ۱۰ ( ۱۰۰ * ۱۰۰ ) سطر را برمی گرداند . همانگونه که حدس زده اید، انجام این نوع query در SQL پیچیده است . Graph stores این نوع عملیات را به مراتب سریعتر و با استفاده از روش هایی که عملیات ادغام و حذف گره های ناخواسته از حافظه را به دنبال دارد ، انجام می دهد. Graph stores دارای شفافیت و سرعت به مراتب بیشتری جهت انجام کارهایی نظیر تحلیل لینک ها است. آنها معمولا به حافظه RAM مناسبی نیاز دارند تا بتوانند تمامی لینک ها را در زمان تحلیل در حافظه نگهداری نمایند .
استفاده از گراف ها برای پردازش datasets عمومی
از Graph stores می توان جهت تحلیل داده یی که توسط سازمان شما تولید نشده است نیز استفاده کرد . فرض کنید بخواهیم بر روی سه dataset مختلف که توسط سه سازمان مختلف تولید شده اند ، کار کنیم . این سازمان ها حتی ممکن است از وجود هم باخبر نباشند. شما چطور می توان dataset آنها را بطور اتوماتیک Join کرد تا اطلاعات مورد نیاز خود را کسب کرد ؟ استفاده از ابزارهایی که به آنها Linked open data یا LOD می گویند یکی از روش های موثر در این رابطه است . می توان LOD را به منزله یک روش یکپارچه سازی برای Join بین datasets مختلف جهت ایجاد برنامه های جدید در نظر گرفت . استراتژی های LOD برای هر فردی که کار تحقیقات و یا تحلیل را با استفاده از datasets عمومی انجام می دهد بسیار حائز اهیمت است . این تحقیقات می تواند شامل مواردی نظیر هدف گذاری بر روی مشتریان خاصی ، تجزیه و تحلیل رویکرد بازار ، تجزیه و تحلیل احساسات ، تحلیل متون و یا ایجاد سرویس های جدید اطلاعات باشد. ترکیب مجدد داده به اشکال جدید ، فرصت هایی را برای کسب و کارهای جدید فراهم می کند.به موازات رشد LOD ، فرصت های جدیدی برای سرمایه گذاری کسب و کار جدید فراهم می گردد که با ترکیب و غنی سازی این نوع اطلاعات محقق می گردد . با ادغام LOD ، مجموعه داده های جدیدی از طریق ترکیب اطلاعات دو و یا چندین dataset عمومی در دسترس ایجاد می گردد که دارای ساختار LOD نظیر RDF و URI می باشند. در شکل ۱۴ ، نمونه هایی از سایت های LOD متداول که به آن دیاگرام LOD Cloud می گویند نشان داده شده است .
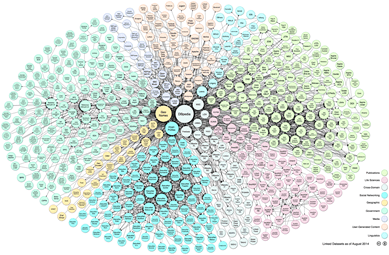
در مرکز دیاگرام ابری LOD ، سایت هایی وجود دارد که دارای تعداد زیادی dataset همه منظوره هستند .این سایت ها شامل هاب سایت های LOD نظیر DBPedia و یا Freebase می باشند . DBPedia ، وب سایتی است که تلاش می کند با برداشت حقایق از ویکی پدیا آنها را به RDF تبدیل کند. در واقع DBpedia ماحصل یک تلاش گروهی با هدف استخراج اطلاعات از ویکی پدیا و ارایه آنها در وب با یک ساختار مشخص جهت اجرای query مورد نظر است . پس از یافتن سایتی که حاوی اطلاعات RDF است ، می توان به دو صورت مختلف آن را پردازش کرد :
- دانلود تمامی فایل های داده RDF از سایت و بارگذاری آنها درون Graph store . برای مجموعه های بزرگ RDF نظیر DBPedia که شامل میلیاردها ارتباط است این روش در عمل غیر ممکن است .
- روش دوم که دارای کارآیی بیشتری است ، یافتن یک سرویس وب برای سایت RDF است که به آن SPARQL endpoint می گویند. این گونه سرویس های وب ، امکان اجرای SPARQL را فراهم می نمایند . SPARQL ، یک زبان Query مبتنی بر RDF است که از آن برای بازیابی و پردازش داده ذخیره شده با قالب RDF استفاده می گردد.
خلاصه
Neo4J , AllegroGraph , Bigdata triple store , InfinitGraph و StartDog نمونه هایی از بانک های اطلاعاتی مبتنی بر گراف می باشند که می توان از آنها جهت ایجاد الگوی معماری داده گراف NoSQL استفاده کرد . در بخش سوم به بررسی Column family یا Bigtable ، سومین الگوی معماری داده NoSQL خواهیم پرداخت .
بخش سوم
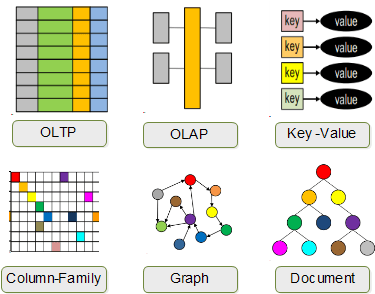
راه حل های مبتنی بر NoSQL ، عموما” به منظور پردازش داده در یک محیط توزیع شده طراحی شده اند . توزیع داده بین چندین گره در یک مرکز داده ، بهبود عملکرد را به صورت خطی و متناسب با بکارگیری تعداد بیشتری از گره ها به دنبال خواهد داشت . ذخیره سازی ، بازیابی و پردازش داده با رعایت اصل مهم مقیاس پذیری، نیازمند یک تجدید نظر کلی در رابطه با طراحی سیستم ها است .امروزه ، سازمان ها درگیر یک تغییر نگرش جدی در حوزه مدیریت حجم بالایی از داده نسبت به روش های سنتی مدیریت داده می باشند .الگوهای معماری داده NoSQL پاسخی شایسته به این تغییر نگرش می باشند . شکل ۱۵ ، چهار گروه عمده بانک های اطلاعاتی NoSQL به همراه متداولترین محصول در هر گروه را نشان می دهد .
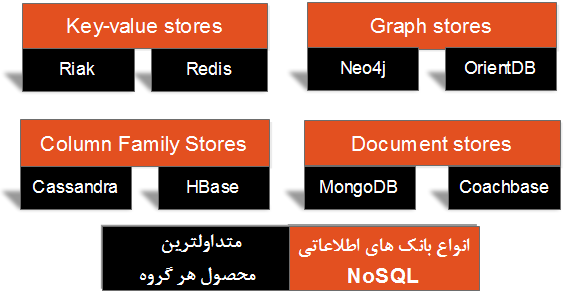
در بخش های گذشته با دو الگوی معماری داده Key-value و Graph آشنا شدیم . همانگونه که اشاره گردید ، الگوهای فوق دارای ساختار ساده ای می باشند که برای حل مجموعه ای از مسایل کسب و کار مفید و قابل استفاده می باشند . در این بخش، بحث خود را در ارتباط با الگوهای معماری داده NoSQL ادامه داده و به سراغ یکی دیگر از این الگوها با نام Column family خواهیم رفت و نشان خواهیم داد که چگونه می توان با ترکیب سطر و ستون یک جدول ، کلیدی جهت دستیابی به داده را ایجاد کرد .
مروری سریع بر الگوی معماری داده Column family
معماری فوق ارتباط نزدیکی با بسیاری از سیستم های MapReduce دارد . MapReduce ، چارچوبی است که از آن برای انجام پردازش موازی بر روی مجموعه های بزرگ داده و در بین چندین کامپیوتر (گره) استفاده می گردد. در فریمورک MapReduce ، عملیات map دارای یک گره master است که وظیفه آن شکست یک عملیات به چندین قسمت و توزیع هر عملیات به گره دیگر برای پردازش است . عملیات Reduce، فرآیندی است که در آن گره master اقدام به جمع آوری نتایج از سایر گره ها و ترکیب آنها با یکدیگر با هدف پاسخ به مساله تعریف شده است. به دلیل اهمیت MapReduce در اینگونه الگوهای معماری داده در ادامه بطور مختصر اشاره ای به آن خواهیم داشت .
MapReduce چیست ؟
مثال : فرض کنید بخواهیم تعداد تکرار هر کلمه را در یک فایل ورودی محاسبه نماییم . برای انجام این کار مراحل زیر را می بایست دنبال کرد.
- داده ورودی به تعدادی رکورد تقسیم می شود .
- تابع map، بر روی رکوردهای ایجاد شده در مرجله قبل پردازش لازم را انجام داده و برای هر کلمه موجود در رکورد، زوج کلید – مقدار را تولید می نماید .
- تمامی زوج های کلید – مقدار که خروجی تابع map می باشند ، با یکدیگر ترکیب شده و بر اساس یک کلید گروه بندی و مرتب می گردند .
- نتایج میانی به تابع reduce ارسال می شوند تا خروجی نهایی را تولید نماید .
مراحل کلی برنامه MapReduce فوق در شکل ۱۶ نشان داده شده است .

شکل ۱۶ : نحوه عملکرد یک برنامه MapReduce
اصول اولیه الگوی معماری داده Column family
به عنوان اولین نمونه از نحوه استفاده سطرها و ستون ها به عنوان یک کلید ، می توان به صفحات گسترده ( spreadsheet ) اشاره کرد.گرچه اکثر ما صفحات گسترده را به عنوان یک فناوری NoSQL در نظر نمی گیریم ، ولی یک روش ایده آل برای تصور این موضوع هستند که چگونه می توان کلیدها را با بیش از یک مقدار ایجاد کرد . شکل ۱۷، یک صفحه گسترده را با یک سلول در سطر ۳ و ستون ۲ ( ستون B ) که حاوی کلمه ‘فابک’ است ، نشان می دهد. سلول دارای آدرس ۳B است و می توان آن را به عنوان کلید جستجو در یک سیستم ماتریس Sparse در نظر گرفت .
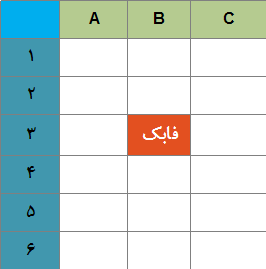
شکل ۱۷ : استفاده از یک سطر و یک ستون برای آدرس دهی یک سلول
در یک صفحه گسترده می توان از تلفیق شناسه های سطر و ستون جهت بازیابی مقدار ذخیره شده در یک سلول بخصوص استفاده کرد . مثلا ستون سوم در سطر دوم توسط کلید C2 شناسایی می شود. در مقایسه با key-value store که دارای یک کلید تک برای شناسایی مقدار است ، یک صفحه گسترده دارای شناسه های سطر و ستون است که با ترکیب آنها کلید دستیابی به یک سلول ایجاد می گردد . همانند key-value store می توان آیتم های مختلفی را در یک سلول قرار داد.یک سلول می تواند شامل داده ، فرمول و یا حتی یک تصویر باشد. وضعیت آدرس دهی در یک صفحه گسترده جهت دستیابی به یک سلول بخصوص در شکل ۱۸ نشان داده شده است.

این مفهوم دقیقا مشابه سیستم های column family است . هر آیتم داده را می توان با آگاهی از شناسه های سطر و ستون آن پیدا کرد و همانند یک صفحه گسترده می توان داده را در هر سلول درج کرد . برخلاف یک سیستم مدیریت بانک اطلاعاتی رابطه ای (RDBMS ) مجبور نیستیم که داده را برای تمامی ستون های یک سطر درج کنیم .
آشنایی با کلیدها
تا این جای کار ما با مفهوم کلیدهای ترکیبی جهت دستیابی به یک داده بخصوص آشنا شدیم . فرض کنید به صفحه گسترده دو فیلد column family و timestamp را اضافه کنیم . ساختارکلید در column family stores مشابه یک صفحه گسترده است با این تفاوت که دارای دو خصلت اضافه دیگر است .علاوه بر نام ستون ، از یک Column family جهت گروه بندی اسامی ستون مشابه استفاده شده است . اضافه کردن یک timestamp در کلید ، این امکان را فراهم می نماید تا بتوان چندین نسخه از یک مقدار را در طول زمان در هر یک از سلول ها ذخیره کرد. . کلید نشان داده شده در شکل ۱۹ ، نمونه ای از column stores است .

شکل ۱۹ : ساختارکلید در column family stores
برخلاف ، صفحه گسترده معمولی که ممکن است دارای ۱۰۰ سطر و ستون باشد ، column family store برای حجم بسیار بالایی از داده طراحی شده است . سیستم هایی با میلیاردها سطر و صدها یا هزاران ستون!
به عنوان نمونه یک برنامه GIS ( برگرفته شده از Geographic Information System ) نظیر Google Earth ممکن است از یک شناسنه سطر ( Row ID ) به عنوان طول جغرافیایی یک نقشه و از نام ستون به عنوان عرض جغرافیایی استفاده نماید . مثلا در یک نقشه برای هر مایل مربع ، می توان از ۱۵۰۰۰ شناسه سطر و ۱۵۰۰۰ شناسه ستون استفاده کرد . در صورت پیاده سازی یک سیستم GIS به کمک یک صفحه گسترده ، مشاهده می شود که تعداد اندکی از سلول ها حاوی داده می باشند .چیزی که این پیاده سازی را غیرمعمول می سازد این است که صرفا درصد اندکی از سلول ها حاوی اطلاعات می باشند . این نوع پیاده سازی مشابه ماتریس های sparse است که صرفا تعداد محدودی از ستون های آن دارای مقدار می باشند. متاسفانه ، بانک های اطلاعاتی رابطه ای برای ذخیره داده sparse مناسب نمی باشند ولی column stores برای پاسخ به اینگونه اهداف طراحی شده اند. در یک بانک اطلاعاتی رابطه ای ، می توان از یک query ساده برای یافتن تمامی ستون ها در هر جدولی استفاده کرد . در صورت اجرای یک query بر روی sparse matrix ، برای یافتن هر عنصر در بانک اطلاعاتی ، می بایست تمامی اسامی ستون ها را جستجو کرد . جستجوی تمامی ستون ها برای یافتن یک داده بخصوص و یا لیست تمامی داده بر اساس یک شرط خاص می تواند نتایج اغواکننده ای را نیز به دنبال داشته باشد.برای حل این نوع مسایل می توان از مفهوم column family استفاده کرد . به عنوان نمونه می توان ستون ها را به منظور تشریح یک وب سایت ، یک شخص ، یک مکان جغرافیایی و یا محصولات فروش رفته گروه بندی کرد. برای مشاهده این ستون ها با یکدیگر ، آنها را در column family مشابه گروه بندی می کنیم تا امکان بازیابی سریع آنها فراهم شود .
تمامی column family stores از یک column family به عنوان بخشی از کلید خود استفاده نمی کنند. در صورت استفاده ، می بایست آن را در محاسبات خود در زمان ذخیره یک کیلد در نظر گرفت . چراکه column family بخشی از کلید است و بازیابی داده بدون آن میسر نمی باشد.
مزایا و محدودیت های سیستم های column family
رویکرد column family با استفاده از یک شناسه سطر و نام ستون به عنوان یک کلید جستجو ، روشی انعطاف پذیر برای ذخیره داده است که دارای مزایای متعددی نظیر مقیاس پذیری ، در دسترس بودن و عدم از دست دادن زمان در هنگام اضافه کردن داده به سیستم است .با توجه به این که سیستم های Column family متکی به Join نمی باشند ، می توان به خوبی از آنها در سیستم های توزیع شده استفاده کرد . با این که می توان کار پیاده سازی را بر روی یک لپ تاپ شروع کرد ولی در نهایت کار استقرار را می توان بگونه ای پیکربندی کرد که داده را در سه ناحیه جغرافیایی مختلف ذخیره کرد( افزایش قابلیت در دسترس پذیری سیستم ) . سیستم های column family دارای امکانات اتوماتیکی برای برخورد با مشکلات و تشخیص گره های دارای مشکل و الگوریتم هایی برای شناسایی خرابی داده می باشند. Column family بگونه ای پیاده سازی شده است تا بتواند با سیستم فایل های توزیع شده (نظیر Hadoop ) و MapReduce کار کند. لازم است قبل از پیاده سازی به موارد فوق و نکات زیر دقت شود .
- مقیاس پذیری بالا : سیستم های column family به منظور کار با بیش از یک پردازنده طراحی شده اند و همین موضوع قابلیت مقیاس پذیری بالای آنها را نشان می دهد. این بدان معنی است که شما می توانید به هر میزان داده که لازم دارید به سیستم خود اضافه نمایید. در چنین مواردی می توان گره های جدید را به کلاستر محاسباتی اضافه کرد. به موازات رشد داده ، می توان تعداد پردازنده ها را نیز اضافه کرد. دلیل اصلی مقیاس پذیری این روش ، مدل ساده یی است که در آن از شناسه های سطر و اسامی ستون ها به منظور شناسایی یک سلول استفاده می گردد . در واقع با ایجاد و نگهداری یک اینترفیس ساده ، سیستم back end می تواند درخواست ها را بین تعدادی از گره های پردازش بدون انجام عملیات join توزیع نماید و از ترافیک غیرضروری پیشگری و کارآیی سیستم را افزایش دهد.
- در دسترس پذیری بالا : با ایجاد سیستمی که قادر به رشد در طول شبکه های توزیع شده باشد، می توان داده را بر روی چندین گره یک شبکه تکرار کرد . با توجه به این که سیستم های column family از ارتباطات موثر استفاده می نمایند ، هزینه تکرار پائین خواهد بود . علاوه براین ، فقدان عملیات Join اجازه می دهد که بتوان هر بخشی از ماتریس column family را بر روی کامپیوترهای راه دور ذخیره کرد . این بدان معنی است که اگر سرویس دهنده ای که بخشی از ماتریس sparse را ذخیره کرده باشد دچار مشکل گردد ، سایر کامپیوترها آماده ارایه سرویس داده می باشند .
- تسهیل در اضافه کردن داده : یکی از ویژگی های کلیدی Column family همانند key-value stores و Graph stores عدم ضرورت طراحی کامل مدل داده ، قبل از درج داده است .قبل از هر چیز می بایست گروه بندی column family مشخص گردد ولی شناسه های سطرها و اسامی ستون ها را می توان در هر زمانی ایجاد کرد.
علی رغم تمامی مزایای اشاره شده در رابطه با سیستم های Column family، این گونه سیستم ها جهت استفاده بر روی کلاسترهای توزیع شده به کار گرفته می شوند و مناسب بانک های اطلاعاتی کوچک نیستند . معمولا به حداقل پنج پردازنده جهت ایجاد یک کلاستر column family نیاز خواهید داشت.همچنین، سیستم های Column family از SQL query برای دستیابی بلادرنگ به داده استفاده نمی کنند . این گونه سیستم ها دارای یک زبان query در یک سطح بالاتر می باشند . از سیستم های Column family اغلب جهت تولید کارهای دسته ای MapReduce استفاده می شود . جهت دستیابی سریع به داده ، می توان از یک رابط برنامه نویسی سفارشی شده نوشته شده با یک زبان رویه ای نظیرجاوا یا Python استفاده کرد .
مثال ۱ : ذخیره اطلاعات تحلیلی توسط گوگل در BigTable
داده در Google Analytics نظیر سایر برنامه هایی از نوع logging ، معمولا یک مرتبه نوشته می شوند و هرگز بهنگام نمی شوند . این بدان معنی است که پس از استخراج و خلاصه کردن ، داده اولیه فشرده شده و در یک مکان ذخیره سازی میانی قرار می گیرد تا بایگانی شود . در مواردی که از HBase به عنوان محل ذخیره سازی BigTable استفاده می شود ، لازم است نتایج در HDFS ( برگرفته شده از Hadoop distributed filesystem ) ذخیره گردند و از یک ابزار گزارش گیری نظیر Hadoop Hive برای تولید خلاصه گزارشات استفاده شود . Hadoop Hive دارای یک زبان query است که در بسیاری موارد شبیه SQL کار می کند . مثال ۲ : ذخیره اطلاعات جعرافیایی گوگل مپ در BigTable
یک نمونه دیگر استفاده از BigTable برای ذخیره حجم بالایی از اطلاعات ، اطلاعات GIS است . سیستم های GIS نظیر Google map اطلاعات نقاط جغرافیایی زمین ، ماه و سایر سیارات را با شناسایی هر مکان با استفاده از مختصات طول و عرض جغرافیایی انجام می دهند . سیستم به کاربران اجازه می دهد بر روی زمین حرکت کرده و بر روی آن زوم نمایند . برای تسهیل کار با سیستم از اینترفیس های گرافیکی سه بعدی استفاده شده است . سیستم های GIS ، آیتم ها را یک مرتبه ذخیره می کنند و امکان دستیابی و مشاهده داده را به کمک مسیرهای مختلف فراهم می نمایند .
خلاصه
Cassandra, HBase, Hypertable, Apache Accumulo و Bigtable نمونه هایی از بانک های NoSQL می باشند که از الگوی معماری داده Column family استفاده می کنند . در بخش چهارم به بررسی الگوی معماری داده Document store خواهیم پرداخت .
بخش چهارم
بر اساس پیش بینی موسسه تحقیقاتی گارتنر تا سال ۲۰۱۷ ، تمامی پیشگامان ارایه دهنده سیستم های مدیریت بانک های اطلاعاتی ، اقدام به ارایه یک پلت فرم جامع جهت مدیریت بانک های اطلاعاتی می نمایند که مدل های داده مختلفی نظیر مدل های رابطه ای و NoSQL را شامل می شود .همچنین ، پیش بینی شده است که تا سال ۲۰۱۷ استفاده از واژه NoSQL به عنوان معیاری جهت تشخیص سیستم های مدیریت بانک اطلاعاتی بسیار کم رنگ خواهد شد . از منظر گارتنر ، یک سیستم نرم افزاری کامل که قادر به تعریف ، ایجاد ، مدیریت ، بهنگام سازی و اجرای query بر روی یک بانک اطلاعاتی باشد ، یک سیستم مدیریت بانک اطلاعاتی است . شکل ۲۰ ، جایگاه تولید کنندگان سیستم های مدیریت بانک اطلاعاتی عملیاتی را نشان می دهد که حضور شرکت های عرضه کننده محصولات NoSQL ( نظیر Couchbase ، MongoDB ) در آن قابل توجه است .
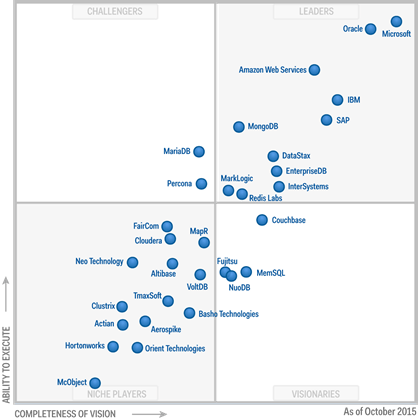
شکل ۲۰ : جایگاه تولیدکنندگان سیستم های مدیریت بانک های اطلاعاتی عملیاتی ( منبع : گارتنر – اکتبر ۲۰۱۵ )
با این که فناوری ها ، نوع های داده و کاربرد هر یک از اعضاء خانواده بزرگ NoSQL متفاوت است ولی می توان با صرفنظر کردن از برخی موارد خاص اینگونه بانک های اطلاعاتی را به چهار نوع مختلف Key-value stores ، Graph stores ، Column stores و Document stores تقسیم کرد . در بخش های گذشته با سه الگوی معماری داده Key-value ، Graph و Column family آشنا شدیم . در این بخش با Document stores آشنا خواهیم شد .
بانک های اطلاعاتی Document stores ،رکوردها را در قالب document ذخیره می کنند . یک document را می توان به عنوان گروهی از زوج های key-value تصور کرد . کلیدها همواره رشته می باشند و مقادیر می توانند رشته ، عدد ، مقادیر منطقی ، آرایه ها و یا سایر زوج های تودرتو key-value باشند. مقادیر می توانند تا هر عمق دلخواهی به صورت تودرتو تعریف گردند . در یک بانک اطلاعاتی document ، هر document مدل توصیفی مختص به خود را دارد .درست بر خلاف یک بانک اطلاعاتی رابطه ای که هر سطری در یک جدول بخصوص ، می بایست دارای ستون های مشابه باشد .CouchDB ، Couchbase و MongoDB سه محصول شناخته شده از بانک های اطلاعاتی Document stores می باشند .
مروری سریع بر الگوی معماری داده Document store
Key-value store و Bigtable values دارای فقدان یک ساختار رسمی می باشند و در عمل از ایندکسینگ و یا قابلیت های جستجو استفاده نمی کنند. Document stores چنین وضعیتی را ندارند و دقیقا در نقطه مقابل دو مدل فوق کار می کند : کلید ممکن است یک شناسه ساده باشد که هرگز استفاده و یا دیده نمی شود. ولی امکان بازیابی تقریبا هر آیتمی از درون یک document store از طریق یک query بر روی مقدار و یا محتویات وجود دارد. مثلا اگر یک query را بر روی ۵۰۰ سند مرتبط با ‘کشور ایران’ اجراء کینم و به دنبال مستنداتی باشیم که در آنها به ‘ استان خوزستان’ اشاره شده باشد ، ماحصل اجرای query ، برگرداندن لیستی از مستنداتی است که حاوی کلمه اشاره شده است .
Document stores ، از یک ساختار درختی که با یک گره ریشه شروع می شود و دارای شاخه هایی است که هر یک می توانند دارای شاخه های دیگری باشند، استفاده می نماید.مقادیر داده معمولا به عنوان برگ های یک درخت ذخیره می گردند.به موازات اضافه کردن یک سند جدید درون Document store ، برای هر آیتم ذخیره شده درون آن به صورت اتوماتیک ایندکس ایجاد می گردد. این بدان معنی است که با آگاهی از هر خصلت document ،می توان به سرعت تمامی سندهایی که دارای خصلت مشابه باشند را پیدا کرد. Document stores ، می تواند به شما نه تنها این موضوع را بگوید که آیا آیتم جستجو در document وجود دارد ، بلکه این توانمندی را نیز دارد که مکان واقعی آیتم را با استفاده از document path در اختیار شما قرار دهد .documet path در واقع یک نوع کلید است که به کمک آن امکان دستیابی به برگ های یک ساختار درختی فراهم می شود . شکل ۲۱ ، نحوه استفاده از یک ساختار درختی در Document stores را نشان می دهد
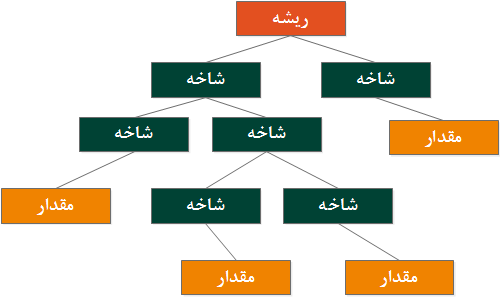
شکل ۲۱ : نحوه استفاده از یک ساختار درختی در Document stores
حتی اگر ساختار یک سند پیچیده باشد، فرآیند جستجو در document store می تواند با بکارگیری رابط برنامه نویسی (API ) ساده باشد. ساختار فوق ، روشی ساده برای انتخاب یک سند و یا زیرمجموعه ای از آن را ارایه می نماید . یک Key-value store قادر به ذخیره تمامی سند در بخش مقدار است ولی یک document store قادر به استخراج بخش های جانبی تعداد زیادی از اسناد بدون بارگذاری هر سند درون حافظه است . در صورتی که قصد نمایش یک پاراگراف بخصوص از یک کتاب را داشته باشیم ، لازم نیست تمامی کتاب را درون حافظه مستقر کرد .
در ادامه ، کار خود را با تصور document store به صورت یک ساختار درختی همراه با ریشه ها ، شاخه ها و برگ ها دنبال خواهیم کرد و در مرحله بعد به سراغ این موضوع خواهیم رفت که چگونه برنامه ها می توانند از مفاهیم document store و document store API استفاده می کنند و در نهایت نمونه مثال هایی در خصوص استفاده از document store را بررسی خواهیم کرد .
اصول اولیه الگوی معماری داده document store
Document collections
در مقابل ذخیره داده در سطرها و ستون ها در یک جدول ، داده در سندهایی ذخیره می گردد و این سندها در قالب کالکش هایی گروه بندی می شوند . هر سند می تواند دارای یک ساختار کاملا متفاوت باشد . اکثر document stores ، مستندات را در گروه هایی با نام کالکشن گروه بندی می کنند . شکل ۲۲ ، تفاوت مدل داده رابطه ای با مدل داده مبتنی بر Document را نشان می دهد .

شکل ۲۲ : تفاوت مدل داده رابطه ای با مدل داده مبتنی بر Document
این کالکشن ها شبیه یک ساختار دایرکتوری می باشند که نظیر آنها را می توان در سیستم فایل ویندوز و یا لینوکس پیدا کرد. از کالکشن ها می توان به روش های مختلفی برای مدیریت حجم بالایی از مستندات استفاده کرد . می توان از آنها به عنوان مکانیزمی برای حرکت در ساختار سلسله مراتبی مستندات ، گروه بندی منطقی مستندات مشابه و ذخیره قواعد کسب و کار نظیر مجوزها ، ایندکس ها و تریگرها استفاده کرد . کالکشن ها می توانند شامل سایر کالکشن ها و درخت ها نیز باشند. کالکش های مستندات را می توان به عنوان کالکشن های برنامه نیز استفاده کرد که چارچوبی برای ذخیره داده ، اسکریپت ها ، views و تبدیلات یک برنامه نرم افزاری را ارایه می نمایند .
Application collections
Document store APIs
هر document store دارای یک API و یا query language است که مسیر هر گره و یا گروهی از گره ها را مشخص می کند . در حالت کلی ، لازم نیست گره ها دارای اسامی منحصربفرد باشند در مقابل ، می توان از یک عدد مکان یاب جهت مشخص کردن هر گره دلخواه در درخت استفاده کرد. مثلا ، برای انتخاب هفتمین فرد در لیست افراد ، می توان این query را اجراء کرد . [Person[7 . شکل ۴ ، نحوه استفاده از یک document path به عنوان کلیدی برای استخراج مقدار ذخیره شده در یک سلول بخصوص یک سند را نشان می دهد .
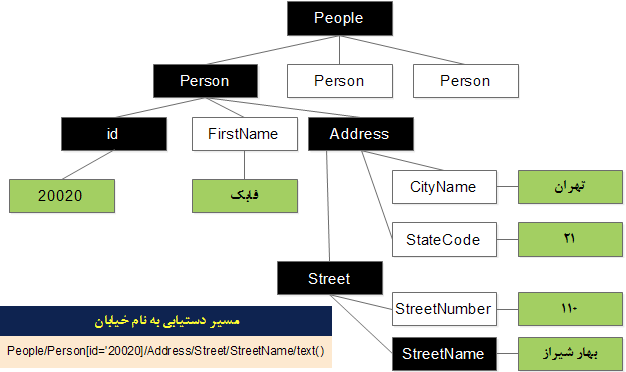
شکل ۲۳ : نحوه استفاده از document path به عنوان کلید جهت استخراج مقدار ذخیره شده در یک سلول بخصوص
در شکل ۲۳ ، با انتخاب مجموعه ای از رکوردهای افراد که دارای شناسه ۲۰۰۲۰ می باشند، کار را شروع می کنیم . اغلب این شناسه به یک شخص اشاره خواهد داشت . در ادامه ، نگاهی خواهیم داشت به رکورد بخش آدرس و متن را از نام خیابان انتخاب می کنیم . مسیر کامل جهت دسترسی به نام خیابان در ذیل شکل ۴ نشان داده شده است .
پیاده سازی Document store
مثال : یک سرویس دهنده تبلیغاتی با MongoDB
اولین دلیل حضور MongoDB به عنوان یک محصول NoSQL ، ایجاد سرویسی بود تا بتوان به سرعت یک بنر تبلیغاتی را بر روی یک صفحه وب برای میلیون ها کاربر در یک لحظه ارسال کرد .هدف اولیه ، انتخاب سریع تبلیغات مناسب برای یک کاربر خاص و قراردادن آن بر روی صفحه در زمان بارگذاری توسط کاربر است . سرویس دهنده تبلیغاتی می بایست هر روز ۲۴ ساعت و هفت روز هفته بدون بروز مشکل بتواند سرویس خود را ارایه نماید. آنها از قواعد پیچیده کسب و کار به منظور یافتن مناسب ترین تبلیغ و ارسال آن برای یک صفحه وب استفاده می کنند . تبلیغات از یک بانک اطلاعاتی دریافت می شوند که متناسب با علایق هر شخص سازماندهی شده اند. میلیون ها تبلیغات این ظرفیت را دارند که بتوانند با علایق کاربر مطابقت نمایند . سرویس دهنده تبلیغاتی نمی تواند تبلیغ مشابهی را بطور تکراری برای افراد ارسال کند و می بایست قادر به ارسال تبلیغات در یک ناحیه خاص بر روی صفحه و با یک اولویت بخصوص باشد . در نهایت ، سیستم به گزارشات صحیح نیاز دارد تا نشان دهد که چه تبلیغاتی برای کدام کاربر ارسال شده است و کاربر بر روی کدام تبلیغ کلیک کرده است. این مساله کسب و کار نشان داد که نمی توان از RDBMS استفاده کرد چراکه هم پیچیده است و هم نیازمند ارسال داده به صورت real time است . MongoDB ثابت کرد که می تواند تمامی خواسته های موجود دراین زمینه را پاسخگو باشد . MongoDB دارای امکاناتی از قبیل پارتیش بندی اتوماتیک ، تکرار ، load balancing ، file storage و تجمیع داده است . به همین منظور از ساختار document store برای پیشگری از افت عملکرد استفاده گردید . از MongoDB در موارد متعددی می توان استفاده کرد:
- مدیریت محتوا : ذخیره محتویات وب ، تصاویر و استفاده از ابزارهای لازم جهت ایندکس و یافتن آیتم ها
- عملیات هوشمند real time : به عنوان نمونه مانیتورینگ رسانه های اجتماعی
- مدیریت داده محصول : ذخیره و اجرای query پیچیده بر روی داده محصولات
- مدیریت داده کاربر : ذخیره و اجرای query بر روی داده مرتبط با کاربر در برنامه های بزرگی نظیر بازهای ویدیویی ، برنامه های شبکه های اجتماعی
- تغذیه حجم بالای داده : ذخیره حجم بالایی از داده real time درون یک بانک اطلاعاتی مرکزی برای انجام تحلیل های متمرکز و …
شکل ۲۴ ، نحوه پیاده سازی جدول Users یک بانک اطلاعاتی رابطه ای را با MongoDB نشان می دهد . جدول به یک collection ، هر سطر در جدول SQL به یک document و هر ستون به یک فیلد در MongoDB تبدیل شده است .
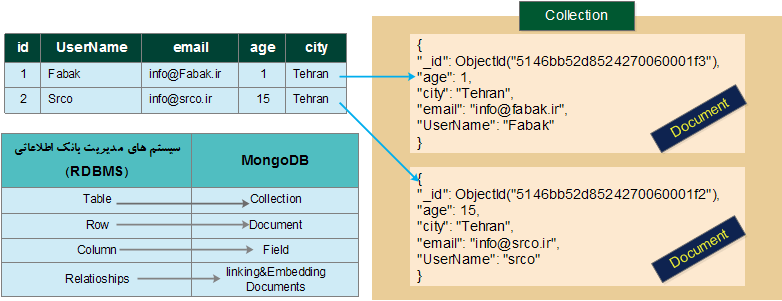
شکل ۲۴ : نحوه پیاده سازی یک جدول رابطه ای در MongoDB
خلاصه
در این بخش با نوع چهارم الگوی معماری داده NoSQL آشنا شدیم . ساختار درخت گونه این نوع معماری توانسته است این معماری را به یکی از قوی ترین و انعطاف پذیرترین مدل ها در نوع خود تبدیل کند . داده در ساختارهای سلسله مراتبی تودرتو ذخیره می گردد و هر داده موجود در یک document را می توان با اجرای query مورد نظر بازیابی کرد ( یک راه حل ایده آل برای جستجو ) . MongoDB یکی از محصولاتی است که از این معماری به خوبی استفاده می کند و توانسته است به عنوان یکی از مهم ترین محصولات در حوزه داده های عظیم مطرح گردد .