
دریاچه داده به عنوان بستر حکمرانی داده در سازمان
مقدمه
در سه دهه اخیر که فناوری اطلاعات به تدریج از یک کالای لوکس در سازمانها به یک نیاز ضروری و محور تمامی فعالیتها تبدیل شد، حجم محدود داده و نرخ پایین تولید آن در یک سازمان، نیاز به سیاستگذاری و راهبری داده را چندان محسوس نشان نمیداد. در چند سال اخیر و به مدد رشد شبکه های اجتماعی، گوشیهای هوشمند، حسگرهای مختلف، برچسب های RFID و سایر فناوریهای حوزه اینترنت اشیاء، دوربینهای نظارتی، صفحات وب و نیز توسعه نرم افزارهای سازمانی، نرخ تولید داده و به تبع آن حجم داده های یک سازمان با جهشی عظیم مواجه شده است؛ داده هایی که علاوه بر نیاز به ذخیره و پردازش، نیازها و ضرورتهای جدیدی را هم با خود به ارمغان آورده اند.
داده ها چگونه ذخیره شوند، چگونه در دسترس افراد مناسب قرار گیرند، چگونه کیفییت آنها کنترل شود، با چه ابزارهایی آنها را تحلیل کنیم و مسائلی از این دست باعث به وجود آمدن شاخه جدیدی در علم داده با نام «حکمرانی یا راهبری داده[۳]» شده است. هرچند راهبری داده به مسائل مدیریتی داده میپردازد اما زمانی میتوان به سیاستگذاری و مدیریت موثر داده اقدام کرد که نحوه جمع آوری و پردازش داده در سازمان بر اساس یک معماری مدرن و مبتنی بر کلان داده با درنظر گرفتن تمامی نیازهای فعلی و آتی سازمانی، شکل گرفته باشد یعنی بستر لازم برای راهبری داده فراهم شده باشد.
دریاچه داده با چنین هدفی پا به عرصه وجود نهاد تا علاوه بر ذخیره داده به صورت خام و بدون تغییر، بستری برای پردازش آن و اعمال سیاستگذاریهای مختلف، فراهم کند.
در این مقاله ابتدا به مفاهیم پایه حکمرانی یا راهبری داده خواهیم پرداخت و چارچوبها و مدلهای موجود آن را بررسی خواهیم نمود. سپس به معماریهای نوین اطلاعاتی در دنیای کلان داده اشاره خواهیم کرد و نقش دریاچه داده را آنها مشاهده خواهیم نمود. رابطه بین دریاچه داده و راهبری داده را موشکافی کرده و سرآخر، به چالش های مطرح در حوزه راهبری داده در عصر کلان داده خواهیم پرداخت.
تعاریف و مفاهیم پایه راهبری / حکمرانی داده
راهبری داده به فرآیند مدیریت و راهبری داده در یک سازمان اشاره دارد و با اعمال آن در یک حوزه، تمامی داده ها و اطلاعات بر اساس روالها و استانداردهای راهبری داده سازمان، تولید، مصرف و ذخیره خواهند شد. این مفهوم را در تعریف موسسه ملی استاندارد و فناوری آمریکا(Technology 2015))، به خوبی مشاهده میکنیم :
حکمرانی داده به فرآیند اداره کردن یا استاندارد سازی تمام امور مربوط به مدیریت داده اطلاق میشود.
ویکی پدیا به عنوان یک دائره المعارف غیر رسمی، راهبری داده را «فرآیندی تعریف شده میداند که یک سازمان برای تضمین کیفیت داده در تمامی چرخه حیات داده، آنرا به کار می برد» (Wikipedia,2017) .
انستیتوی راهبری داده(DataGovernanceInstitue 2017)، تعریفی جامع تر را برای این حوزه نوین مدیریتی ارائه کرده است :
راهبری داده از قوانین تصمیم گیری و اعمال انضباط کاری برای تمام فرآیندهای مرتبط با اطلاعات تشکیل شده است که براساس مدلهای توافق شده و از پیش تعیین شده کار میکند و تعیین میکند چه کسی، چه کاری را، روی چه دادهای، در چه زمانی و تحت چه شرایط و با استفاده از کدامین روش باید انجام بدهد.
همانطور که مشاهده میشود وجود یک فرآیند از پیش تعیین شده که در تمامی فرآیندهای اطلاعاتی سازمان، اعمال شود و سازگاری و جامعیت و کیفیت داده ها را تضمین کند، نکته اصلی در راهبری داده در یک سازمان است.
عبارت «data governance» در فارسی به صورت مصطلح به «حکمرانی داده» ترجمه شده است اما از لحاظ بار معنایی عبارت «راهبری داده» یا «حکمرانی بر داده» یا «فرمانش داده» مناسب تر به نظر میرسد (فرمانش داده در پنجمین کنفرانس مدیران فناوری اطلاعات مطرح شد) و در این مقاله هم به جای حکمرانی داده، عبارت راهبری داده را استفاده خواهیم کرد. در حقیقت برای حکمرانی داده در سازمان، به راهبری آن نیاز خواهیم داشت.
مولفه های مدیریت داده در سازمان
از آنجا که راهبری داده ارتباط تنگاتنگی با مدیریت داده در سازمان دارد، بهتر است با مولفه های مدیریتی داده که راهبری داده در تمامی آنها اعمال خواهد شد، آشنا شویم. برای این منظور از راهنمای پیشنهادی «انجمن مدیریت داده» در حوزه مدیریت داده استفاده میکنیم(DAMA-Association 2017). این راهنما که در حال حاضر نسخه ۲ آن منتشر شده است، به صورت شماتیک این مولفه ها را بیان کرده و به توضیح تک تک آنها پرداخته است. اجزای تشکیل دهنده مدیریت داده طبق این راهنما از قرار زیر است:
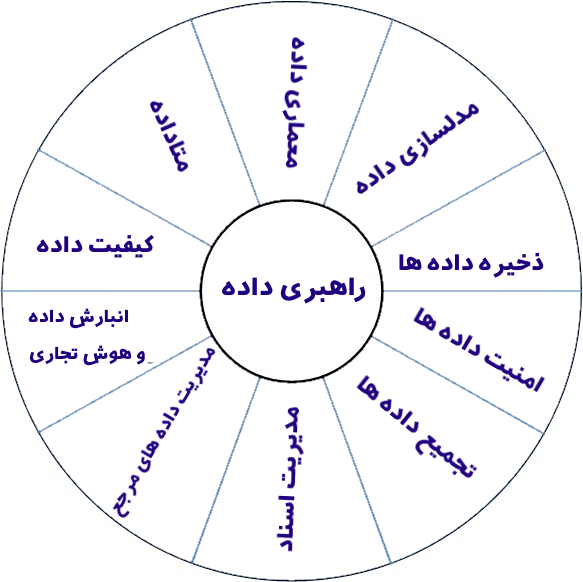
- راهبری داده : این بخش از مدیریت داده که نقش هماهنگ کننده و محوری را در تمامی فعالیت های دادهای یک سازمان دارد، نقش سیاستگذار و کنترل کننده را داشته و به نوعی تضمین کننده یکپارچگی و جامعیت پردازش داده در یک سازمان است.
- مدیریت کیفیت داده : قوانین تضمین کننده کیفیت داده در این بخش قرار میگیرند. مواردی مانند دقت و سازگاری داده ها و قوانینی که حتما باید به ازای هر موجودیت داده حفظ شود. به عنوان مثال، قوانین سازگاری و جامعیت برای دانشجو حاکی از این هستند که یک دانشجو حداکثر در هر ترم ۲۴ واحد درسی باید داشته باشد و حداقل هم ۱۲ واحد مگر در شرایط فارغ التحصیلی . این قوانین که خیلی از آنها هنگام پیش پردازش داده، ذخیره و به روزرسانی، اعمال میشوند، تضمین کننده کیفیت داده در سازمان خواهند بود.
مدیریت داده های راهنما[۴] – فراداده ها : داده های راهنما، در حقیقت «داده هایی توصیف کننده راجع به داده ها» هستند که جدای از داده های اصلی باید نگه داشته شوند. مثل اینکه یک داده، درچه تاریخی و توسط چه کسی ذخیره یا ویرایش شده است.
- مدیریت اسناد و محتوای بدون ساختار : بسیاری از داده های امروزی سازمان، مانند عکس ها، فیلم ها، صفحات وب و اخبار، فایلهای لاگ سرورها و مانند آن، درون بانکهای اطلاعاتی ذخیره نمیشوند و باید سیاستهای جداگانهای برای هر این نوع از داده ها در پیش گرفت. نحوه ذخیره، جستجو، شاخص گذاری، دسترسی و همچنین تعامل آنها با سایر داده های رابطه ای و ساختارمند سازمان در این بخش مشخص میگردد.
- طراحی و مدلسازی داده : تحلیل نیازمندیهای سازمان و شناسایی منابع دادهای جدید و طراحی مدل های داده موردنیاز و توضیع قوانین لازم برای ذخیره و جستجوی آنها در این بخش، لحاظ خواهند شد.
- انبارش داده[۵] و هوش تجاری : نیازمندیهای تحلیل و گزارشگیری از داده ها و ساخت انباره داده و فراهم آوردن زیرساخت لازم برای گرفتن تصمیمات مدیریتی در این مولفه از مدیریت داده، دیده شده است.
- مدیریت داده های مرجع : داده های مرجع (Master Data) به داده هایی گفته میشود که موجودیت های داده ای یک سازمان را تعریف میکنند و تمامی بخش های سازمان مکلفند کار با داده های خود را آن تطبیق دهند. به عنوان مثال، در فایل مرجع، توصیف کارمند و خصوصیات آن با ذکر جزییات آن مانند نحوه محاسبه سابقه کار، مرخصی، ماموریت و … آورده میشود و هر بخش از سازمان که نیاز به ذخیره و تعریف و کار با موجودیت کارمند داشته باشد، باید با قوانین و توصیف موجود در این فایل، مطابق باشد.
- مدیریت امنیت داده : جنبه مهم دیگر از مدیریت داده که یک استراتژی درست راهبری داده، باید حتما برای آن برنامه داشته باشد، بحث امنیت داده هاست. این که چه کسانی، تحت چه شرایطی ، در چه زمان هایی به کدامین داده ها دسترسی دارند از جمله مواردیست که در این بخش باید به آن رسیدگی شود. نحوه مقابله با حوادث داده ای مانند خراب شدن دیسک یا از کارافتادن شبکه، دزدی و هک شدن داده ها هم در این قسمت، چاره اندیشی میشود. عبارت «نظارت بر مصرف داده[۶]» یا «داده بان» هم که در ادبیات مدیریت داده به کار میرود (Rosenbaum 2010))، به این مولفه مهم اشاره دارد.
- مدیریت ذخیره داده : نحوه مدیریت فضای مورد نیاز برای داده های رابطه ای و نحوه پشتیان گیری، توزیع در شبکه و تقسیم بار بین گرههای محاسباتی حاوی یک بانک اطلاعاتی، از سیاستهای تعیین شده در این بخش است. دریاچه داده، در این بخش به سرویس دهی خواهد پرداخت.
- مدیریت معماری کلان داده ها در سازمان : معماری کلان داده در سازمان و ساختار آن در این قسمت، قرار میگیرد که در ادامه مقاله با جزییات بیشتری در مورد آن صحبت خواهیم کرد.
- تجمیع داده ها و تعیین چارچوب تعامل : نحوه تعامل بین منابع مختلف داده ای، نحوه جمع آوری داده های آنها، چگونگی ترکیب کردن و یکپارچه کردن آنها و تعیین مکانیزم هایی برای تعامل و استفاده برنامه های مختلف از داده های یکدیگر، در این بخش مورد بازبینی قرار میگیرد. دریاچه داده به عنوان یک راه حل برای تجمیع داده های مختلف که بسترساز تمامی فعالیت های بعدی سازمان بر روی داده هاست، مبحث اصلی این مقاله است که در ادامه توضیح داده خواهد شد.
ده مورد فوق، حوزه های اصلی مدیریت داده سازمانی در حال حاضر هستند و با پیشرفت فناوری و نرخ تغییر و سرعت تولید داده های جدید، در سالیان آینده به این موارد ، اقلامی اضافه شده و برخی نیز مورد بازبینی قرار خواهند گرفت.
فرآیند راهبری داده و چارچوبهای موجود
همانطور که تا اینجا مشاهده کردیم، راهبری داده، حوزه های وسیعی را در برمیگیرد و برای اینکه بتوان آنرا در یک سازمان پیاده سازی کرد، نیاز به یک فرآیند دقیق و جامع که در برگیرنده تمام حوزههای مدیریت داده باشد، داریم. با رواج استفاده سازمانها از داده های مختلف و استفاده بسیاری از سازمانها از ابزار و راه حلهای کلان داده در ذخیره و پردازش داده های خود که ناظر بر بلوغ فناوریهای کلان داده دارد، نیاز به مدیریت یکپارچه داده به یک ضرورت نوین تبدیل شده است به گونه ای که برخی مستندات (Oracle 2016)، سال ۲۰۱۷ را سال راهبری داده سازمانی معرفی کرده اند.
بنابراین در چند سال اخیر، چارچوبها و فرآیندهای مختلفی برای راهبری داده سازمانی، پیشنهاد شده اند که البته تنوع زیادی داشته و هنوز همگرا و نهایی نشده و به بلوغ کامل نرسیده اند اما با این وجود، چهارچوب کلی زیر را که توسط (Karel 2014) پیشنهاد شده است و با دیدی کلان، فرآیندی چهار مرحلهای را برای پیاده سازی راهبری داده در سازمان پیشنهاد میکند که میتواند مبنای اولیه کار در این حوزه قرارگیرد.
از آنجا که این مقاله، به طور خاص به راهبری داده با جزییات کامل، نمیپردازد به همین مقدار بسنده میکنیم. علاقه مندان میتوانند به مقالات (DeStefano and Gai 2016)، (Al-Ruithe, Benkhelifa et al. 2016) و (Wende 2007) مراجعه کنند.
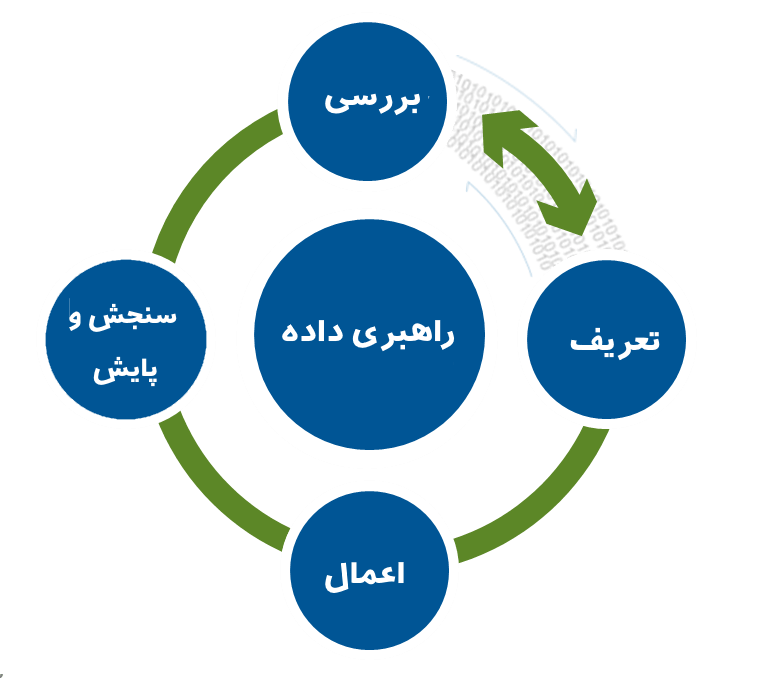
شکل ۲ – فرآیند کلی راهبری داده (Karel 2014)
همانطور که مشاهده میکنید این فرآیند از چهار قسمت اصلی تشکیل شده است که برای پیاده سازی راهبری داده در یک سازمان، اقداماتی به ترتیب زیر باید انجام دهیم :
- کاوش و بررسی : وضعیت فعلی سازمان از لحاظ مدیریت داده و فرآیندهای درگیر تولید، پردازش واستفاده از داده، مشخص شده، مستند میشود. این مرحله ارتباط تنگاتنگی با مرحله تعریف استانداردها و سیاستها که فاز دوم این فرآیند است، دارد و مکمل و پیشران آن محسوب میشود.
- تعریف روالها، استانداردها و سیاستها : در این مرحله که نقش حیاتی را در فرآیند راهبری داده ایفا میکند، سیاستها، روالها و استانداردهای مختلف کار با داده طبق حوزه هایی که در بخش قبلی به آنها اشاره کردیم، مشخص میشود. در حین تعریف این سیاستها، نیاز به کاوش و بررسی دقیقتر حوزه های کار داریم که درشکل هم رابطه بین این دو بخش، دو طرفه منظور شده است.
- پیاده سازی : در این مرحله، با تشکیل یک تیم مناسب، به پیاده سازی استانداردها و روالها در سازمان میپردازیم و با بررسی تک تک روالها و فعالیتهای سازمان، نحوه تطابق و اعمال این سیاستها را در آن بخش، مشخص کرده و آنرا به انجام میرسانیم.
- سنجش و پایش : در این مرحله، بعد از پیاده سازی روالها و سیاستهای راهبری داده در سازمان، به سنجش مداوم فعالیتها و بررسی تطابق آن با استراتژی راهبری داده سازمان میپردازیم و در صورت یافتن مشکل یا عدول از سیاستها، راه چارهای برای حل آن به سرعت مییابیم .
همانطور که مشاهده میکنید این فرآیند چهار مرحله ای، وارد جزییات نشده است و فقط به صورت کلی، روالی منظم را برای پیاده سازی راهبری داده در سازمان پیشنهاد میکند.
دریاچه داده، راهکار سازمانی تجمیع داده ها
یکی از مسائل مهم در حوزه راهبری داده، وجود یک معماری مشخص و جامع در مدیریت ذخیره و پردازش داده ها است به گونه ای که تمام نیازهای فعلی و آتی سازمان در آن دیده شده باشد. این که داده های ساختیافته و غیرساختیافته، چگونه ذخیره شوند، چه موتور و کتابخانه پردازشی کلان داده در سازمان استفاده شود، برای یادگیری ماشین چه ابزاری استفاده شود، داده های جریانی و مداوم مانند داده های شبکه های اجتماعی، چگونه پردازش شوند و مسایل کلانی از این دست که امروزه به مدد رشد و بلوغ فناوریهای کلان داده، راه حلهای زیادی را برای تعریف و طراحی معماری یک سازمان با در نظرگرفتن تمامی نیازهای اطلاعاتی دنیای معاصر در اختیار مدیران فناوری اطلاعات نهاده است.
شکل زیر نمایی از یک معماری پیشنهادی توسط (۴۵۱ResearchGroup 2016) را نشان میدهد :
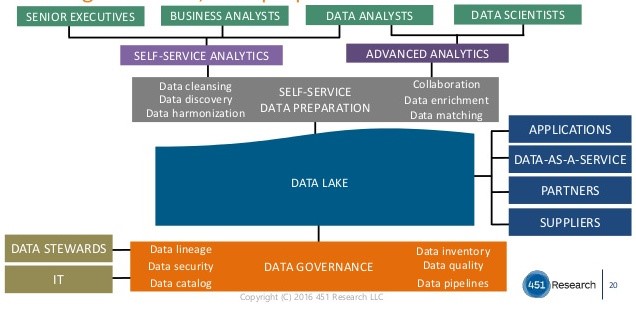
در این معماری، راهبری داده را در کنار دریاچه داده میبینید که به آن خواهیم پرداخت. معماری دیگری که توسط (blue-granite 2017) پیشنهاد شده است، ساختار زیر را دارد :
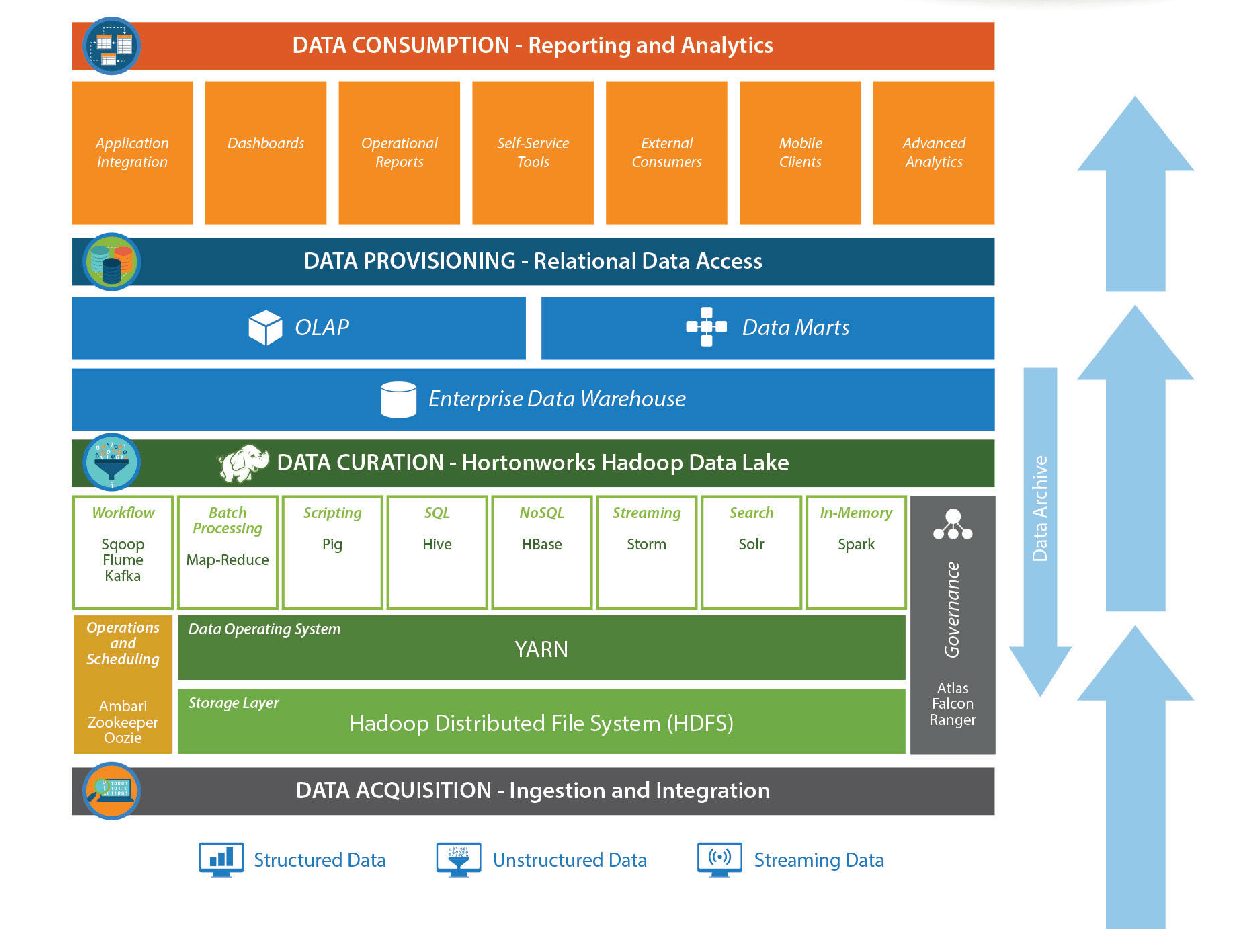
در این معماری که به عنوان یک معماری مرجع با استفاده از فناوری های کلان داده و توزیع تجاری معروف هدوپ یعنی توزیع هدوپ شرکت HortonWorks طراحی شده است، بخش مهم ذخیره و دسترسی داده آن تحت عنوان Data Curation از روی معماری دریاچه داده این شرکت، طراحی شده است. اگر کمی دقیقتر به آن نگاه کنید، بخش راهبری داده را در کنار تمامی این فناوریهای موجود در دریاچه داده خواهید دید که مجددا نشان میدهد اعمال سیاستهای راهبری داده، کاملاً وابسته به دریاچه داده یک سازمان است. اما دریاچه داده چیست ؟
در سال ۲۰۱۰ آقای جیمز دیکسون با تشبیه انباره های داده یک سازمان به بطریهای آب آشامیدنی که برای یک مقصود خاص تولید شده اند و مقایسه آنها با یک دریاچه آب که میتوان انواع کارها را به کمک آن انجام داد مانند آبیاری، قایقرانی، ماهیگیری و غیره ، مفهومی را با نام دریاچه داده معرفی کرد که در آن، تمامی داده ها به شکل اصلی وخام خود ذخیره میشوند و سپس برای هر کاربرد، از این مخزن داده، واکشی و به قالب مورد نظر تبدیل میشوند (John and Misra 2017) ).
این مخزن داده یا همان دریاچه داده میتواند ترکیبی از بانکهای اطلاعاتی رابطهای و پایگاهداده های NoSQL و قالب های رایج ذخیره داده در اکوسیستم هدوپ (بستر نرم افزاری کلاسیک کلانداده) مانند HDFS، Parquet، ORC و AVRO باشد.
در یک دریاچه داده، داده به صورت خام و بدون پردازش ذخیره میگردد و هر کاربرد، قالب مورد نظر را روی این داده های خام اعمال خواهد کرد. این امر باعث میشود بستری برای پردازش های آینده هم فراهم شود.
دریاچه داده بسترساز راهبری داده
زمانی خواهیم توانست سیاستهای نظارتی و کنترلی را بر روی داده های سازمان پیاده سازی کنیم که داده ها طبق اصول و استانداردی ذخیره و مورد دستیابی قرار گیرند. دریاچه داده که امروزه به مفهومی اساسی در کلان داده تبدیل شده است و شرکتهایی بزرگی مانند مایکروسافت، گوگل و آمازون به ارائه آن به سازمانها از طریق بستر رایانش ابری هم مبادرت ورزیده اند، این نیاز به ذخیره یکپارچه داده ها را برطرف میکند.
ساختار دریاچه های داده به گونه ای طراحی شده است که پذیرای هر نوع داده با هر سرعت تولیدی باشد و از طرفی حجم بالای داده هم در آن تاثیری نداشته باشد و کاملا مقیاس پذیر باشد. موارد امنیتی هم برای داده های در حال حرکت و داده های ذخیره شده هم در آن لحاظ شده است. بنابراین انتخاب یک راه حل دریاچه داده برای یک سازمان، نه تنها بستری برای اعمال هماهنگ سیاستها را فراهم میکند، بلکه بسیاری از دغدغه ها و سیاستهایی که توسط تیم راهبری سازمان تعریف شده و نیاز به پیادهسازی دارد، به طور خودکار پیاده سازی و از قبل موجود است. مواردی مانند توزیع پذیری و تحمل خطا، سیاستهای امنیتی، نحوه تجمیع و ارتباط بین منابع داده در این دریاچه های داده از قبل لحاظ شده است و تنها نیاز به سفارشی سازی خواهد داشت که آن هم بر اساس روالها و استانداردهای راهبری داده، قابل انجام خواهد بود .
روند گرایش دو عبارت دریاچه داده و نیز راهبری داده در گوگل، نشانگر رشد تقریبا همگام این دو فناوری و رواج بیشتر گرایش به سمت دریاچه داده در سالیان اخیر است.
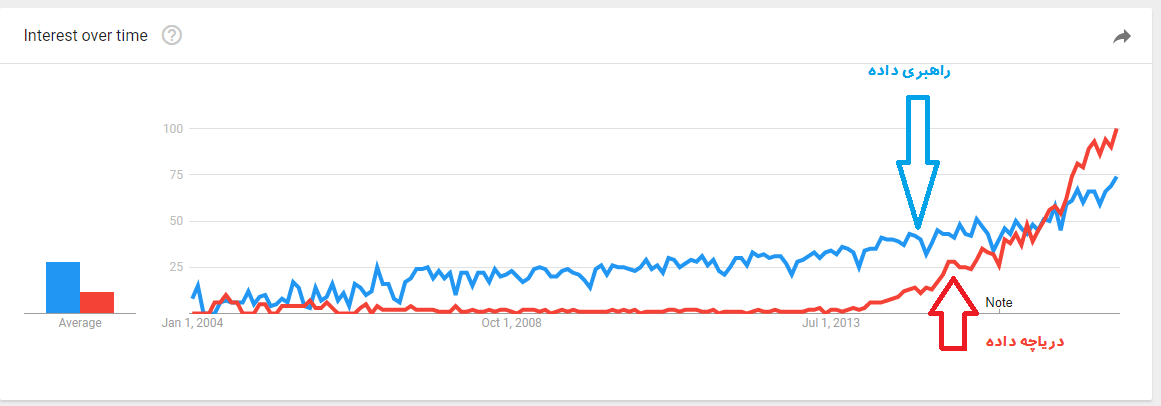
چالشها و ملاحظات
مانند بسیاری از فناوریهای نوینی که پابه عرصه حیات میگذارند و تا رسیدن به بلوغ و تکامل لازم، خطاها و محدودیت هایی را به سازمانها تحمیل میکنند، هر دو فناوری دریاچه داده و راهبری داده، کاملاً جوان و نورس هستند و استفاده از آنها در سازمانها، علاوه بر اینکه تطبیق سازمان و تربیت افرادی متخصص در این زمینه ها، امری زمانبر است، ممکن است چالشهایی هم به همراه داشته باشد.
از طرفی صرف ذخیره داده ها در دریاچه داده بدون اتخاذ سیاستهای مناسب و راهبری درست، باعث بوجود آمدن باتلاق داده در یک سازمان میگردد. منظور از باتلاق هم حجمی از داده بدون استفاده است که روزبروز حجم آن اضافه میگردد و مدیریت آنرا سخت تر کرده، هزینه نگهداشت آنرا بالا میبرد بدون اینکه استفاده مناسبی از آن به عمل آید که این امر هم نهایتاً نگاه مدیران را به این فناوریها منفی خواهد کرد.
وجود نرم افزارهای مختلف که توسط تولیدکنندگان مختلفی هم توسعه داده شده وپشتیبانی میشوند، از دیگر چالش های این حوزه برای پیادهسازی دریاچه داده و نیز راهبری یکپارچه داده در سازمانها خواهد بود که راهکار میان مدت آن، طراحی بانک اطلاعاتی جامع بر اساس مولفه های درنظر گرفته شده در دریاچه داده و طراحی مکانیزمی برای انتقال مداوم بین داده های موجود در بانکهای اطلاعاتی مختلف سازمان به این بانکهای اطلاعاتی یکپارچه خواهد بود.
بومی شدن فناوریهای حوزه داده بخصوص مباحث مدیریتی آن و وجود شرکتهایی برای دادن مشاوره درخصوص مباحث نوین داده مانند کلان داده، دریاچه داده و راهبری داده، امری ضروری به نظر میرسد که خلا آن در کشور به خوبی محسوس است.
سخن نهایی
وجود داده در سازمانهای ایرانی، امری است که به عنوان یک اصل پذیرفته شده است اما استفاده درست و موثر از این داده ها در جهت تصمیمات کلان مدیریتی و بهبود روندهای یک سازمان و خلق ارزش از داده نیازمند اتخاذ سیاستهای درست مدیریتی در حوزه داده است.
درونی شدن مفهوم راهبری داده در سازمان، نیازمند عزمی جدی هم از سمت متولیان دولتی این امر و هم از سمت مدیران فناوری اطلاعات است . نامیده شدن سال ۹۶ در وزارت علوم به سال «حکمرانی داده» ، خبر خوشی است که نشانگر درک این دغدغه در بین مدیران کلان کشور میباشد. در ادامه نیازمند تعریف استاندارد مدیریت و راهبری داده ها در سازمانهای دولتی توسط سازمانهای متولی مانند سازمان فناوری اطلاعات ایران هستیم.
با کاربردی شدن راهبری داده در سازمانها و ادارات، می توانیم نتایج زیر را در درازمدت شاهد باشیم :
- تصمیمات در سازمان، تماماً داده محور و مبتنی بر داده های تحلیل شده و یکپارچه خواهد بود.
- با یکپارچه شدن داده ها، زمینه برای اعمال انواع الگوریتم های یادگیری ماشین فراهم شده، شاهد رونق سازمانهای هوشمند خواهیم بود.
- با شناسایی نقاط ضعف روالها و بررسی دقیق داده ها، شاهد افزایش بهره وری خواهیم بود.
- مباحث امنیتی با اعمال در تمامی لایههای تولید و توزیع داده، به صورت کامل رعایت شده، از نشت اطلاعاتی به صورت اصولی جلوگیری خواهد شد.
با این وجود، همانطور که اشاره شد، وجود سیاستهای راهبری داده باید به دغدغه تمام مدیران فناوری اطلاعات کشور تبدیل شود و برای اینکه هر چه سریعتر و با آرامش بیشتر این امر محقق گردد، دریاچه داده به عنوان بسترساز اعمال این سیاستها در یک سازمان و تسهیل کننده آن، میتواند فرآیند تطبیق و درونی سازی راهبری داده در یک سازمان را سرعت زیادی ببخشد.
منابع و مراجع
- . “Data governance.” 2017, from https://en.wikipedia.org/wiki/Data_governance.
- ۴۵۱ResearchGroup (2016). Sink or swim? Governance and preparation are key to a functional ‘data lake’.
- Al-Ruithe, M., et al. (2016). “A Conceptual Framework for Designing Data Governance for Cloud Computing.” Procedia Computer Science 94(Supplement C): 160-167.
- blue-granite (2017). DATA LAKES IN A MODERN DATA ARCHITECTURE.
- DAMA-Association (2017). DAMA-DMBOK: Data Management Body of Knowledge Technics Publications.
- DataGovernanceInstitue (2017). “The DGI Data Governance Framework.” 2017, from http://www.datagovernance.com/the-dgi-framework/.
- DeStefano, R. J. and L. T. a. K. Gai (2016). Improving Data Governance in Large Organizations through Ontology and Linked Data. 2016 IEEE 3rd International Conference on Cyber Security and Cloud Computing (CSCloud), Beijing, China.
- John, T. and P. Misra (2017). Data Lake for Enterprises, Packt Publishing.
- Karel, R. (2014). “The Process Stages of Data Governance.” Retrieved 2017/10/20, 2017, from https://blogs.informatica.com/2014/01/02/the-process-stages-of-data-governance/#fbid=EXG3shZfrVe.
- Oracle (2016). Enabling the Agile Enterprise: Driving Digital Transformation via Data Governance.
- Rosenbaum, S. (2010). “Data Governance and Stewardship: Designing Data Stewardship Entities and Advancing Data Access.” Health Services Research 45(5p2): 1442-1455.
- Technology, N. I. o. S. a. (2015). NIST Big Data Interoperability Framework: Volume 1, Definitions. USA, National Institute of Standards and Technology.
- Wende, K. (2007). A Model for Data Governance – Organising Accountabilities for Data Quality Management. 18th Australasian Conference on Information Systems. M. Toleman, A. Cater-Steel and D. Roberts. Toowoomba, Australia, The University of Southern Queensland: 417-425.
[۱] smbanaie@buqaen.ac.ir
[۲] saberi@buqaen.ac.ir
[۳] Data Governance
[۴] Meta Data
[۵] Data Warehouse
[۶]Data Stewardship