
TiDB جایگزین مقیاس پذیر MySQL
تایدیبی(TiDB) به عنوان یک دیتابیس مقیاسپذیر رابطهای، منطبق بر پروتکل ارتباطی MySQL، بهینه شده برای اجرای پرس و جوهای تحلیلی و کدهای اسپارک علاوه بر دستورات SQL معمولی، تضمین جامعیت دادهها و با ایده گرفتن از معماری دیتابیسهای مقیاسپذیر رابطهای گوگل، جایگزینی مناسب و چند منظوره برای تمامی بانکهای اطلاعاتی رابطهای بخصوص مایاسکیوال خواهد بود.
مای اس کیو ال به عنوان دومین بانک اطلاعاتی محبوب و رایج دنیا (بر طبق رتبه بندی سایت DB-Engines)، برای تمامی فعالان حوزه آی تی، کاملاً شناخته شده است. دیتابیسی قدیمی و متن باز که با خریداری شدن مالک اصلی آن یعنی شرکت Sun Microsystems توسط اوراکل، شاهد شکل گیری دو نسخه مجزا از آن هستیم ( MariaDB و MySQL) درباره تاریخچه MySQL می توانید به مقاله نگاهی اجمالی به نسخه های مختلف مای اس کیو ال – MySQL مراجعه کنید.
برای بسیاری از شرکت ها و موسساتی که به دلیل امکانات مناسب و رایگان بودن آن، به استفاده از این بانک اطلاعاتی روی آورده اند و با افزایش حجم کاربران و تراکنش ها و بالارفتن نرخ تولید داده، همواره این سوال مطرح بوده است که آیا مای اس کیو ال برای حجم بالای اطلاعات و تراکنش ها یعنی برای عصر کلان داده، مناسب و قابل اطمینان خواهد بود یا نه ؟
راه حل های موقتی مانند تقسیم بانک اطلاعاتی در چند نود (شاردینگ – sharding) و نیز تکرار داده ها در نودهای مختلف از اولین راه حل هایی است که مدیران دیتابیس برای غلبه بر کاهش سرعت و کارآیی مای اس کیوال انجام می دهند اما اگر رشد داده های شما بسیار زیاد باشد، با توجه به اینکه ساختار مای اس کیو ال، برای حجم عظیم داده و توزیع آن در صدها نود، شکل نگرفته است، در دراز مدت به چالش برخورد خواهند کرد.
با معرفی دیتابیس های رابطه ای و مقیاس پذیر گوگل (در حد هزاران نود) به نام Spanner و F1 و انتشار ساختار معماری آنها، ایده ساخت یک دیتابیس رابطه ای متن باز و سازگار با مای اس کیو ال شکل گرفت و نهایتاً دیتابیس جدیدی شکل گرفت با نام TiDB.
این دیتابیس که جزء بانکهای اطلاعاتی NewSQL رده بندی می شود با هدف پاسخگویی با حجم عظیم داده (مقیاس پذیر)، زبان SQL، پشتیبانی از تراکنش و قوانین بانکهای اطلاعاتی رابطه ای یعنی ACID و نیز غلبه خودکار بر خطا و خرابی شبکه، با واسط کاربری و دستوراتی شبیه به MySQL به وجود آمد، به گونه ای که بتوان به راحتی آنرا استارت کرده، داده های مای اس کیو ال قدیمی را به آن منتقل نموده و کار با آن را شروع کنیم بدون اینکه یک خط کد را در برنامه های خود تغییر بدهیم.
یعنی یک جایگزین درجا ( drop-in replacement) و مناسب برای مای اس کیو ال .
معماری تای دبی بی، از سه بخش مجزا تشکیل شده است :
- TiDB Server که مشابه با Google Spanner طراحی شده است و واسطی شبیه به مای اسکیو ال داشته و وظیفه دریافت پرس وجوها و ارسال جواب به کلاینت ها را برعهده دارد.
- TiKV Server (تای کی وی سرور) : به عنوان یک موتور ذخیره سازی کلید مقدار توزیع شده مشابه با Google F1، ذخیره داده ها را در شبکه به صورت منطقه بندی (Region)شده، برعهده دارد.
- Placement Driver که البته می توان آنرا بخشی از فضای ذخیره سازی هم در نظر گرفت، نقش جایابی داده ها در شبکه و مناطق مختلف را برعهده دارد.
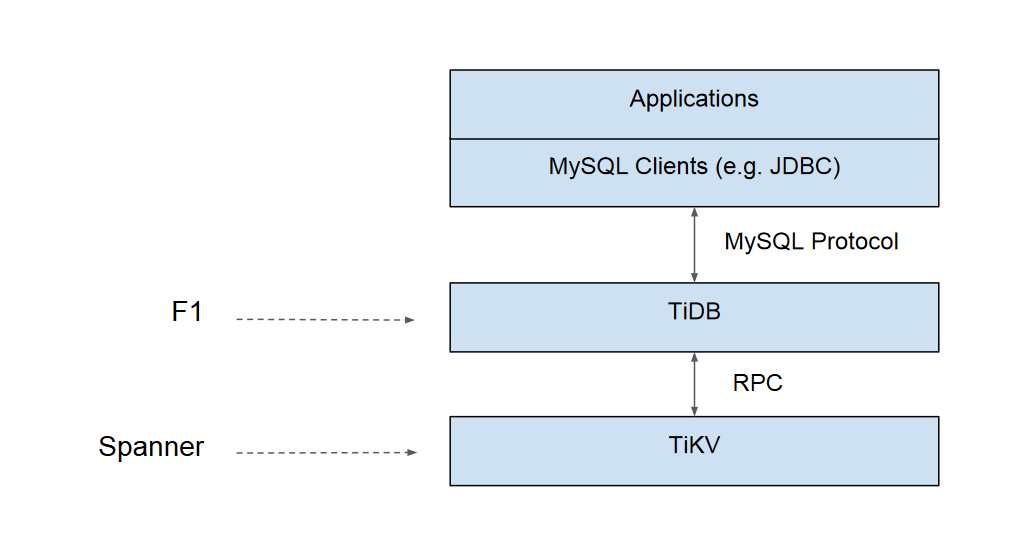
معماری دقیق این دیتابیس به صورت زیر است :

● MySQL clients: The top layer is a set of MySQL clients. These clients send requests to the next layer. You can still use any MySQL driver that you are already familiar with.
● Load Balancer: This is an optional layer. Such as HAProxy or LVS.
● TiDB Server: It’s stateless, and a client may connect to any TiDB server. Within the TiDB server, the top layer is MySQL Protocol, it provides MySQL protocol support; the next layer is SQL optimizer, which is used to translate MySQL requests to TiDB SQL plan.
● The bottom layer is KV API and Distributed SQL API. If the lower level storage engine supports coprocessor, TiDB SQL Layer will use DistSQL API, which is much more efficient than KV API. TiDB supports pluggable storage engines. We recommend TiKV as the default storage engine.
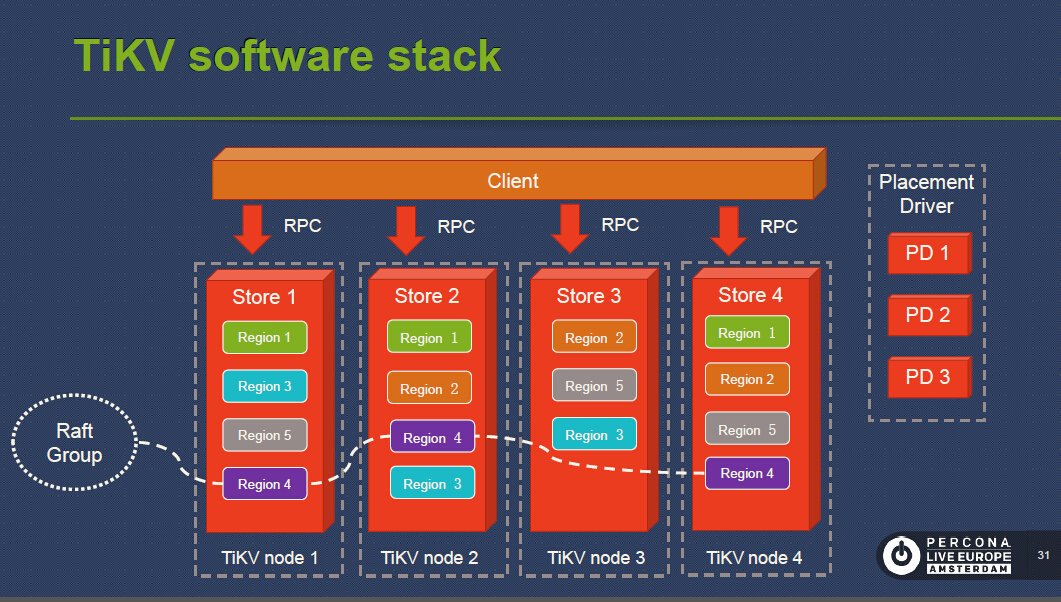
TiKVبرای تقسیم داده ها در شبکه و غلبه بر مشکلات شبکه، از الگوریتم Raft برای انتخاب سرگروه در هر چند نود شبکه استفاده میکند که یک الگوریتم ساده و رایج در دنیای امروز سیستم های توزیع شده است.
بخش ذخیره سازی داده ها که امکان توزیع شوندگی در بین هزاران نود را فراهم کرده است و سازگاری داده ها را هم برای ما تضمین نموده است، ساختاری به شکل زیر دارد :
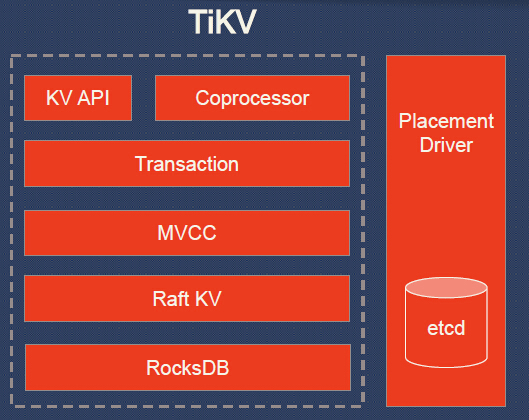
● The bottom layer, RocksDB.
● The next layer, Raft KV, it’s a distributed layer.
● MVCC, Multiversion concurrency control. I believe many of you are pretty familiar with MVCC. TiKV is a multi-versioned database. MVCC enables us to support lock-free reads and ACID transactions.
● Transaction: The transaction model is inspired by Google’s Percolator. It’s mainly a two-phase commit protocol with some practical optimizations. This model relies on a timestamp allocator to assign monotone increasing timestamp for each transaction, so the conflicts can be detected. I will cover the details later.
● KV API: it’s a set of programming interfaces and allows developers to put or get data.
● Placement Driver: Placement driver is a very important part, and it helps to achieve geo-replication, horizontal scalability and consisten distributed transactions. It’s kind-of the brain of the cluster.
ایده اصلی Placement driver هم از Google spanner گرفته شده است و مغز اصلی شبکه و مدیریت کلاستر بر عهده این واحد مهم و اساسی است .
در هر صورت، اگر به استفاده از این دیتابیس متن باز و مقیاس پذیر به جای مای اس کیو ال ترغیب شده اید، نگاهی به مقاله «How we build TiDB» حتماً بیندازید.
پینوشت
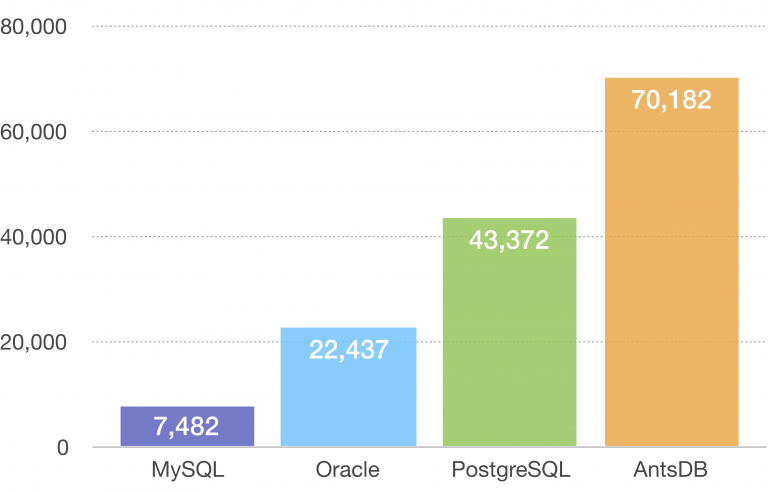
اخیرا با دیتابیس AntsDB هم آشنا شدم که یک دیتابیس توزیع شده بر روی HBase و در بستر هدوپ اما با پروتکل استاندارد مای اس کیو است . بنابراین اگر به دنبال یک راه حل مبتنی بر هدوپ و HBase هستید بدون اینکه کدهای برنامههای نوشته شده خود را تغییر دهید، AntsDB را هم که طبق ادعای سایت آن، کارآیی بالاتری نسبت به دیتابیسهای رابطهای اصلی دنیا هم از خود نشان داده است،مد نظر داشته باشید.
دیتابیس دیگری که کاملاً مطابق با پروتکل مایاسکیوال بوده و میتواند به جای آن به کار رود، SequoiaDB است. این دیتابیس امکان توزیع شدگی دادهها را فراهم میکند و نقش سیستم فایل شما در سرویس دهی به تصاویرو مانند آنرا هم بر عهده میگیرد. از دیگر ویژگیهای آن، امکان مدلسازی چندگانه برای دادههاست. برای آشنایی بیشتر به این آدرس مراجعه کنید.
سایتهایی مثل یوتیوب و اسلک، مشکل مقیاسپذیری خود را جور دیگری حل کردهاند، آنها از میان افزاری به نام وایتِس (Vitess) استفاده کرده اند که با همین مایاسکیوال موجود، بتوانند میلیونها درخواست در روز را پاسخ دهند. برای اطلاعات بیشتر راجع به این رهیافت به این مقاله مراجعه کنید.