
در ادامه بررسی امکانات جدید هدوپ ۳ که در بخش اول این نوشتار به آنها اشاره شد، در این مقاله به سایر امکانات و تغییراتی که در نسخه جدید هدوپ شاهد آنها هستیم، می پردازیم.
معرفی نسخه ۲ سرویس خط زمان Yarn
قبل از بررسی نسخه جدید سرویس خط زمان Yarn، بهتر است ابتدا مروری بر معماری Yarn به عنوان مولفه مدیریت منابع هدوپ داشته باشیم. همانطور که میدانید، در نسخه اول، هدوپ تنها از دو مولفه ذخیره سازی داده (HDFS) و پردازش توزیع شده (Map/Reduce– توزیع/تجمیع) تشکیل می شد.
با گسترش هدوپ در محیط های واقعی و فراگیر شدن آن در پردازش های کلان داده، نبود یک هماهنگ کننده و مدیر منابع شبکه برای اجرای پردازش ها، احساس می شد. این نیاز، باعث شد که در نسخه ۲ هدوپ، شاهد افزوده شدن مولفه ای دیگر به هدوپ با نام Yarn بودیم که وظیفه اصلی آن، مدیریت منابع (رم، سی پی یو، هارد و …) در دسترس برای اجرای یک پردازش و پایش پیشرفت کار(خط زمانی اجرا) و در صورت نیاز، اجرای مجدد پردازش بر روی سایر گره های محاسباتی در صورت رخداد خطا در شبکه است. به این ترتیب، بخش پردازش داده، نگران مدیریت منابع نیست و اختصاص، پایش و مدیریت منابع بر عهده Yarn قرار گرفته است.
معماری نسخه اول Yarn از قرار زیر است :
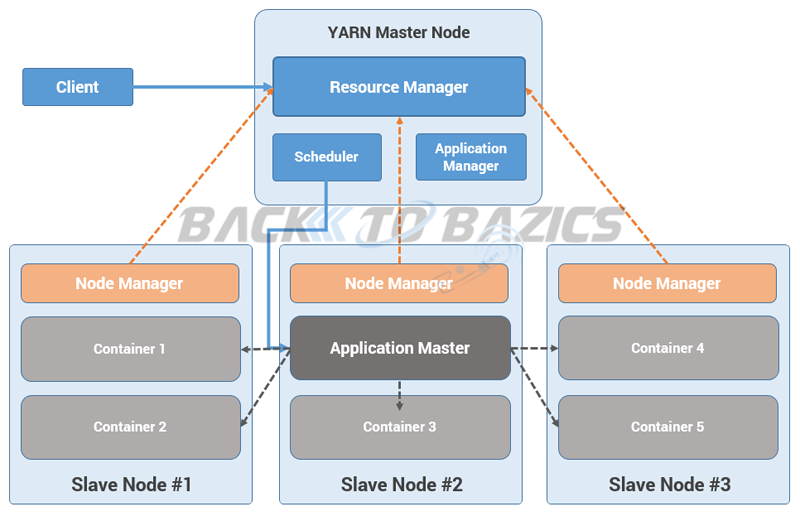
همانطور که در شکل فوق مشخص است، Yarn به صورت Client/Server کار می کند. در گره اصلی Yarn که به آن Yarn Master Node می گوئیم، مولفه مدیریت منابع (Resource Manager) قرار گرفته است. این مولفه وظیفه پایش و نگهداری اطلاعات منابع در دسترس و منابع در حال استفاده شبکه را بر عهده دارد. برای این منظور، در هر نود یا گره شبکه، یک مولفه نرم افزاری Yarn به نام Node Manager باید در هر حال اجرا باشد که آمار منابع آن گره را به RM (مدیر منابع) در گره اصلی ارسال می کنند. برای مدیریت بهتر این منابع، هر سیستم ( یا گره در ادبیات سامانه های توزیع شده) به چندین اسلات یا محفظه (Container) تقسیم می شود که هر محفظه مجموعه ای از رم و هسته سی پو است. مثلاً یک محفظه می تواند مجموعه یک هسته سی پی یو و یک گیگابایت رم باشد (سایر منابع مانند هارد هم می تواند ).
با این توضیح، اکنون به بررسی روند درخواست و اجرای یک پردازش داده بر روی بستر هدوپ ۲ می پردازیم. هنگام ارسال یک درخواست پردازش داده به هدوپ، این درخواست توسط Resource Manager دریافت می شود و کامپونتت Application Manager بررسی می کند که منابع کافی برای اجرای بخش مدیریتی این پردازش را در شبکه دارد یا نه. در صورت وجود منابع کافی، پردازش، قبول شده و یک محفظه برای بخش مدیریتی این پردازش که به آن Application Master می گوییم، اختصاص می یابد. به یاد داشته باشید که Application Manager وظیفه مدیریت و مانیتور پردازش های ارسال شده به کلاستر هدوپ را بر عهده دارد و درون Yarn Master Node قرار گرفته است اما Application Master، بخش مدیریتی هر پردازش است که نظارت بر اجرای فرآیند توزیع و تجمیع در هدوپ (یا اجرای پردازش های اسپارک و مانند آن ) و درخواست محفظه برای آنها و اموری مانند آنرا برعهده دارد. بعد از اختصاص یک محفظه به Application Master، اجرای آن بر عهده مولفه زمان بند (scheduler) از Yarn Master Node خواهد بود.
با اجرای این بخش اصلی از پردازش، منابع مورد نیاز برای اجرای درخواست اصلی کاربر شناسایی شده و از Resource Manager محفظه های لازم، درخواست می شود. RM محفظه های خالی مطابق با درخواست کاربر را در شبکه یافته و آنها را به Application Master اطلاع می دهد. تا اینجا هنوز، فرآیند پردازش داده (مثلاً فرآیند توزیع و تجمیع) شروع نشده است. با اختصاص محفظه های لازم و قرارگیری کدهای پردازش درون آنها، Application Master از Node Manager هر سیستم، درخواست می کند که محفظه اختصاص یافته را اجرا کند. به این ترتیب، پردازش اصلی داده ها شروع می شود.
در حین پردازش، هر محفظه، وضعیت فعلی پیشرفت کار را به Application Master اطلاع می دهد. در صورت رخداد خطا در هر محفظه، محفظه دیگری از مدیرمنابع درخواست شده و اجرای آن توسط Application Master کلید می خورد. Node Manager هم وضعیت فعلی منابع در حال استفاده گره را به مدیرمنابع در بازه های زمانی معین، ارسال می کند.
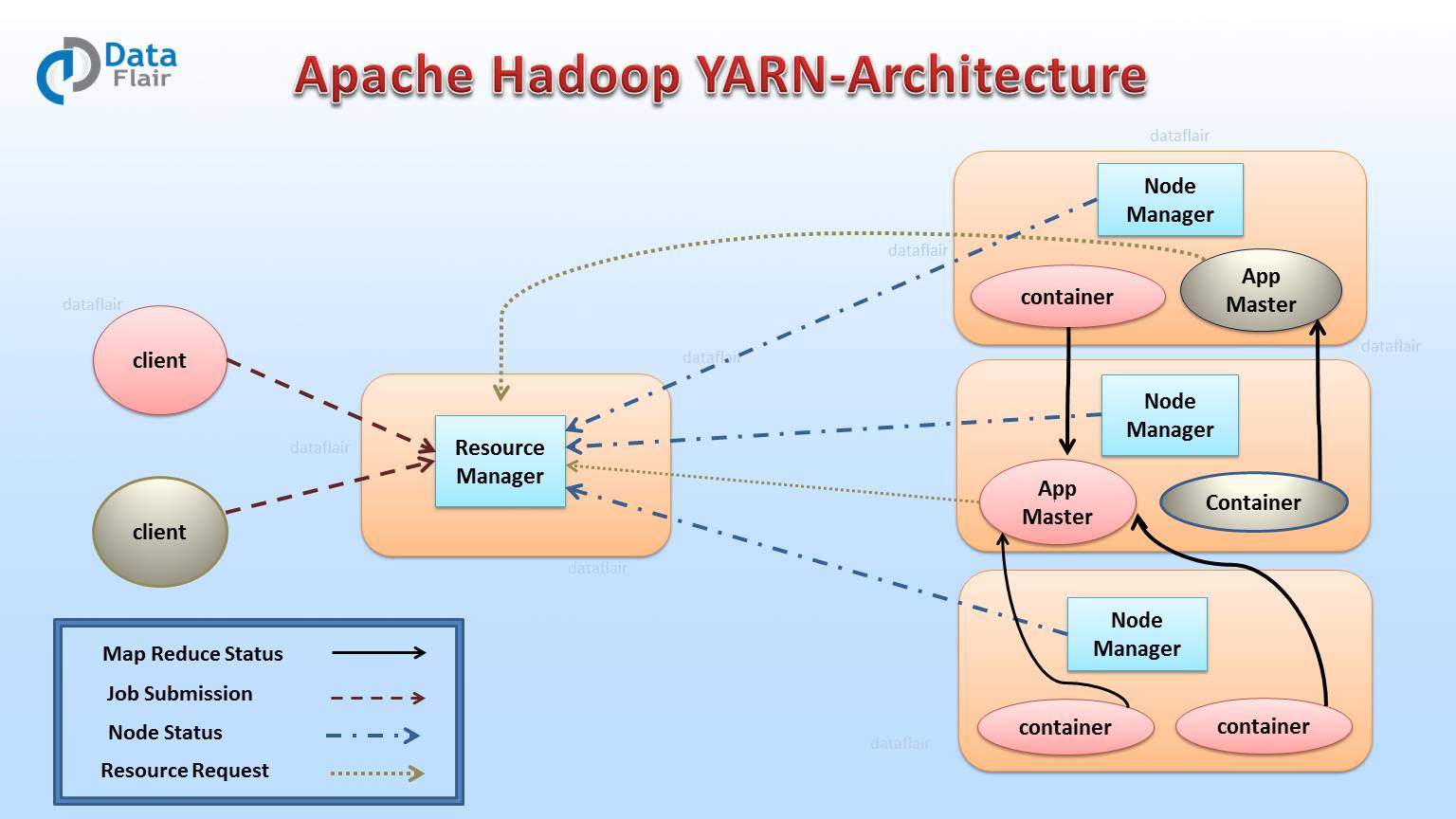
تصویر زیر این فرآیند را برای دو پردازش درخواست شده توسط دو کاربر به یک کلاستر هدوپ ۲، به خوبی نشان می دهد.
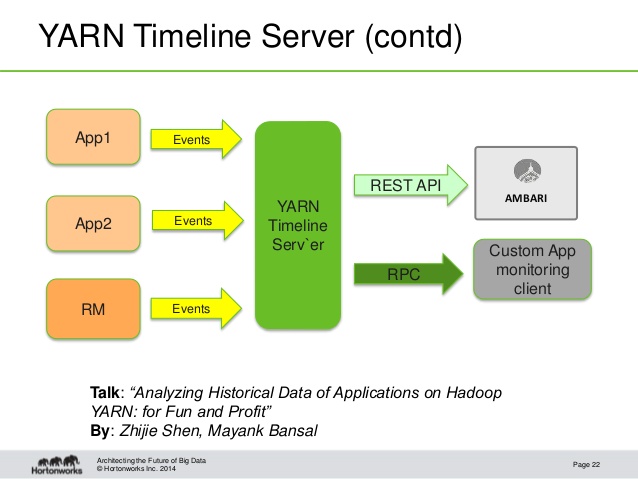
با این مقدمه، می توانیم وارد فضای بحث سرویس خط زمانی Yarn و تشریح بهبودهای صورت گرفته آن در هدوپ ۳ شویم. در هدوپ نسخه ۱، Application History Server وظیفه جمع آوری آمار و اطلاعات فرآیندهای تکمیل شده در هدوپ را بر عهده داشت. در نسخه ۲ هدوپ، مولفه Yarn قرار بود بتواند هر نوع برنامه پردازشی را در یک شبکه از سیستم ها مستقل از فرآیند پردازش، اجرا کند. بنابراین نیاز به سرویسی بود که برای جمع آوری آمار و اطلاعات مانند Application History Server وابسته به مکانیزم توزیع و تجمیع و نیز HDFS نباشد و بتوان آنرا برای پردازش های توزیع شده مستقل از هدوپ هم به کار برد. این امر باعث شد که وظیفه اصلی پایش و جمع آوری آمار و اطلاعات در نسخه ۲ هدوپ به سرویس خط زمانی آن، محول شود.
در حین اجرای یک پردازش، سرویس Timeline که درون Yarn Master Node قرار گرفته است، به جمع آوری اطلاعاتی مانند زمان شروع و خاتمه یک محفظه و لاگ های تولید شده توسط آن، موفقیت یا بروز خطا در یک پردازش و موارد مدیریتی مانند اینها می پردازد و آنها را در یک بانک اطلاعاتی لوکال مانند LevelDB ذخیره می کند که کاربران می توانند از طریق یک واسط وب یا از طریق پروتکل REST به مشاهده وضعیت لحظه ای پردازش خود بپردازند.
اما این معماری ساده که خود بهبود بزرگی نسبت به هدوپ ۱ محسوب میشد، برای جمع آوری آمار و اطلاعات پردازش ها، مقیاس پذیر نبود و با افزایش حجم شبکه و نیز وجود پردازش های موازی زیاد، وجود یک سرویس خط زمانی در شبکه که همه محفظه ها اطلاعات خود را به آن ارسال کنند که آنهم مبتنی بر یک بانک اطلاعاتی محلی ساده بود، باعث بروز مشکلاتی در شبکه های بزرگ شده بود. از طرفی، بسیاری از پردازش های امروزین، ساختاری خط تولید مانند دارند یعنی نیاز است که با اتمام یک پردازش، یک یا چند پردازش دیگر مبتنی بر داده های تولید شده، شروع شوند و این مکانیزم جریان پردازش، تاکنون توسط خود برنامه ها مدیریت می شدند. در نسخه دوم سرویس خط زمانی Yarn با دو بهبود عمده در این راستا مواجه هستیم :
- بهبود مقیاس پذیری
- ارتقاء عملکرد و افزوده شدن قابلیت های جدید
برای افزایش مقیاس پذیری، در این سرویس مانیتورینگ و پایش شبکه در هدوپ دو بهبود اصلی صورت گرفته است :
- استفاده از دیتابیس HBase به عنوان بانک اطلاعاتی پیش فرض
- اختصاص یک نویسنده( Collector یا Writer) / سرویس دهنده (Reader)به هر پردازش
توضیح اینکه در نسخه جدید سرویس خط زمان Yarn،برای جمع آوری اطلاعات و آمار هر پردازش یک پردازه (Process) به هر برنامه ارسال شده به هدوپ، اختصاص می یابد که وظیفه جمع آوری و نوشتن داده ها و آمار پیشرفت کار را در دیتابیس سرویس خط زمان بر عهده دارد. این پردازه، Collector یا Writer هم نامیده می شود. از طرفی برای پاسخگویی به درخواستهای مشاهده این آمار و اطلاعات توسط کاربر یا سایر برنامه ها، یک پردازه سرویس دهنده (Reader) هم به هر برنامه اجرا شونده در هدوپ اختصاص می یابد. توزیع این دو پردازه در شبکه، در کنار ماهیت توزیع پذیر دیتابیس اختصاصی سرویس خط زمان (به طور پیش فرض : HBase) باعث مقیاس پذیری این سرویس در نسخه جدید شده است.
این معماری طبق سایت رسمی آپاچی، به صورت کلی مطابق دیاگرام زیر است :
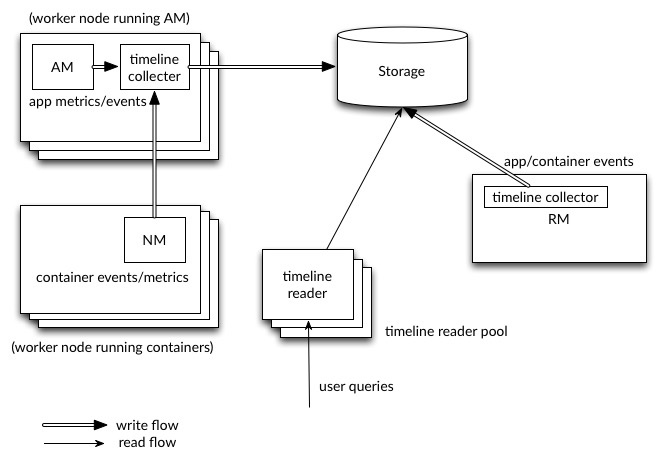
همانطور که از شکل مشخص است، در کنار Application Master یک Timeline Collector قرار گرفته است و تمامی آمار و اطلاعات مرتبط با محفظه های آن پردازش از طریق Node Manager هر سیستم ، به آن ارسال می شود. مدیر منابع یا همان Resource Manager هم یک Timeline Collector مخصوص خود دارد که آمار و اطلاعات کلی شبکه را از طریق آن، ذخیره و ثبت می کند.
در حوزه ارتقای عملکرد و امکانات سرویس خط زمان هم با چند بهبود مناسب روبرو شده ایم . اول اینکه امکان اجرای یک برنامه به صورت جریانی از کارها و پردازش ها مهیا شده است. این جریان کارها که به آنها flow می گوییم، مدیریت فرآیند پردازش را برای کاربران و توسعه دهندگان ساده تر می کند.
بهبود بعدی، ارتقای مدل داده مرتبط با رخدادها و بهبود آماری است که از هر رخداد جمع آوری میشود. بهبود سوم، امکان تعریف سنجه های جدید در این نسخه برای جمع آوری از هر پردازش است که مدیریت و نظارت بر فرآیند پردازش را سفارشی تر می کند. مثلا ذخیره میانگین زمان اجرا، ماکسیمم زمان اجرا و مانند آن به ازای هر پردازش در این نسخه، مهیا شده است. 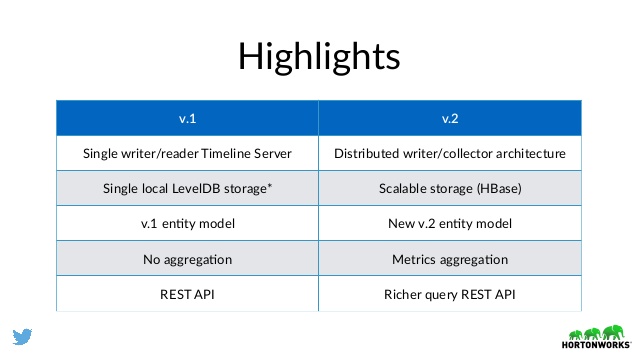
بازنویسی خط فرمان هدوپ (Shell Script)
بسیاری از دستورات هدوپ بخصوص دستورات مدیریتی آن، از طریق خط فرمان قابل انجام است. این خط فرمان در نسخه ۳ هدوپ، مجددا بازنویسی شده است تا بسیاری از خطاها و ناسازگاریهای آن مرتفع شود. دستورات جدیدی هم البته به آن افزوده شده است. برخی از این تغییرات از قرار زیر هستند :
- تمام دستورات خط فرمان هدوپ، پشت صحنه فایل hadoop-env.sh را اجرا می کنند که باعث می شود تمام متغیرهای محیطی هدوپ، از یک مکان مدیریت شده و قابل دسترس باشند.
- برای اجرای پشت صحنه برنامه های هدوپ، دیگر نیازی به استفاده از فایلهای اجرایی مخصوص اینکار برای هر برنامه که با پسوند daemon.sh مشخص می شدند نیست و به جای آن، برای مدیریت برنامه های مختلف دیمون (سرویس های پشت صحنه هدوپ که باید همیشه در حال اجرا باشند) هدوپ، از گزینه daemon در خود دستورات بهره می بریم . مثلا برای اجرای گره نام (namenode) کافیست دستور hdfs را به صورت زیر به کار بریم : hdfs -daemon start namenode
- دستوراتی که نیاز به متصل شدن به سایر نودهای شبکه دارند به جای ssh از pdsh (در صورت نصب) استفاده می کنند.
- نمایش خطاهای پیش آمده در دستورات، بهبود یافته است .
و بسیاری تغییرات دیگر که باید در مقاله ای جداگانه به آنها اشاره کنیم.
رفع ناسازگاری فایل های کتابخانه ای هدوپ با کتابخانه های دیگر جاوا
یکی از مشکلاتی که در نسخه ۲ هدوپ با آن مواجه بودیم، این بود که برنامه ای که برای هدوپ نوشته میشد و از کتابخانه های مخصوص به خود یا نسخه خاصی از کتابخانه های عمومی جاوا استفاده می کرد، هنگام کامپایل ، کتابخانه های عمومی و اختصاصی هدوپ هم به مجموعه کتابخانه هایش اضافه میشد که این امر باعث می شد که گاهاً ناسازگاریهای مابین کتابخانه های جاوای هدوپ و کتابخانه های مورد استفاده توسط برنامه کاربر پیش آید که رفع آن، زمان و تلاش زیادی را می طلبید.
در نسخه جدید هدوپ، این ناسازگاری با تفکیک کتابخانه های زمان اجرا (که در هنگام اجرا نسخه درست کتابخانه بارگذاری و اجرا می شود) و کتابخانه های زمان کامپایل حل شده است.
پشتیبانی از محفظه های فرصت مند و ارتقای عملکرد توزیع کار در شبکه
در نسخه ۲ هدوپ، زمانی که یک پردازش برای اجرا دریافت می شود، مدیر منابع بررسی می کند که یک محفظه خالی در شبکه برای اجرای Application Master وجود دارد یا نه . در صورت وجود و اختصاص یک محفظه به آن، AM بسته به نیاز درخواست یک تا چند محفظه برای اجرای پردازش اصلی متناظر با خود می کند. RM شبکه را بررسی کرده و محفظه های لازم را به AM اختصاص می دهد. با این تخصیص، پردازش بلافاصله شروع به اجرا می کند و تا پایان پردازش در هر محفظه و یا رخداد خطا در آن، روند اجرا متوقف نمی شود. به این نوع از محفظه های پردازشی که بعد از تخصیص، گارانتی می شود که تا پایان اجرا شوند و منابع لازم برای شروع و اجرای آنها تخصیص داده شده است، محفظه های گارانتی شده می گوییم.
در نسخه ۳ هدوپ، نوع جدیدی از محفظه های پردازشی با نام محفظه های فرصت مند (Opportunistic) معرفی شدند که برای انجام پردازش های با اولویت پایین تر، مورد استفاده قرار می گیرند. هنگامی که یک درخواست از نوع محفظه های فرصت مند، توسط مدیر منابع دریافت میشود، درصورت نبود محفظه و منابع خالی در شبکه برای اجرای آن، یک یا چند محفظه در حال اجرا را به این درخواستها تخصیص می دهد. در این حالت، درخواست پردازش فرصت مند در صف اجرا قرار می گیرد و به محض خالی شدن محفظه تخصیص یافته، شروع به اجرا می کند. از طرفی اگر یک پردازش جدید، درخواست یک محفظه گارانتی شده را نمود و محفظه خالی در شبکه موجود نبود، پردازش فعلی یک محفظه فرصت مند متوقف شده و در صف اجرا قرار میگیرد و پردازش اولویت دار با این محفظه قبضه شده، کار خود را ادامه می دهد.
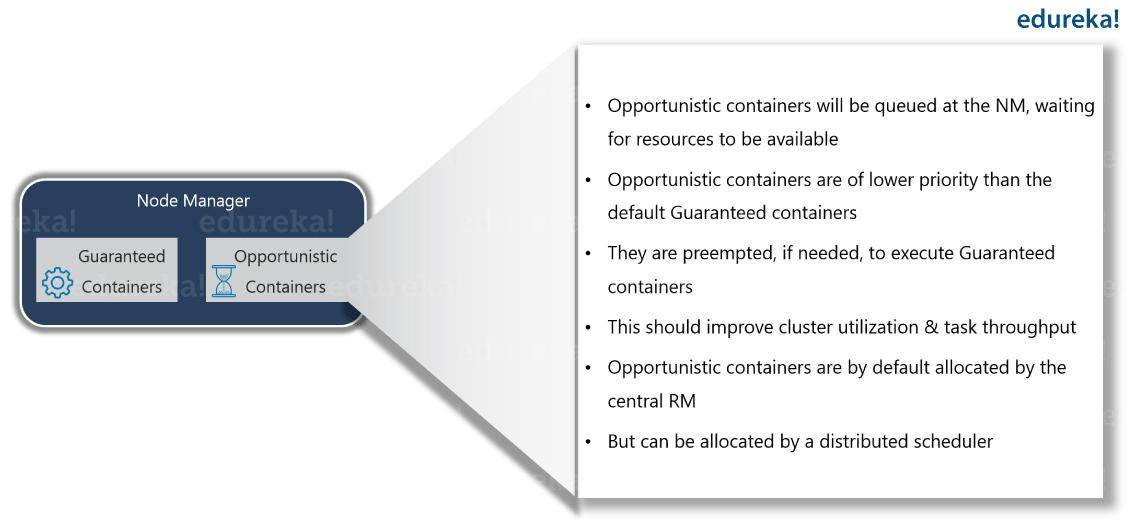
با این تغییر، امکان مصرف بهینه تر منابع شبکه واولویت بندی پردازش ها مهیا شده است.
بهینه سازی فرآیند توزیع در هدوپ ( Task-Level Native Optimization)
همانطور که میدانید شالوده اصلی پردازش در هدوپ، فرایند توزیع پردازش در شبکه (Map) و تجمیع نتایج (Reduce) است که در این بین، بعد از تولید کلید/مقدار های اولیه در حین اجرای فرآیند توزیع (map)، بسیاری از اوقات لازم است پردازش، مرتب سازی و توزیع مجدد نتایج در شبکه صورت گیرد (Shuffle/Sort) تا فاز تجمیع بتواند پاسخ های نهایی را از این مقادیر استخراج کند. در نسخه جدید هدوپ، فرآیند توزیع وظایف با کدهای بومی جاوا (native Java implementation) بازنویسی شده است و تا شاهد ارتقای ۳۰٪ در کارآیی و سرعت برخی فرآیندها باشیم.
پشتیبانی از دو گره نام (NameNode)
در نسخه اولیه هدوپ، سیستم مدیریت فایل (HDFS)، از دو بخش اصلی تشکیل می شد : گره نام (NameNode) و گره داده (DataNode). گره نام فهرست فایلهای هدوپ و آدرس تک تک بلاک های هر فایل را نگهداری می کرد و خود فایلها به صورت بلاک به بلاک در گره های داده، ذخیره می شدند. به ازای هر خوشه هدوپ (Hadoop Cluster) یک گره نام و ده ها گره داده وجود داشتند. وجود تنها یک عدد گره نام علاوه بر اینکه گلوگاهی در شبکه های بزرگ هدوپ محسوب میشد، ریسک از کارافتادن آن و از کار افتادن کل خوشه هدوپ را بسیار بالا می برد.
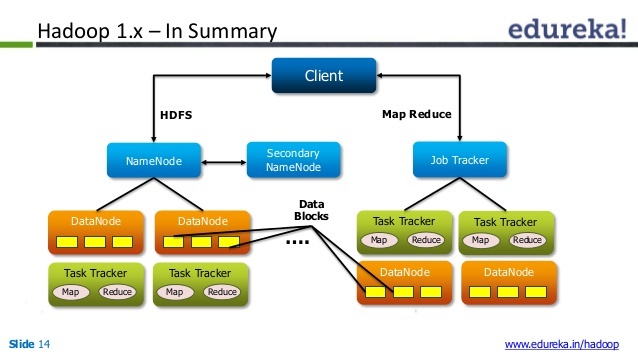
توضیح اینکه در شکل فوق که معماری هدوپ در نسخه یک را نشان می دهد، گره Secondary NameNode علیرغم اسم گول زننده اش نقشی در جایگزینی NameNode ندارد و یک بکاپ قدیمی از داده های سیستم فایل را در خود نگاه می دارد. در بازه های زمانی منظم،به کمک این بکاپ موجود در Secondary NameNode و تغییرات ثبت شده در فایل لاگ HDFS، یک فهرست بروز از کل شبکه تهیه می شود و NameNode به روز رسانی می شود و این نسخه جدید در Secondary NameNode هم قرار می گیرد. در نسخه یک هدوپ، تغییرات در فایلهای مختلف مانند حذف یا ایجاد یک فایل در شبکه، به طور مستقیم در NameNode ذخیره نمی شود بلکه در فایل لاگ مخصوص اینکار ثبت می شود و در بازه های زمانی معین، NameNode آپدیت می شود.
در هدوپ ۲ این نقیصه با تغییر معماری گره های نام و گره های داده تا حدودی رفع شد. این معماری که با نام HDFS NameNode High-Availability (HA) شناخته می شود، برای تضمین در دسترس بودن همیشگی گره نام، از یک گره نام فعال و یک گره نام آماده به کار تشکیل می شود. تغییرات انجام شده در سیستم فایل که توسط گره نام فعال صورت می گیرد مانند ایجاد یا حذف یک فایل توسط خود این گره، در گره های ثبت وقایع (JournalNode) و درون یک فایل ثبت تراکنش (لاگ فایل) نوشته می شود. گره نام آماده به کار به صورت منظم، فایل لاگ تغییرات را در گره های ژورنال (ثبت وقایع)، خوانده و تغییرات را در فهرست داخلی خود که یک کپی از اطلاعات فایلهای موجود در شبکه است، به روز می کند. البته گره های داده، به صورت منظم اطلاعات بلاک های قرار گرفته درون خود را به هر دوی این گره ها ارسال می کنند تا اعمال تغییرات در این گره های نام، با سرعت بیشتری انجام گیرد.
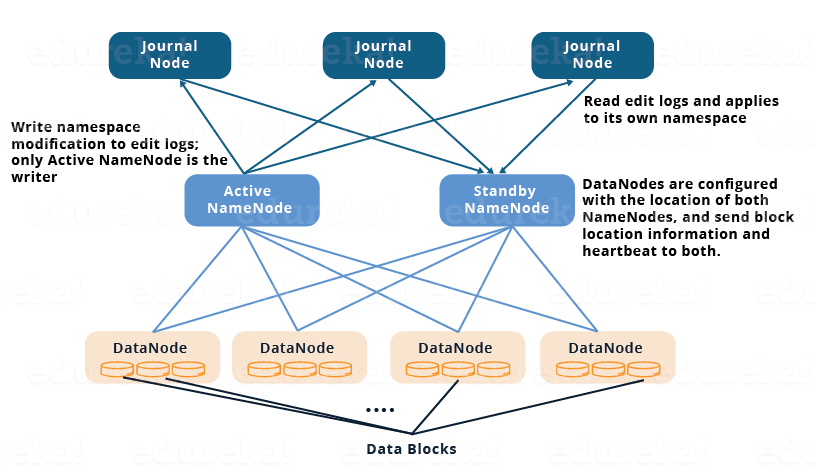
در صورت از دسترس خارج شدن گره نام فعال، گره نام آماده به کار ابتدا بررسی می کند که آیا تمام تغییرات ثبت شده در فایل لاگ تغییرات را اعمال کرده است یا نه. در صورت اعمال همه آنها، به سرعت خود را به عنوان گره نام فعال معرفی می کند و به سرویس دهی در شبکه می پردازد و همزمان گره نام آماده به کار جدیدی شروع به کار می کند .
در هدوپ ۲ تنها یک گره نام آماده به کار و سه گره ثبت وقایع داریم که در صورت خرابی یک گره نام، اشکالی در شبکه پیش نمیاید اما اگر همزمان هر دو گره نام از کار بیفتند، سیستم با اشکال مواجه خواهد شد . در هدوپ ۳ سطح دسترس پذیری گره های نام را افزایش داده اند. در این نسخه ما دو گره آماده به کار و پنج گره ثبت وقایع (ژورنال) داریم که در صورت بروز خطا در دو گره نام، هنوز هم سیستم به راحتی به کار خود ادامه خواهد داد .
تغییر پورت های پیش فرض برخی سرویس های هدوپ
به دلیل تداخل پورت های پیش فرض سرویس هایی از هدوپ مانند گره نام، گره نام ثانویه، گره داده و مانند آن با دامنه پورت های موقت لینوکس (۳۲۷۶۸-۶۱۰۰۰) در نسخه ۳ هدوپ این پورت ها به خارج از این بازه به شرح ذیل منتقل گردید :

اتصال به فایل سیستم های جدید
در نسخه ۳ هدوپ، امکان اتصال مستقیم هدوپ به Microsoft Azure Data Lake و Aliyun Object Storage System به عنوان فضای ذخیره سازی جایگزین فایل سیستم محلی مهیا شده است که این فهرست، در حال گسترش و افزوده شدن است.
متوازن سازی خودکار گره های داده
در حالت عادی هنگامی که یک فایل توسط یک گره داده در دیسک نوشته می شود، اگر چندین دیسک در سیستم وجود داشته باشد که معمولا در یک مرکز داده اینگونه است، خود گره داده، نوشتن را به گونه ای انجام می دهد که دیسک ها به صورت متوازن پر شوند . حال اگر یک دیسک جدید به سیستم اضافه شود، این توازن به هم می خورد و نسخه های قبلی هدوپ، برای این منظور، تمهیدی نیندیشیده بودند.
در نسخه جدید هدوپ امکان متوازن سازی خودکار دیسک ها و گره های داده توسط خط فرمان هدوپ، مهیا شده است.
امکان سفارشی سازی حجم حافظه هیپ سرویس ها و پردازش های توزیع/تجمیع
در این نسخه از هدوپ، امکان پیکربندی مناسب تر سرویس ها و پردازش های هدوپ از لحاظ حافظه مهیا شده است. بخصوص اینکه به جای متغیر محیطی HADOOP_HEAPSIZE که اندازه هیپ هدوپ را تعیین می کرد اکنون می توان برای این منظور یک حداقل و حداکثر حافظه از طریق HADOOP\_HEAPSIZE\_MAX و HADOOP\_HEAPSIZE\_MIN تعیین نمود.
ساختار اصلی این نوشتار از این مقاله مستخرج شده است.