
طراحی بانک اطلاعاتی مناسب برای تلگرام – یک مثال عملی
آشنایی با بانکهای اطلاعاتی مختلف و نقاط ضعف و قوت هر یک به ما کمک می کند تا بتوانیم بهترین طراحی را برای سیستم های نوین اطلاعاتی داشته باشیم. مدتی بود که ذهن بنده (از سر کنجکاوی) درگیر این شده بود که ساختار اطلاعاتی مورد نیاز برای طراحی یک برنامه پیام رسان مانند تلگرام چگونه است؟ و به چه نوع بانک اطلاعاتی نیاز خواهیم داشت ؟ که بعد از تحلیل اولیه این موضوع ،تصمیم گرفتم نتایج طراحی اولیه خودم را که برگرفته از تجربیات چند سال اخیر در حوزه NoSQL است را در اختیار علاقه مندان قرار دهم.
برنامه های پیام رسان مانند تلگرام ساختار ساده ای دارند : شما می توانید به مخاطبین خود پیام بفرستید و پیام از آنها دریافت کنید، گروهی از مخاطبین را ایجاد کنید، در یک گروه عضو شوید، می توانید برای متن های خودتان از برچسب یا هشتگ (#) استفاده کنید و براساس آنها بعداً به جستجوی مطالب بپردازید و علاوه بر متن، از عکس، فیلم، صوت و فایل هم در پیام های چندرسانه ای استفاده کنید .
در نگاه اول، کار، پیچیده به نظر نمی رسد و با یک طراحی رابطه ای و ایجاد چند جدول اطلاعاتی می توان تمام موارد مورد نیاز را پاسخ داد اما مساله زمانی اهمیت پیدا می کند که تمام موارد فوق باید بین میلیون ها کاربر و با سرعت بسیار بالا انجام شود و مقیاس پذیری و افزایش حجم کاربران هم باید در نظر گرفته شود.
با در نظر گرفتن معیار سرعت پاسخگویی به کاربر، به طراحی بانک اطلاعاتی مورد نیاز برای این سامانه می پردازیم :
۱. ذخیره برچسب ها
می دانیم که هر مطلب می تواند حاوی چندین برچسب باشد و با کلیک کاربر روی هر برچسب باید تمامی مطالب مرتبط با آن برچسب که به آن کاربر مرتبط است با ترتیب زمانی به او نمایش داده شود . در وهله اول به نظر می رسد که یک جدول به اسم برچسب با فیلدهای مطلب، گروه، برچسب و تاریخ برای این منظور کافیست. به این ترتیب به ازای هر جستجو بر اساس برچسب، این جدول براساس گروه هایی که کاربر در آن عضو است و برچسب داده شده ، فیلتر می شود و مطالب بازیابی شده به صورت مرتب به کاربر نمایش داده میشود.
زمانی که بحث میلیون ها کاربر پیش می آید و در ثانیه هزاران دستور جستجوی مطالب بر اساس برچسب به سرور ما قرار است ارسال شود، این رهیافت تمام بار پردازشی را به بانک اطلاعاتی تحمیل می کند و عمل اتصال بین جداول مختلف برای پاسخگویی به یک جستجوی ساده و با فرض اینکه اطلاعات در سرور های مختلف توزیع شده باشند، زمانبر خواهد بود. بنابراین برای بحث برچسب ها باید به دنبال یک راه حل غیر رابطه ای باشیم .
اگر با ساختار بانکهای اطلاعاتی سطرگسترده مانند کاساندرا آشنا باشید، این بخش به مدل داده ای آنها بسیار نزدیک است. توضیح اینکه در بانکهای اطلاعاتی سطر گسترده، به ازای یک سطر خاص که با یک کلید منحصر بفرد شناخته میشود، میلیونها ستون یا داده را می توانیم به ترتیب خاص (معمولاً ترتیب زمانی) ذخیره کنیم و با دادن یک کلید که در اینجا می تواند خود برچسب باشد، تمام مطالب مرتبط با آن برچسب را بازیابی کرده و به کاربر نمایش دهیم .بنابراین به ازای هر مطلبی که در یک گروه مطرح می شود و حاوی برچسب A و B است، این مطلب در سطر A و سطر B (سطری که کلید آن A و B باشد) ذخیره می شود که برای کاستن از میزان واکشی اطلاعات از بانک اطلاعتی می توانیم خلاصه چند کلمه ای از مطلب به همراه کد گروه را هم کنار شماره شناسایی مطلب (Post#n)بیاوریم . شکل زیر این طراحی را به خوبی نشان می دهد .
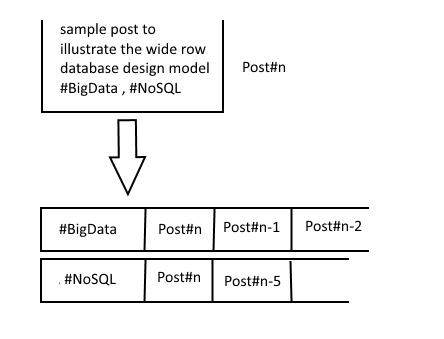
البته این طراحی هنوز بهینه نشده است چون مطالبی که به کاربر الف نشان داده می شود متفاوت از مطالب نشان داده شده به کاربر ب است و در طراحی فوق این مورد دیده نشده است و محور ذخیره سازی خود برچسب (مستقل از کاربر) قرار گرفته است در صورتیکه که مطالب بر اساس کاربر و اینکه در چه گروه هایی عضو است باید بازیابی شده و نمایش داده شود و در روش فوق برای نیل به این هدف، ما باید به ازای مطالب هر بر چسب، چک کنیم که کاربر هم می تواند آن مطلب را ببیند یا نه که عملی زمان براست و با هدف اصلی ما که بازیابی سریع اطلاعات است، در تضاد خواهد بود.
طراحی درست برای این بخش این است که کلید هر سطر را ترکیب برچسب و نام کاربری بگیریم و به ازای هر مطلبی که با دو برچسب A و B منتشر می شود، کد مطلب در تمام سطرهایی که کلیدشان ترکیب برچسب و کد کاربران عضو همان گروه است درج شود . مثلاً اگر گروه حاوی مطلب اصلی، ۱۵۰ عضو داشته باشد در تمام صد و پنجاه سطری که کلید آنها ترکیب برچسب و کد کاربر است باید درج شود .
با این ترتیب، زمانی که یک کاربر روی یک برچسب کلیک می کند، کد کاربر و برچسب را داریم و کافیست ده ستون اول سطر متناظر که کلید آن ترکیب این دو مقدار است را بازیابی کرده و به کاربر نشان دهیم . در اینصورت هیچ گونه اتصال یا عمل پردازشی هنگام جستجوی مطالب متناظر با یک برچسب نیاز نخواهیم داشت . اگر کاربر نتایج بیشتری خواست ، ده ستون بعدی را به او نمایش می دهیم و به همین ترتیب مطالب قبل تر هم قابل مشاهده است و اگر هزار نفر هم در ثانیه درخواست جستجو بر اساس برچسب ها را بدهند ، فقط هزار بازیابی و خواندن اطلاعات خواهیم داشت (به فرض اینکه چند کلمه اول مطب و نام گروه هم در هر سطر ذخیره شود که نیاز به اتصال یا استفاده از جدول دیگر نباشد) که برای بانکهایی مثل کاساندرا که در ثانیه تا حد چند میلیون خواندن را می توانند به راحتی انجام دهند، مساله ای حل شده است .
این مطلب ادامه دارد …..
اگر یک نفر از این گروه ۱۵۰ نفری بیاد بیرون و ده نفر به این گروه اضافه بشن چه اتفاقی میافته با این طراحی؟
این طراحی به ورود و خروج کاربران حساس نیست. به ازای هر پست در هر گروه، به ازای هر برچسب، به تعداد کاربران عضو آن گروه، در سطرهایی که کلید آنها زوج (نام برچسب، نام کاربر) است، مطالب این پست کپی میشود.
برای بهینه کردن طراحی و حل مشکل زیاد شدن فضای ذخیره سازی، می توان در این جدول تنها آی دی یا شماره شناسایی پست را ذخیره کرد و در صورت کلیک کاربر روی یک برچسب، ابتدا تمام پستهای متناظر با درخواست آن کاربر ، از این جدول بازیابی می شوند و در مرحله بعد از حدول پست ها، اطلاعات آنها بازیابی می شود که در کل ، چند تا عمل خواندن اطلاعات است و نیاز به اتصال و پردازش دیگری ندارد .
برای کاربران تازه وارد هم می توان به تعداد پستهایی از قبل که برای او قابل مشاهده است ، همین فرآیند را تکرار کرد.
برای گروه هایی که کاربر از آن خارج می شود، باز هم مطالب آن نمایش داده می شود و نهایتا می توانیم موقع نمایش مطالب ، چک کنیم که گروه مورد نظر الان برای کاربر فعال هست یا نه ؟
سلام
نحوه نگهداری اطلاعات سکرت چت چطوریه پس؟ تلگرام اعلام کرده سکرت چت روی سرورهای ما نگهداری نمیشه
چقدر میشه اعتماد کرد؟
مهندسی داده :
هدف از این مقاله بیشتر آشنایی با سبک طراحی این گونه برنامه هاست و الزاما طراحی واقعی تلگرام را دنبال نمی کند. برای چت خصوصی ایده بنده استفاده از ردیس با استفاده از کلید هایی است که اتومات بعد از یک زمان خاص از حافظه سرور پاک می شوند.
یادمه یه چیزی در مورد Node.js میخوندم و در باره اون توضیح داده بودند که به راحتی میتونه تمامی کاربران متصل به خودش را بدون واسطه ای مانند بانک اطلاعاتی به هم ربط بده.
تصور کنید که شما تعداد زیادی سوکت متصل به یک سرور دارید و سوکت۱(یوزر۱) داده ای را برای سوکت۲ (یوزر۲) ارسال میکنه، در مدل ساده ما باید داده یوزر۱ را در بانک اطلاعاتی ذخیره کنیم و به محض حضور یوزر۲ داده را از بانک اطلاعاتی بخونیم و به اون تحویل بدیم. اما با Node.js میتونیم داده را از یوزر یک دریافت کنیم و همون موقع (بدون اینکه اون را جایی ذخیره کنیم) ارطلاعات را به سوکت۲ ارسال کنیم.
میشه گفت یک ارتباط پوینت تو پوینت مجازی میشه.. یعنی دوتا یوزری سکرت چت دارند به صورت پوینت تو پوینت متصل هستند اما چون آنها آی پی استاتیک ندارند و نمیتونند همدیگر را در اینترنت مستقیم پیدا کنند، هر دو به یک سرور استاتیک متصل میشن و اون سرور یک ارتباط پوینت تو پوینت برای اونها ایجاد میکنه.
سرورهای تلگرام با nodejs پیاده سازی شده.
امنیت تلگرام:
http://www.nasserghiasi.ir/%d9%be%d8%b1%d9%88%d8%aa%da%a9%d9%84-%d9%87%d8%a7-%d9%88-%d8%b1%d9%85%d8%b2%d9%86%da%af%d8%a7%d8%b1%db%8c-%d9%87%d8%a7%db%8c-%d8%aa%d9%84%da%af%d8%b1%d8%a7%d9%85-%d8%aa%d8%a7-%da%86%d9%87-%d8%ad%d8%af/
مهندسی داده :
ممنون از اطلاعات مفیدتون . اگر لینکی راجع به معماری تلگرام هم دارید خوشحال میشوم به اشتراک بگذارید.
با سلام
دقیقا کاساندرا هم قابلیت زماندار بودن سطر ها رو داره، مثلا میشه تنظیمش کرد که یک سند بعد از مدتیخود به خود حذف بشه
مثلا
insert into discussions (uid, subject) VALUES (now(), ‘hello’) using ttl 100;
http://stackoverflow.com/questions/19067220/check-a-rows-ttl-in-cassandra
مهندسی داده :
با تشکر از توجه شما . حق با شماست و کاساندرا هم می تونه برای ذخیره موقت داده ها استفاده بشه هر چند به نظر راه حل مناسبی برای ذخیره چت خصوصی نباشه چون به ادعای تلگرام داده های چت خصوصی روی سرورهاشون ذخیره نمیشه .
سلام. متشکر از مطالب مفید و ارزنده شما.
لطفا تا میتوانید در رابطه با بیگ دیتا و بررسی جداول سرورهای تلگرام و فیس بوک مطلب ارائه کنید. به نظر من آموزش کاساندرا یا امثالهم فقط با بررسی ساختار جداول فیس بوک و تلگرام میتواند در ذهن ماندگار باشد.
در ضمن ادامه مطلب کجاست؟ منتظر ارائه آن هستم.
با تشکر مجدد و آرزوی موفقیت همه دوستان.
مهندسی داده :
با سلام و تشکر از دلگرمی شما . متاسفانه فرصت کمی در اختیار نویسندگان سایت برای تکمیل موارد فوق وجود دارد اما بخش دوم این مقاله را در اولویت قرار می دهیم.
عالی بود. منتظر ادامه بحث هستیم.