
آشنایی با الگوریتم Word2Vec گوگل
برای بسیاری از روشهای پردازش متن و NLP، نیاز به نمایش عددی کلمات و متون داریم تا بتوانیم از انواع روشهای عددی حوزه یادگیری ماشین مانند اکثر الگوریتم های دسته بندی روی لغات و اسناد استفاده کنیم. یکی از رهیافت هایی که در این حوزه بسیار رایج شده است ، نمایش برداری کلمات و جملات است .
فرض کنید فرهنگ لغتی داریم با N کلمه و لغت که به ترتیب الفبایی مرتب شده اند و هر لغت یک مکان مشخص در این فرهنگ لغت دارد. حال برای نمایش هر کلمه، برداری در نظر میگیریم با طول N که هر خانه آن، متناظر با یک لغت در فرهنگ لغت ماست که برای راحتی کار فرض می کنیم شماره آن خانه بردار، همان اندیس لغت مربوطه در این فرهنگ لغت خواهد بود . با این پیش فرض، برای هر لغت ما یک بردار به طول N داریم که همه خانه های آن بجز خانه متناظر با آن لغت صفر خواهد بود. در خود ستون متناظر با لغت عدد یک ذخیره خواهد شد.(One-Hot encoding) با این رهیافت، هر متن یا سند را هم می توان با یک بردار نشان داد که به ازای هر کلمه و لغتی که در آن به کار رفته است ، ستون مربوطه از این بردار برابر تعداد تکرار آن لغت خواهد بود و تمام ستون های دیگر که نمایانگر لغاتی از فرهنگ لغت هستند که در این متن به کار نرفته اند، برابر صفر خواهد بود .
به این روش نمایش متون، صندوقچه کلمات یا Bag Of Words می گوییم که بیانگر این است که برای هر لغت در صندوقچه یا بردار ما، مکانی درنظر گرفته شده است .
با یک مثال این مفهوم را بیشتر توضیح می دهیم . فرض کنید که دو جمله زیر را داریم :
Sentence 1: “The cat sat on the hat”
Sentence 2: “The dog ate the cat and the hat”
برای این دو جمله فرهنگ لغت ما عبارت خواهد بود از :
{ the, cat, sat, on, hat, dog, ate, and }
و نمایش صندوقچه کلمات این دو جمله طبق توضیح از قرار زیر است :
Sentence 1: { 2, 1, 1, 1, 1, 0, 0, 0 }
Sentence 2 are: { 3, 1, 0, 0, 1, 1, 1, 1}
در مورد استفاده عملی از این روش و پیاده سازی آن برای پیش بینی لحن احساسات کاربران یا مثبت و منفی بودن نظرشان راجع به یک فیلم، از این آموزش سایت هم می توانید بهره ببرید.
با این روش ما دو بردار عددی داریم که حال می توانیم از این دو در الگوریتم های عددی خود استفاده کنیم. با وجود سادگی این روش ، اما معایب بزرگی این بر آن مترتب است. مثلاً اگر فرهنگ لغت ما صد هزار لغت داشته باشد ، به ازای هر متن ما باید برداری صد هزارتایی ذخیره کنیم که هم نیاز به فضای ذخیره سازی زیادی خواهیم داشت و هم پیچیدگی الگوریتم ها و زمان اجرای آنها را بسیار بالا می برد .
از طرف دیگر در این نحوه مدلسازی ما فقط کلمات و تکرار آنها برای ما مهم بوده است و ترتیب کلمات یا زمینه متن (اقتصادی ، علمی ، سیاسی و …) تاثیری در مدل ما نخواهد داشت .
روشی دیگر که توسط گوگل در سال ۲۰۱۳ پیشنهاد شده است و روشی بسیار کارآمد و مناسب برای نمایش لغات و متون و پردازش آنها است روش Word2Vec است که هدف از این مقاله هم آشنایی اولیه با این روش قدرتمند، نمایش برداری کلمات است که می تواند در بسیاری از کاربردهای نوین پردازش متن مانند سنجش احساسات، جستجوی متون مشابه یا پیشنهاد اخبار یا کالای مشابه استفاده شود.
در این روش به کمک شبکه عصبی یک بردار با اندازه کوچک و ثابت برای نمایش تمام لغات و متون در نظرگرفته شده و با اعداد مناسب در فاز آموزش مدل یا training برای هر لغت این بردار محاسبه می شود. در این بردار هر ستون ، نمایشگر کلمه یا ویژگی خاصی نیست و فقط یک عدد را نمایش می دهد. اگر این بردار را ۴۰۰ تایی فرض کنید، یک فضای ۴۰۰ بعدی خواهیم داشت که هر لغت در این فضا یک نمایش منحصر بفرد خواهد داشت. برای افزایش دقت این روش، مجموعه داده اولیه که برای آموزش مدل مورد نیاز است، باید حدود چند میلیارد لغت را که درون چندین میلیون سند یا متن به کار رفته اند، در برگیرد. بعد از ایجاد بردارهای مرتبط با هر لغت، برای نمایش برداری هر متن یا خبر ، می توان بردار تک تک کلمات به کار رفته در آنرا یافته و میانگین اعداد هر ستون را به دست آورد که نتیجه آن یک بردار برای هر متن یا سند خواهد بود.
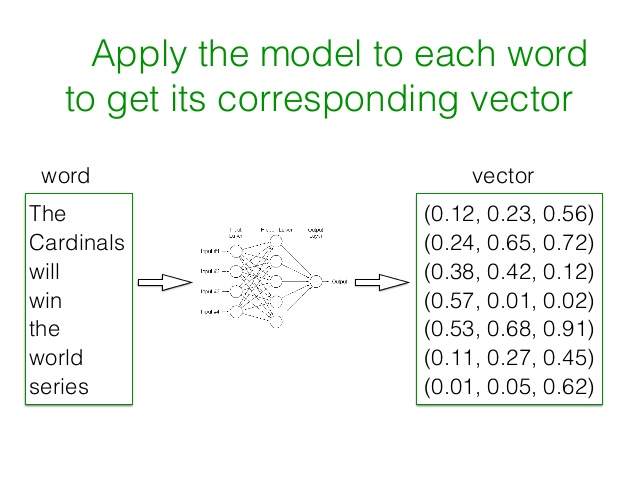

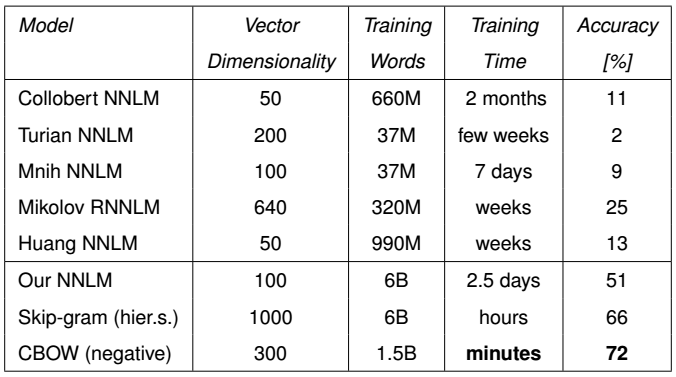
سرعت این آموزش هم بسیار بالاست و در عرض چند ساعت و یا چند دقیقه (بسته به این که از کدام یک از دو الگوریتم آموزش آن استفاده کنیم) می توان حجم عظیمی از داده ها را به این الگوریتم داد و بردارهای لغات را ایجاد کرد. نمونه ای از مقایسه این الگوریتم با دو رهیافت مختلف آن که در ادامه توضیح داده می شود، از لحاظ حجم داده ها (B برای میلیارد و M برای میلیون)، زمان لازم برای ایجاد بردارها، دقت و ابعاد بردارها در زیر آورده شده است. در این جدول، روش Word2Vec (با دو الگوریتم ایجاد بردار CBOW و Skip-gram) با روشهای مدلسازی زبان با شبکه عصبی (NNLM) مقایسه و ارزیابی شده است.
این روش که الگوریتم آن به صورت متن باز نیز منتشر شده است و کتابخانه های مختلفی برای زبانهای مختلف برای کار با آن تولید شده است، زمانی که توسط گوگل بر روی حجم بالای متون و اطلاعات به کار رفته است ، نتایج بسیار شگرفی را به همراه داده است .
مثلا اگر بردار لغت پادشاه را منهای بردار لغت مرد کنیم ، نتیجه به بردار کلمه ملکه بسیار نزدیک است.
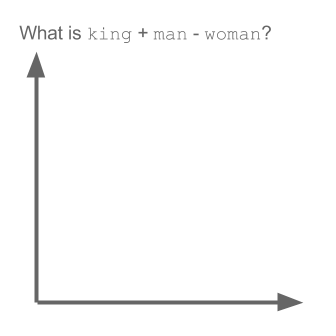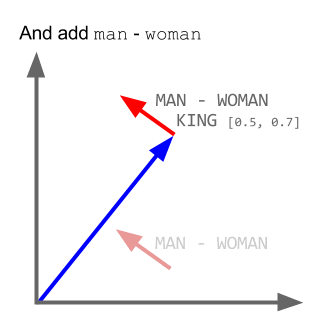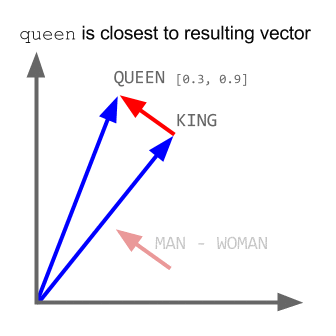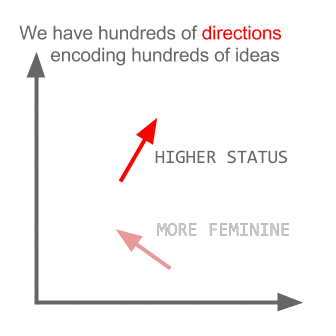
مثالهایی از روابط بین بردارهای تولید شده توسط این الگوریتم را در زیر می توانید ببنید :
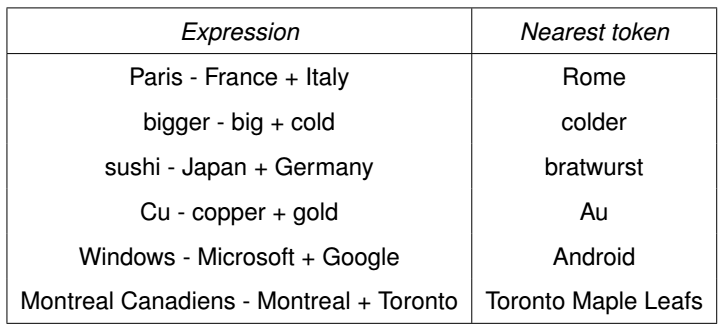
همانطور که مشاهده می کنید اگر بردار فرانسه را از پاریس کم کنیم و به ایتالیا اضافه کنیم ، نتیجه به بردار رم بیشترین نزدیکی را دارد یا به عبارتی می توان گفت که فرانسه به پاریس مثل ؟ است به ایتالیا که این علامت سوال همان نتیجه محاسبات برداری ما روی این سه لغت است که به رم ختم شده است یا شباهت ویندوز به مایکروسافت مثل شباهت ؟ است به گوگل که این علامت سوال هم وقتی در فضای برداری ایجاد شده گوگل، محاسبه شده است به اندروید نزدیک شده است . (خارق العاده!!!)
اما این روش چگونه کار می کند که با این دقت می تواند کلمات را مدل کند ؟
جزئیات دقیق این الگوریتم را از این مقاله آموزشی می توانید دریافت کنید اما به طور مختصر ، این الگوریتم برای ساخت بردارهای کلمات از یکی از دو روش زیر استفاده می کند :
– continuous bag-of-words (CBOW)
– Skip-gram
این دو روش که هر دو یک شبکه عصبی ساده هستند که بدون وجود لایه پنهانی که در اغلب روشهای شبکه عصبی وجود دارد، به کمک چند قانون ساده، بردارهای مورد نیاز را تولید می کنند. در روش کیف لغات پیوسته (CBOW) ، ابتدا به ازای هر لغت یک بردار با طول مشخص و با اعداد تصادفی (بین صفر و یک) تولید می شود. سپس به ازای هر کلمه از یک سند یا متن، تعدادی مشخص از کلمات بعد و قبل آنرا به شبکه عصبی می دهیم (به غیر از خود لغت فعلی) و با عملیات ساده ریاضی، بردار لغت فعلی را تولید می کنیم (یا به عبارتی از روی کلمات قبل و بعد یک لغت، آنرا حدس می زنیم) که این اعداد با مقادیر قبلی بردار لغت جایگزین می شوند. زمانی که این کار بر روی تمام لغات در تمام متون انجام گیرد، بردارهای نهایی لغات همان بردارهای مطلوب ما هستند.
روش Skip-gram برعکس این روش کار می کند به این صورت که بر اساس یک لغت داده شده ، می خواهد چند لغت قبل و بعد آنرا تشخیص دهد و با تغییر مداوم اعداد بردارهای لغات، نهایتا به یک وضعیت باثبات می رسد که همان بردارهای مورد بحث ماست.
نحوه کار این دو روش را در شکل زیر می توانید ببینید :
 برای یادگیری و کار با این روش نوین و موثر می توانید از این آموزش ساده و کاربردی کگل استفاده کنید. نگاه به بعضی از نتایجی که بعد از ساخت بردارهای لغت در این آموزش با کمک کتابخانه پایتون Gensim به دست آمده است هم خالی از لطف نیست .
برای یادگیری و کار با این روش نوین و موثر می توانید از این آموزش ساده و کاربردی کگل استفاده کنید. نگاه به بعضی از نتایجی که بعد از ساخت بردارهای لغت در این آموزش با کمک کتابخانه پایتون Gensim به دست آمده است هم خالی از لطف نیست .

پی نوشت :
یکی دیگر از الگوریتم هایی که مشابه با روش گوگل، برای نمایش برداری کلمات و ایجاد یک بردار با در نظر گرفتن همجواری کلمات توسط دانشگاه استنفورد پیشنهاد شده است روش GloVe: Global Vectors for Word Representation است که کارآیی آن هم تقریباً مشابه با روش Word2Vec ارزیابی شده است .
در این روش، بردار اولیه بر اساس طول همجواری (Window Size) با شمارش تعداد ظاهر شدن دو کلمه کنار هم در این بازه ، تشکیل می شود. مثلا برای نه جمله زیر که پردازش اولیه روی آنها صورت گرفته است ، ماتریس زیر شکل می گیرد. (ترتیب کلمات زیر ماتریس نوشته شده است)
# nine input sentences texts = [['human', 'interface', 'computer'], ['survey', 'user', 'computer', 'system', 'response', 'time'], ['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'], ['user', 'response', 'time'], ['trees'], ['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey']] # word-word co-occurrence matrix, with context window size of 5 [[۰ ۱ ۱ ۱ ۱ ۱ ۱ ۱ ۰ ۰ ۰ ۰] [۱ ۰ ۱ ۰ ۰ ۲ ۰ ۰ ۱ ۰ ۰ ۰] [۱ ۱ ۰ ۰ ۰ ۱ ۰ ۱ ۱ ۰ ۰ ۰] [۱ ۰ ۰ ۰ ۱ ۱ ۲ ۲ ۰ ۰ ۰ ۰] [۱ ۰ ۰ ۱ ۰ ۱ ۱ ۱ ۰ ۰ ۱ ۱] [۱ ۲ ۱ ۱ ۱ ۲ ۱ ۲ ۳ ۰ ۰ ۰] [۱ ۰ ۰ ۲ ۱ ۱ ۰ ۲ ۰ ۰ ۰ ۰] [۱ ۰ ۱ ۲ ۱ ۲ ۲ ۰ ۱ ۰ ۰ ۰] [۰ ۱ ۱ ۰ ۰ ۳ ۰ ۱ ۰ ۰ ۰ ۰] [۰ ۰ ۰ ۰ ۰ ۰ ۰ ۰ ۰ ۰ ۲ ۱] [۰ ۰ ۰ ۰ ۱ ۰ ۰ ۰ ۰ ۲ ۰ ۲] [۰ ۰ ۰ ۰ ۱ ۰ ۰ ۰ ۰ ۱ ۲ ۰]] # (rows/columns represent words: # "computer human interface response survey system time user eps trees graph minors", # in that order)
در مرحله بعد، بر اساس نزدیکی یا دوری دو کلمه به یکدیگر، این اعداد ، وزن دهی می شوند :
# same row/column names as above [[ ۰٫ ۰٫۵ ۱٫ ۰٫۵ ۰٫۵ ۱٫ ۰٫۳۳ ۱٫ ۰٫ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۱٫ ۰٫ ۰٫ ۲٫ ۰٫ ۰٫ ۰٫۵ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۱٫ ۰٫ ۱٫ ۰٫۵ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫۲۵ ۱٫ ۲٫ ۱٫۳۳ ۰٫ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫۳۳ ۰٫۲ ۱٫ ۰٫ ۰٫ ۰٫۵ ۱٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫۵ ۱٫ ۱٫۶۷ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫۷۵ ۰٫ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۱٫ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۱٫۵ ۱٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۲٫ ] [ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ۰٫ ]]
در مرحله آخر ، لگاریتم این اعداد گرفته شده و با روش تجزیه ماتریس (Matrix Factorization)، ابعاد ماتریس کاهش یافته شده و بردارهای نهایی شکل میگیرد.
برای مشاهده دقیق تر این روش و مقایسه آن با روش پیشنهادی گوگل از این مقاله هم می توانید استفاده کنید.
برای تکمیل این مبحث و بررسی فرمولهای ریاضی مشابهت و سایر منابع مفید، این مقاله را هم از دست ندهید. سایت TagOverflow هم یک نمای گرافیکی از پیاده سازی این الگوریتم روی حوزه های مختلف متنی است. مثال زیر از این سایت و با توجه به اطلاعات StackOverflow ایجاد شده است :
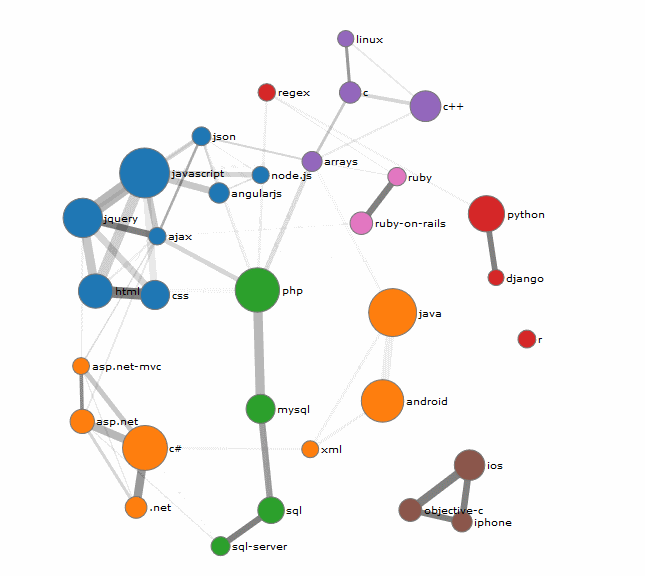
ممنون میشم در مورد مقایسه این ابزار با ابزار GloVe که توسط استنفورد پیاده سازی شده هم مطلبی قرار دهید
مهندسی داده :
با تشکر از پیشنهاد خوب شما . به انتهای مقاله این بخش اضافه شد .
آقا دمت گرم دستت درد نکنه. مطالبی که میذاری ارزشش با طلا برابری می کنه.
واقعاَ ازت ممنونم.
خیلی عالی بود.. در باره sentance2vec هم ممنون میشم مطلب بذارید.
با تشکر از مقاله خوب شما
یک سوال داشتم. اینکه الگوریتم جملات رو بر چه اساسی تشخیص میده؟ و اینکه کلمات کنار هم در یک ظاهر بشن اهمیت داره؟
در مورد سوال اول، تا جاییکه کدها و مثالهای مرتبط با الگوریتم Word2Vec را بررسی کرده ام، انتهای جملات با همان روشهای معمول نقطه گذاری مشخص می شود . البته در مثالهایی مشابه با این آدرس، فایلها خط به خط خوانده شده و کلمات آنها به صورت پشت سرهم برای ساخت مدل استفاده شده است و به نظر می رسد انتهای جملات، چندان مهم نباشد. در مورد سوال دوم هم همانطور که در شکل مشخص است، توالی و مکان قرار گیری کلمات هم در ساخت بردار نهایی هر لغت موثر است و به همین دلیل هم زمینه یا بستر یک کلمه، مشخص شده و شباهت کلمات بر اساس این بسترها شکل می گیرد.
سلام و عرض ادب خیلی ممنونم از مطالب مفیدتون که واضح هم توضیح دادید موفق باشید
با سلام
مطالب سایتتون واقعا عالی بود میشه منابع را هم بگذارید تشکر فراوان
بسیار ممنون از مطلب با ارزش و توضیح روان شما