
آموزش اسپارک: مفاهیم پایه
مقدمه
در ادامه مباحث آموزشی اسپارک، در این نوشتار به توضیح مفاهیم پایه اسپارک و چگونگی استفاده از آن درون یک کتابچه پایتون (نوت بوک) خواهیم پرداخت. همانطور که می دانید بسیاری از چارچوب های سنتی پردازش داده برای اجرا درون یک کامپیوتر طراحی شده بودند. اما مجموعه داده های امروزی برای ذخیره شدن روی یک کامپیوتر بیش از حد بزرگ هستند. حتی اگر فرض کنیم که یک مجموعه داده بتواند در یک کامپیوتر هم ذخیره شود (مانند مجموعه داده این آموزش)، پردازش آن با استفاده از چندین کامپیوتر بسیار سریع تر خواهد بود. این دلایل ما را به سمت چارچوبهای پردازش توزیع شده داده هدایت می کند : چارچوب هایی مثل توزیع و تجمیع (Map/Reduce) و اسپارک .
اسپارک دارای پیاده سازی بسیار بهینه و کارآمدی از تبدیل ها و عملیات مورد نیاز داده پردازی است. البته نقطه قوت اصلی اسپارک در توزیع این عملیات پردازشی در یک کلاستر (شبکه ای سیستم ها) و پنهان کردن جزییات و مسایل فنی آن از دید برنامه نویس و استفاده کننده است. اسپارک با تمرکز بر مقیاس پذیری و کارایی به گونه ای طراحی شده است که با استفاده از آن می توانید به توسعه ی راه حل خود با استفاده از یک مجموعه داده ی کوچک بر روی رایانه شخصی تان پرداخته و سپس با استفاده از همان کد به پردازش مجموعه ای ترابایتی یا حتی پتا بایتی در سرتاسر یک خوشه ی (کلاستر) توزیع شده بپردازید.
در این آموزش، تبدیل های زیر تشریح خواهند شد:
map() , mapPartitions(), mapPartitionsWithIndex(), filter()
flatMap(), reduceByKey(), groupByKey()
همچنین به توضیح عملیات زیر خواهیم پرداخت:
first(), take(), takeSample() , takeOrdered() , collect()
count(), countByValue(), reduce(), top()
و در طول این آموزش، با توابع زیر نیز آشنا خواهید شد:
cache(), unpersist(),id(), setName()
شما می توانید در صورت نیاز به اطلاعات بیشتر، جزئیات این متدها را در مستندات کتابخانه PySpark مشاهده نمایید.
۱- استفاده از کتابچه های محاسباتی و یکپارچه سازی آن با پایتون
۱-۱ مقدمه ای بر کتابچه های محاسباتی
در بخش اول از آموزش اسپارک به معرفی اکانت رایگان شرک DataBricks و پنل وبی پرداختیم که این شرکت برای تست و اجرای برنامه های اسپارک در اختیار علاقه مندان میگذارد. اساس کار این وب سایت هم استفاده از کتابچه های محاسباتی پایتون (INotebook) برای اجرای کدهای اسپارک است. همانطور که اشاره شد، یک کتابچه یک فایل متنی ساده است که از دنباله ای خطی از سلول ها تشکیل شده است که هر سلول، یا حاوی کدهای اجرایی (پایتون، آر، اسکالا و …) است و یا متون و توضیحاتی که معمولاً با زبان نشانه گذاری ساده و مخصوصی به نام مارک داون MarkDown نوشته می شوند. این سلول ها هنگام نمایش به کاربر، به متون قابل نمایش در وب (HTML) تبدیل می شوند. البته ما نمی توانیم ترکیب هر دو را (هم کد و هم توضیحات متنی به صورت توامان) درون یک سلول داشته باشیم.
نتایج سلول های کد هم زیر همان سلول نمایش داده میشود؛ مجموعه این سه قابلیت یعنی نوشتن همزمان توضیحات، کدها و نتایج آنها در یک محیط ، کتابچه ها را به ابزاری قدرتمند برای مقاصد آموزشی، یادداشت برداری در هنگام اجرای کدها و اجرای آنها در محیط مرورگر بدون نیاز به یک محیط برنامه نویسی، تبدیل کرده است. به همین دلیل هم یکی از رایجترین روشهای نمایش کدها، توضیحات و خروجی های آنها توسط دانشمندان داده ، همین کتابچه ها هستند.
کتابچههای پایتون
برای فعال کردن کتابچه ها در سیستم خود نیاز به نصب Jupyetr Notebook دارید که با نصب آن و اجرای دستورات مرتبط، یک وب سرور ساده شروع به کار می کند و پشت پورت ۸۸۸۸ کتابچه ها را سرویس دهی خواهد کرد یعنی سلول ها را اجرا و صفحه وب خروجی رابه کاربر نشان میدهد. کافیست بعد از نصب و اجرای آن، در مرورگر این آدرس را بزنید http://localhost:8888 تا صفحه مدیریت کتابچه ها برایتان باز شود و بتوانید کتابچه جدیدی ایجاد کرده یا کتابچه های قبلی را ویرایش نمایید. بنابراین در ذهن داشته باشید که برای اجرای کتابچه های محاسباتی، به یک سرور نیاز داریم که هنگام اجرای یک سلول کد یا توضیحات، کدها و یا توضیحات به این سرور ارسال شده و نتیجه اجرای آن در سلول های نتیجه به کاربر، نمایش داده می شود.
سلول های کد درون یک کتابچه پایتون (هنگام ایجاد یک کتابچه، زبان برنامه نویسی سلول های کد از شما پرسیده می شود) به شما این اجازه را می دهند تا دستورات دلخواه پایتون را درست مانند آنچه درون کنسول پایتون دارید، اجرا کنید. کافیست نشانگر موس را درون سلول قرار دهید و سپس دکمه های “Shift” + “Enter” را برای اجرای کد و انتقال به سلول بعدی انتخاب کنید. همچنین با استفاده از دکمه های “Ctrl” + “Enter” می توانید کد را اجرا کرده و در همان سلول باقی بمانید. این دستورات در هر دو نوع سلول های کد و سلول های متنی کار می کند.
اگر به کدهای نوشته شده در این مقالات علاقه مندید می توانید به اینجا مراجعه کنید تا نسخه اصلی این مقالات آموزشی را مشاهده و در صورت نیاز از کدهای نوشته شده آن استفاده کنید.
برای انجام کدهای موجود در این آموزش، طبق توضیحات بخش اول ، وارد اکانت کاربری خود در سایت DtaBricks شوید و یک کتابچه جدید ایجاد کرده و کدهای زیر را درون سلول ها کپی کنید و با زدن کلید Ctrl+Enter نتیجه را مشاهده نمایید. اگر هم قصد اجرای این کدها روی سیستم خود و از طریق کتابچه ها دارید، این آموزش نصب اسپارک را از دست ندهید.
علاوه بر کتابچههای آنلاین و محیط توسعه دیتابریکز، میتوانید از محیط colab گوگل هم برای اجرای دستورات زیر استفاده کنید. آموزش سریع اینکار را در این آدرس خواهید یافت.
۲-۱ وضعیت یک کتابچه
هنگام کار با کتابچه ها باید حواستان باشد که تمام سلول ها را اجرا کنید. نوت بوک یا همان کتابچه، ابزاری با قابلیت نگهداری سابقه است، بدین معنی که متغیرها و مقادیر آنها تا زمانی که نوت بوک به سرور متصل باشد (در Databricks) یا هسته مجدداً راه اندازی شود (ریست کردن سرور هنگام اجرا روی سیستم های شخصی)، در آن نگهداری می شود. اگر شما تمام سلول های کد (که به هم وابسته هستند) را اجرا نکنید، این احتمال وجود دارد که متغیرهای شما به درستی مقداردهی نشده و بعداً در هنگام اجرا با شکست مواجه شوند.
مثلاً اگر شما ده سلول کد دارید و به ترتیب همه را اجرا کرده اید، نتایج را زیر هر سلول مشاهده خواهید کرد. حال اگر مقدار متغیرها یا کدهای سلول سوم را تغییر دهید ومجددا اجرا کنید، تنها خروجی همان سلول بروز رسانی میشود و بقیه سلول ها مقادیر قدیمی را دارند بنابراین به ترتیب (یا با دستور اجرای تمام سلول ها) باید سلول های بعدی را اجرا کنید تا مقادیر جدید جانشین خروجی های قبلی شوند.
۳-۱ استفاده از کتابخانه ها
مطمئناً برای نوشتن کدهای حرفه ای به کتابخانه های مختلفی درون یک کتابچه نیاز خواهیم داشت. ما می توانیم کتابخانه های استاندارد پایتون (ماژول ها) را به روش معمول، درون هر سلول که به آن نیاز داریم، ایمپورت کنیم. در این آموزش ما کتابخانه های مورد نیاز و دستورات ایمپورت متناظر را به شما اعلام خواهیم کرد. کتابخانه های اصلی همه در کتابچه های سایت DataBricks در دسترس هستند اما اگر روی سیستم خودتان قصد نصب کتابچه ها و استفاده از آن را برای اجرای اسپارک دارید، کتابخانه ها را باید در نسخه پایتون خودتان به صورت دستی نصب کنید .
2-مروری بر معماری اسپارک و شروع کار با PySpark
همانطور که در بخش اول توضیح داده شد، برای اجرای کدهای اسپارک به دو مولفه اصلی نیاز داریم . یکی درایور (هماهنگ کننده یا مدیربرنامه)که وظیفه توزیع و مدیریت کارها را بر عهده دارد و دومی، مولفه اجرا کننده (Worker) که کارهای محاسباتی و پردازشی را انجام داده و نتیجه را به هماهنگ کننده یا درایور برمیگرداند. به صورت فنی تر اگر بخواهیم صحبت کنیم، هر درخواست پردازش از سمت کاربر یک Job را تشکیل می دهد که به درایور اسپارک تحویل داده میشود . درایور اسپارک، این درخواست پردازشی را به چندین وظیقه Task تقسیم کرده بین اجرا کننده ها توزیع می کند . اجرا کننده ها (Workers) معمولاً درون یک کلاستر (شبکه بهم پیوسته) قرار دارند. Task ها بعد از اتمام، نتایج را به درایور یا مدیربرنامه تحویل می دهند.
در بخش ۱ ملاحظه نمودید که کدهای پایتون خود را درون سلول های یک کتابچه محاسباتی، خواهیم نوشت و همانجا هم اجرا خواهیم کرد. زمانی که از Databricks استفاده می کنید، این کد درون ماشین مجازی کامپیوتر درایور (و نه ماشین مجازی سیستم های اجرا کننده) اجرا می شود یعنی در این آموزش، ما از امکانات شبکه و توزیع کارها بین گره های محاسباتی یک کلاستر استفاده نخواهیم کرد و تمام دستورات اسپارک ما به صورت محلی اجرا خواهند شد. با این وجود، قابلیت های اصلی اسپارک را در این سری آموزشی به صورت کامل یاد خواهید گرفت. همچنین زمانی که ما از یک نوت بوک IPython استفاده می کنیم، این کد درون هسته ی مرتبط با نوت بوک اجرا می شود که در برنامه های واقعی شاید نیاز به اجرای مستقیم کدهای پایتون بدون استفاده از کتابچه ها داشته باشید.
برای استفاده از اسپارک و امکانات و توابع آن (API) ما به SparkContext یا همان بستر اجرایی اسپارک نیاز داریم. برای اجرای اسپارک، هر برنامه ی کاربردی جدید در آن را با ایجاد یک SparkContext شروع خواهید کرد. پس از ایجاد بسترگاه اسپارک، اولین کاری که انجام میشود تقاضای چند هسته سی پی یو از سرور اصلی برای اجرای دستورات آتی اسپارک است. سرور هم این هسته ها را به صورت جداگانه تنها به شما اختصاص می دهد به طوری که این هسته ها نمی توانند در سایر برنامه ها و یا توسط سایر کاربران استفاده شوند (البته تا پایان اجرای کدهای شما). هنگام استفاده از امکانات Databricks، بسترگاه اسپارک به طور خودکار تحت عنوان sc برای شما ایجاد خواهد شد.
۱-۲ بررسی یک کلاستر اسپارک
شکل زیر یک کلاستر اسپارک را مطابق با توضیحات بالا نمایش می دهد که در آن هسته های اختصاص داده شده به یک برنامه با خط چین بنفش مشخص شده اند. (نکته: در نسخه ی عمومی و رایگان شرکت DataBricks اجرا کننده در حقیقت وجود ندارد و Master به تنهایی تمام کدها را اجرا خواهد کرد که در شکل نمایش داده نشده است).
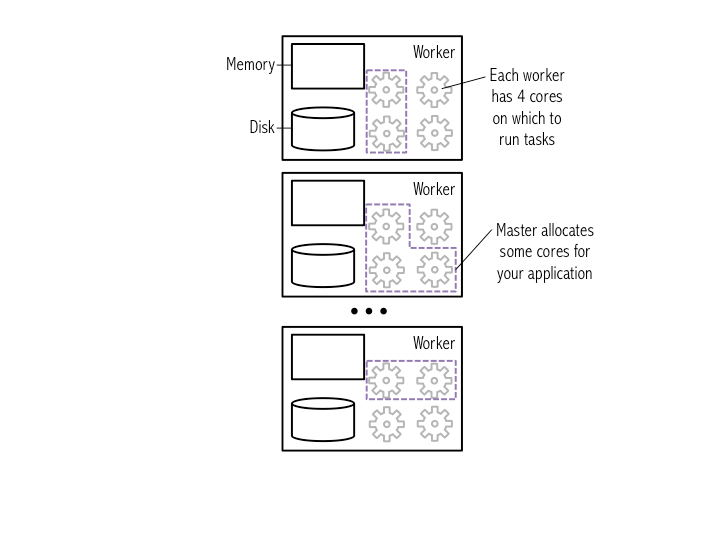
شما می توانید جزئیات برنامه ی اسپارک خود را در رابط کاربری تحت وب اسپارک (UI spark web) مشاهده کنید. این رابط کاربری در Databricks با رفتن به منوی Clusters قابل دسترسی است و با انتخاب گزینه ی View Spark UI شما می توانید کلاستر (مجموعه از کامپیوترها که وظیفه اجرای اسپارک را برعهده دارند.) خود را مشاهده نمایید. (زمانی که شما اسپارک را بر روی سیستم خود(لوکال هاست) و به صورت محلی استفاده می کنید، می توانید آن را در آدرس localhost:4040 مشاهده کنید). در رابط کاربری تحت وب، در سربرگ Jobs، شما می توانید لیستی از کارهایی که زمان بندی شده و آماده اجرا هستند و یا اجرا شده اند را مشاهده کنید. احتمالاً هنور هیچ کاری را اجرا نکرده اید و بنابراین مورد خاصی در حال حاضر در این بخش وجود نخواهد داشت، اما در بخش های بعدی به این صفحه باز خواهیم گشت.
در Databricks، برنامه هماهنگ کننده یا درایور، “Databricks Shell” است و زمانی که برنامه را بر روی هاست محلی اجرا می کنید، “PySparkShell” برنامه ی درایور اسپارک شما می باشد. در هر صورت، این برنامه ی درایور شامل کدهای اصلی برنامه بوده، توزیع داده ها در شبکه و سپس انجام تبدیلات و عملیات پردازشی را بر روی مجموعه داده های توزیع شده بر عهده دارد.
برنامه ی درایور از طریق SparkContext یا بستراجرایی اسپارک به شبکه محاسباتی در نظر گرفته شده برای اجرای دستورات اسپارک دسترسی دارد. (SparkContext(sc، نقطه ورودی اصلی برای تمامی امکانات اسپارک است. از طریق یک Sc می توانید مجموعه داده های توزیع شده برگشت پذیر معروف اسپارک یا همان RDD ها را در یک شبکه به راحتی ایجاد و با آنها شروع به کار کنید بدون اینکه درگیر پیچیدگیهای توزیع شدگی و روابط بین سیستم ها در یک کلاستر شوید.
۲-۲ ویژگی های SparkContext
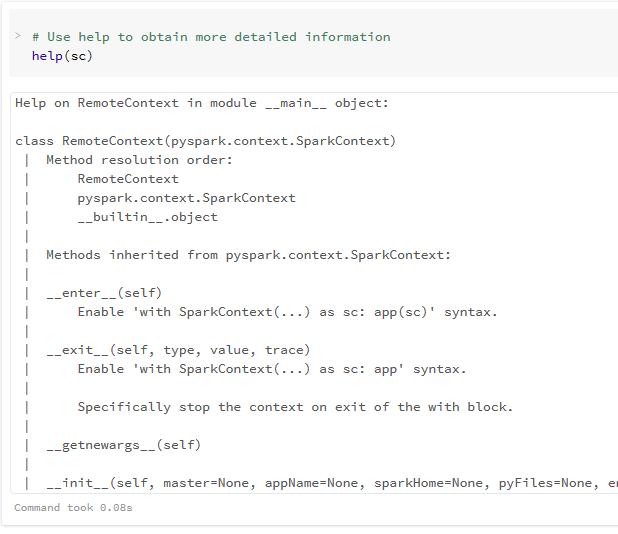
شما می توانید از تابع پایتونی dir برای مشاهده ی لیست همه ویژگی های در دسترس برای SC (شامل متدها و صفات) استفاده کنید.
۲-۳ استفاده از راهنما
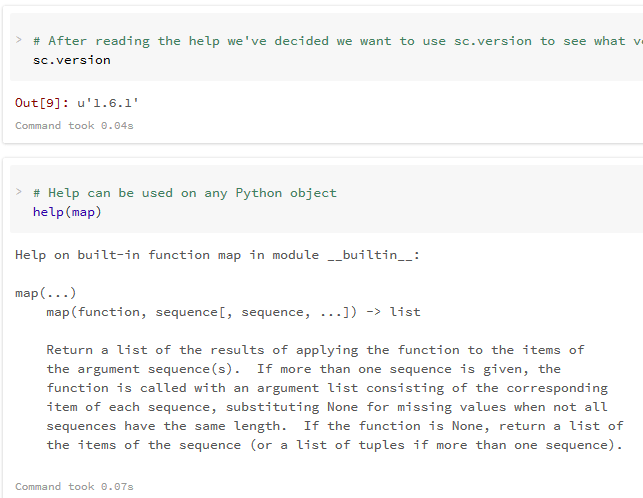
علاوه بر کد بالا، شما می توانید به راحتی از تابع پایتونی ()help برای مشاهده لیست همه ی ویژگی ها و توابع Sc به همراه مثال های مربوط به آن استفاده کنید.
۳- استفاده از RDD ها و ایجاد زنجیره ای از تبدیلات و عملیات
کار با اولین RDD
در اسپارک، همیشه کار خود را با یک مجموعه داده ی پایه (Base RDD) که قرار است پردازشی روی آن انجام دهیم، شروع می کنیم . اگر این مجموعه داده توزیع شده برگشت پذیر یا همان RDD که ساختمان داده اصلی در اسپارک است، وجود نداشت به راحتی از روی داده های موجود مانند داده های موجود در HDFS، بانکهای اطلاعاتی، فایلها و سایر منابع داده ای، آنرا ایجاد خواهیم کرد. پردازش اصلی داده های ما در اسپارک مجموعه عملیات و تبدیلاتی است که روی این RDD پایه،انجام خواهیم داد و چون در فرهنگ اسپارک، یک RDD تغییر ناپذیر است، با هر تبدیل یا انجام یک عملیات، یک RDD جدید ایجاد خواهد شد تا زمانی که به جواب مورد نیاز خود رسیده و پردازش ما به اتمام برسد.
توجه داشته باشید که اسپارک از روش ارزیابی با تاخیر (lazy evaluation) استفاده می کند، بنابراین تبدیل ها تا زمانی که یک عملیات (action) فراخوانی نشود، اجرا نخواهد شد.
برای درک بهتر RDD ها ما چند تمرین زیر را انجام خواهیم داد:
- ایجاد یک مجموعه ی پایتون شامل ۱۰۰۰۰ عدد صحیح
- ایجاد یک RDD پایه در اسپارک از مجموعه ی بالا
- کاهش یک رقمی هر کدام از اعداد با استفاده از تابع map
- انجام عملیات collect برای مشاهده نتایج
- انجام عمل count برای شمارش اعداد
- اعمال تبدیل filter و مشاهده ی نتایج با استفاده از collect
- آشنایی با توابع لامبدا
- بررسی چگونگی عملکرد lazy evaluation (ارزیابی با تاخیر) و معرفی چالش های اشکال زدایی مربوط به آن
۱-۳ ایجاد یک مجموعه ی پایتون از اعداد صحیح در بازه ی ۱ تا ۱۰۰۰۰
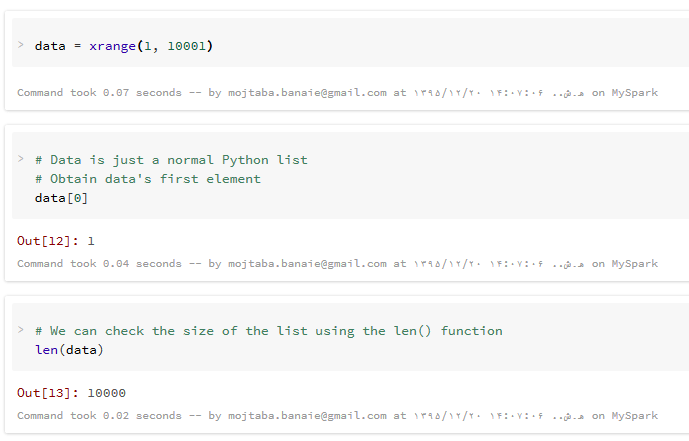
ما از تابع ()xrange برای ایجاد لیستی از اعداد صحیح استفاده خواهیم کرد. مزیت این تابع در تولید اعداد این است که مقادیر را زمانی تولید می کند که به آنها نیاز داریم. تفاوت این تابع با تابع ()range این است که تابع ()range ، کل لیست حاوی بازه اعداد داده شده را یکجا تولید می کند که این امر برای اعداد بسیار بزرگ، مشکل کمبود حافظه را در برخواهد داشت در حالی که تابع ()xrange هر عنصر لیست را وقتی که به آن نیاز داریم، تولید می کند یعنی وقتی یک عنصر تولید شد و داخل حلقه برنامه، از آن استفاده کردیم، هنگام درخواست عدد بعدی توسط برنامه، در همان لحظه تولید و تحویل برنامه خواهد شد. به همین دلیل هنگام کار با بازه های بزرگ، استفاده از تابع xrange باعث استفاده ی موثرتر از حافظه خواهد شد.
این اعداد را به صورت زیر تولید می کنیم :
۲-۳ توزیع داده ها در اسپارک و استفاده از یک مجموعه برای تولید RDD
در اسپارک، یک مجموعه داده لیستی از عناصر داده ای است که خود این لیست به چندین پارتیشن یا بخش مختلف شکسته می شود و هر پارتیشن هم روی یک کامپیوتر ذخیره می شود. هر پارتیشن حاوی یک زیرمجموعه ی منحصربفرد از محتوای لیست است. اسپارک این مجموعه داده توزیع شده را مجموعه داده توزیع شده ی برگشت پذیر (RDDs) می نامد.
یکی از ویژگی های اصلی اسپارک، در مقایسه با دیگر چارچوب های تحلیل داده (از قبیل هدوپ)، ذخیره سازی داده بر روی حافظه به جای دیسک می باشد. این ویژگی به برنامه های اسپارک اجازه می دهد که با سرعت بیشتری اجرا شوند، چرا که به مراجعه به دیسک برای خواندن اطلاعات، که باعث کند شدن پردازش می شود، نیاز ندارند. تصویر زیر فرآیند تجزیه یک لیست به چند بخش و توزیع هر یک را ببین چندین سیستم ، به خوبی نمایش می دهد. هر کدام از این بخش ها در حافظه یک Worker ذخیره می شوند.
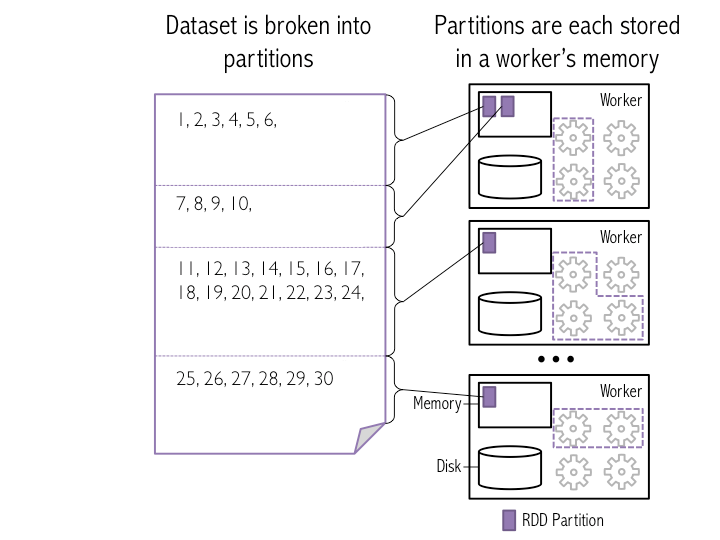
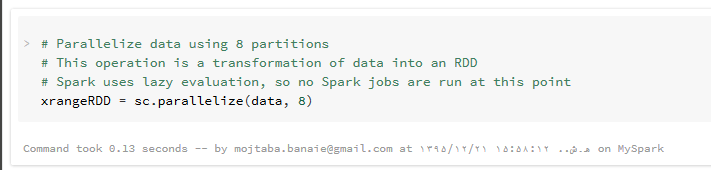
برای ایجاد RDD، ما باید از ()sc.parallelize، استفاده کنیم. این کد به اسپارک می گوید که یک مجموعه ی داده RDD از داده های ورودی ایجاد کند. در این مثال، ما از یک xrange به عنوان تولید کننده داده های ورودی استفاده می کنیم. دومین ورودی این تابع هم بیان می کند از چه تعداد پارتیشین برای شکستن داده ها در هنگام ذخیره آنها در حافظه استفاده شود (در بخش های بعدی این آموزش بیشتر در این باره بحث خواهیم کرد). توجه داشته باشید که برای عملکرد بهتر در هنگام استفاده از ()sc.parallelize، اگر ورودی شما از نوع بازه ای است حتماً از ()xrange استفاده کنید. ( دلیل این انتخاب در بخش قبل ذکر شد).
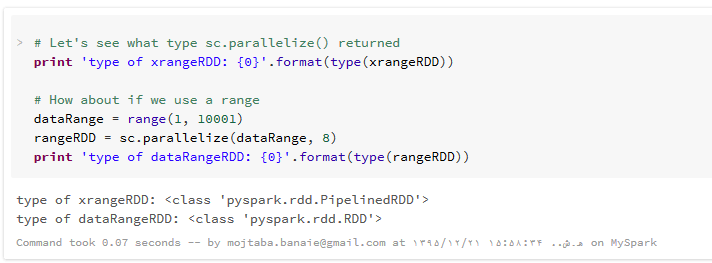
RDDها انواع مختلفی دارند. یک کلاس پایه برای همه ی RDD ها وجود دارد و سایر RDD ها زیرکلاس های این کلاس pyspark.RDD هستند. از آنجایی که انواع دیگر RDD از pyspark.RDD ارث بری دارند، بنابراین دارای API و عملکرد یکسانی هستند. با اجرای کدهای زیر، خواهید دید زمانی که ورودی از نوع Xrange باشد، تابع ()sc.parallelize نتیجه ای از نوع pyspark.rdd.PipelinedRDD را تولید کرده و زمانی که ورودی از نوع range باشد، pyspark.RDD را تولید خواهد کرد. (دستور type در پایتون نوع یک داده را به ما برمی گرداند.)
پس از تولید RDD ها، شما می توانید فهرست آنها را در سربرگ Storage در رابط کاربری تحت وب مشاهده کنید. البته مجموعه داده های جدید در این لیست وجود ندارد. دلیل آن هم این است که تا زمانی که اسپارک نیاز به برگرداندن نتیجه ی یک عملیات اجرایی نداشته باشد، مجموعه داده های جدید را تولید نخواهد کرد. این ویژگی اسپارک lazy evaluation یا ارزیابی با تاخیر خوانده می شود. این امر به اسپارک اجازه می دهد تا از انجام محاسبات غیرضروری جلوگیری کند.
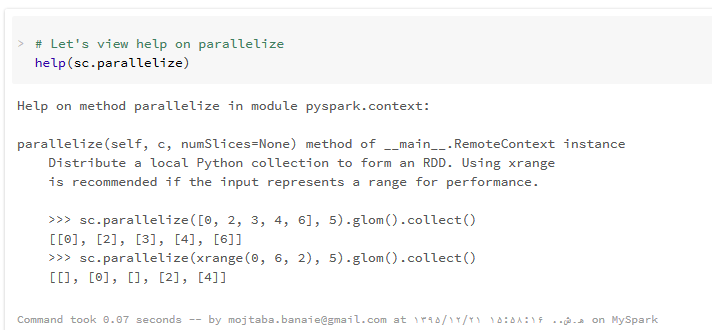
با کد فوق اولین RDD خود را با هشت پارتیشن از روی data که بالاتر آنرا ایجاد کرده ایم، می سازیم. اگر می خواهید جزییات بیشتری از تابع parallelize مشاهده کنید از دستور help به صورت زیر استفاده کنید :
برای مقایسه نوع مجموعه داده تولید شده با دستور range و دستور xrange ، یک RDD جدید با کمک تابع range ایجاد کرده و نوع آنرا با مجموعه داده قبلی مقایسه می کنیم . نتیجه را در زیر مشاهده می کنید :
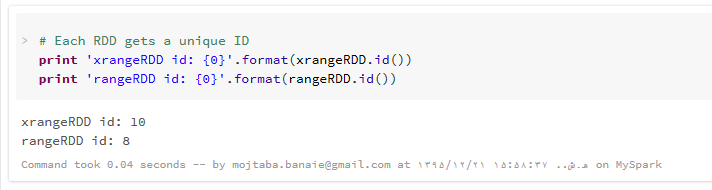
به هر مجموعه داده یک شناسه منحصر به فرد اختصاص می یابد که با تابع id روی آن مجموعه داده می توانیم به آن دسترسی داشته باشیم :
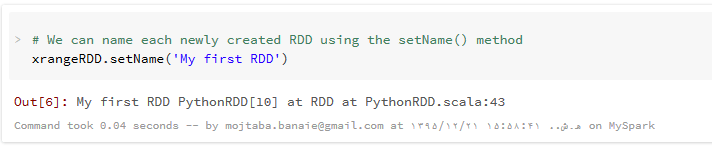
به مجموعه داده های خود که توسط اسپارک تولید می شود می توانید یک نام اختصاص دهید که مراجعه و رفع خطاهای آنها راحت تر صورت گیرد :
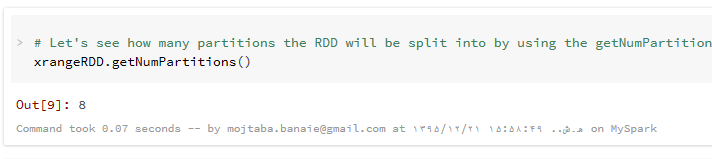
تعداد پارتیشن های اختصاص داده شده به یک مجموعه داده را هم به صورت زیر می توانید به دست آورید :
اکنون مجموعه داده های ما برای مرحله بعد که مرحله انجام چند پردازش روی آنهاست، آماده شده اند.
۳-۳ کاهش یک رقمی هر کدام از اعداد با استفاده از تبدیل نگاشت (map)
تا اینجا، ما یک مجموعه داده که درون چند پارتیشن مجزا، توزیع شده است را ایجاد کردیم، که هر پارتیشن روی یک ماشین جداگانه در شبکه ی ما قرار گرفته است. بیایید ببینیم زمانی که یک عملیات اصلی را روی یک مجموعه داده انجام می دهیم، چه اتفاقی خواهد افتاد. بسیاری از عملیات کاربردی در تجزیه و تحلیل داده به طور خاص، “انجام کاری روی هر آیتم در مجموعه داده” است. این نوع از عملیات برای مقاصد موازی سازی بسیار مناسب است چون می تواند به صورت جداگانه روی هر پارتیشن اجرا شود : عملیات روی هر ورودی بر روی سایر ورودی ها تاثیری ندارد بنابراین اسپارک می تواند عملیات را به صورت موازی اجرا کند.
رایج ترین تبدیل در اسپارک، تبدیل نگاشت یا (map(f می باشد که نمونه ای از این عملیات سراسری است: تابع f به هر آیتم در مجموعه داده اعمال می شود و خروجی آن هم یک مجموعه داده جدید (یک تبدیل) است. زمانی که شما map را روی یک مجموعه داده اجرا می کنید، یک گروه از وظایف به صورت خودکار شروع به اجرا می کند. یک stage یا گروه کاری به یک گروه از وظایف اطلاق می شود که یک عملیات مشترک را بر روی داده های متفاوت انجام می دهند. هر task یا وظیفه، یک واحد اجرایی ست که روی یک ماشین جداگانه اجرا می شود. زمانی که ما (map(f را درون یک پارتیشن اجرا می کنیم، یک task جدید عمل f را روی همه ی ورودی های آن پارتیشن اعمال می کند به گونه ای که خروجی ها یک پارتیشن جدید را تشکیل می دهند.
همانطور که در مثال زیر نشان داده شده است، برای هر پارتیشن یک task راه اندازی می شود و چون مجموعه داده اصلی ما به چهار پارتیشن شکسته شده است، بنابراین چهار task خواهیم داشت.
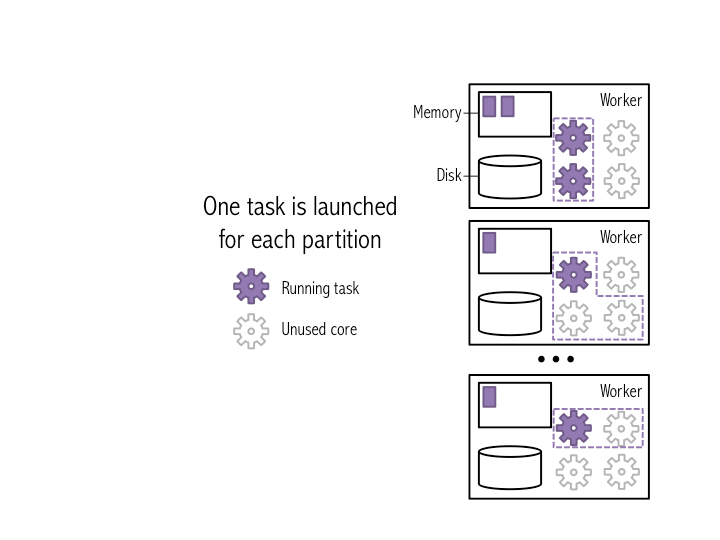
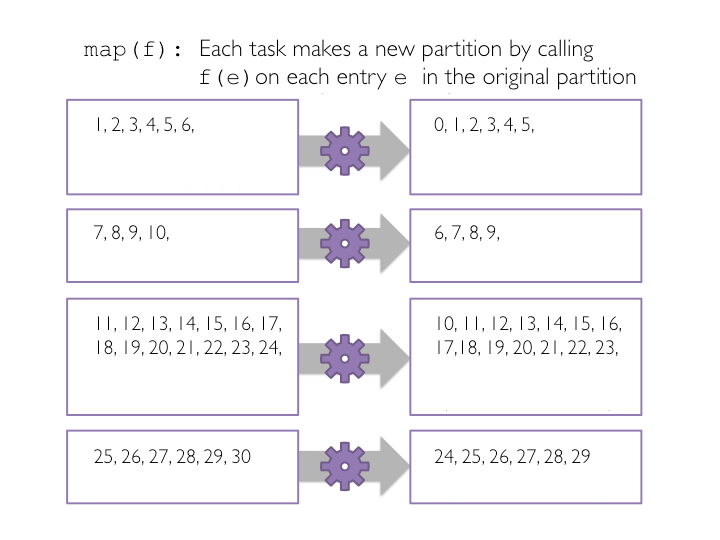
شکل زیر نشان می دهد که این عملیات چگونه بر روی یک مجموعه داده ( کوچکتر از مثال قبل) انجام می شود و همانطور که می بینید به ازای هر پارتیشن یک وظیفه ایجاد شده است.
زمانی که تبدیل ()map اعمال می شود، هر آیتم در RDD والد بر روی یک عنصر در RDD جدید نگاشت خواهد شد. بنابراین، اگر RDD والد، بیست عنصر داشته باشد، RDD جدید نیز بیست آیتم خواهد داشت.
حال از ()map برای تفریق یک واحد از هر ورودی در RDD پایه استفاده می کنیم. برای این منظور ابتدا، یک تابع پایتون با نام ()sub را تعریف می کنیم که عمل کسر یک واحد از عدد ورودی را انجام خواهد داد. سپس، هر آیتم در RDD پایه را با انجام تبدیل map() که تابع ()sub را برای هر عنصر اعمال می کند، به شکل جدید خود (مقدار قبلی منهای یک) تبدیل می کنیم. درآخر هم سلسله مراتب تبدیلات RDD را با استفاده از ()toDebugString نمایش می دهیم.
۴-۳ انجام عملیات جمع آوری (collect) برای مشاهده نتایج
برای مشاهده ی لیست عناصر جدید که اکنون در کل شبکه توزیع شده اند، می توانیم از تابع collect استفاده کنیم که تمام این عناصر را از تمام پارتیشن ها جمع آوری کرده و به صورت یک لیست جدید درون ماشین حاوی راه انداز یا درایور در اختیار ما قرار می دهد. ()Collect اغلب پس از اعمال یک فیلتر یا سایر عملیاتی که خروجی اندکی تولید می کنند، استفاده می شود. این کار به این دلیل انجام می شود که داده های بازگردانده شده به درایور باید درون حافظه اصلی درایور جا بشوند؛ در غیر اینصورت درایور از کار خواهد افتاد.
تابع ()collect اولین عملیات اجرایی (action) است که با آن مواجه شدیم. اکشن ها باعث شروع عملیات تبدیلی در اسپارک می شوند که برای محاسبه RDD جدید، مورد نیاز هستند. تا رسیدن به یک اکشن، هیچ تبدیلی توسط اسپارک انجام نمی شود و به همین دلیل به آنها تبدیلات با تاخیر (Lazy Transformation) می گوییم. در مثال ما، بدین معنی ست که برای اجرای اکشن collect، وظایفی توسط درایور، به منظور انجام عملیات موازی سازی(parallelize) و ساخت RDD پایه، نگاشت (map) و نهایتاً جمع آوری (collect) نتایج، بر روی هر پارتیشن شروع به کار خواهند کرد.
در این مثال، مجموعه داده ما به چهار پارتیشن تقسیم شده است، بنابراین چهار وظیفه (task) جمع آوری () collect اجرا خواهد شد. هر وظیفه، محتوای درون پارتیشن را جمع آوری کرده و نتایج را به درایور یا همان بستر اجرایی اسپارک، ارسال می کند که این امر یک لیست از مقادیر را مطابق شکل زیر ایجاد خواهد کرد.
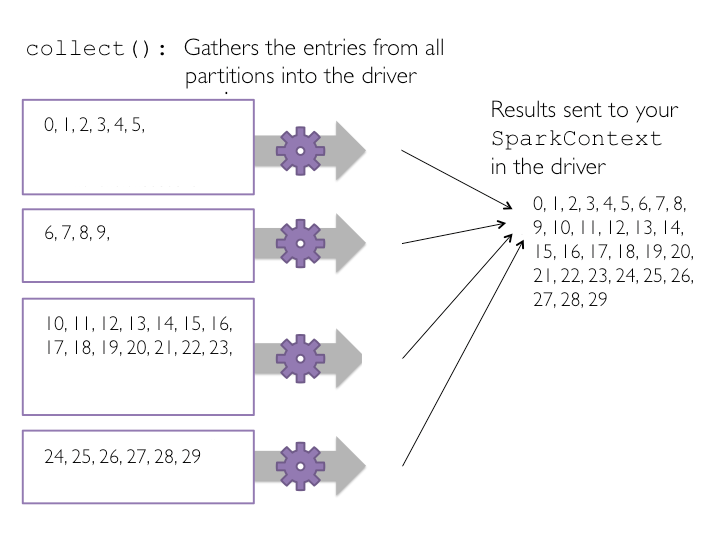
در تصویر بالا، چگونگی اجرای عمل ()collect بر روی یک مجموعه داده ی کوچک با چهار پارتیشن نمایش داده شده است.
حال بیابید برای تمرین بیشتر، عمل ()collect را روی یک RDD فرزند که اکنون با اجرای تابع نگاشت ایجاد کرده ایم، اجرا کنیم.
۵-۳ انجام عمل شمارش برای مشاهده تعداد عناصر یک لیست
یکی از عملیات دیگری که بر روی داده ها می توان اجرا کرد عمل ()count یا شمارش است که تعداد عناصر درون یک RDD را با استفاده از تابع ()count می شمارد. هنگامی که تابع ()map یک RDD جدید ایجاد می کند، انتظار می رود که اعمال تابع ()count در هر دو RDD مقدار یکسانی را بازگرداند که می توانیم صحت این موضوع را به راحتی آزمایش کنیم.
با اجرای count، به ازای هر پارتیشن یک وظیفه شروع به اجرا می کند که هر task تعداد عناصر درون یک پارتیشن را می شمارد و نتایج را به SparkContext ارسال می کند. این مقدار به سایر مقادیر شمارش شده اضافه می شود و نهایتاً نتیجه نهایی توسط بستر اجرایی اسپارک به ما برگردانده میشود. تصویر زیر چگونگی اجرای ()count را بر روی یک مجموعه داده ی کوچک شامل چهار پارتیشن نمایش می دهد.
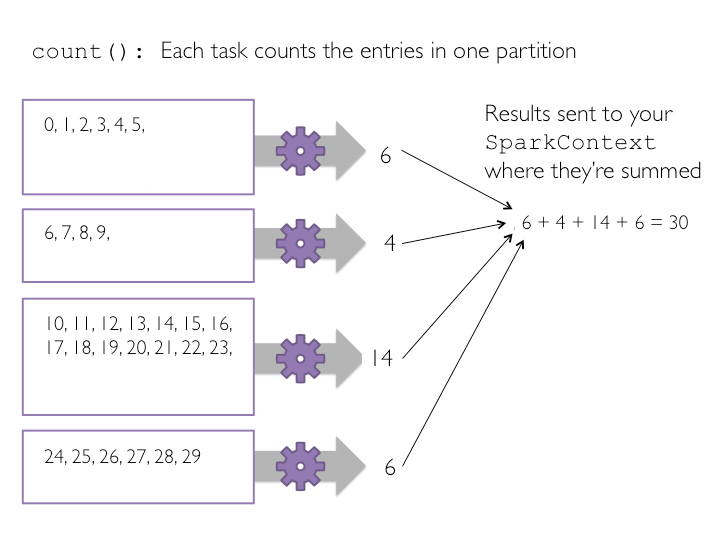
نتیجه اجرای تابع شمارش بر روی دو RDD قبلی هم در زیر نمایش داده شده است.
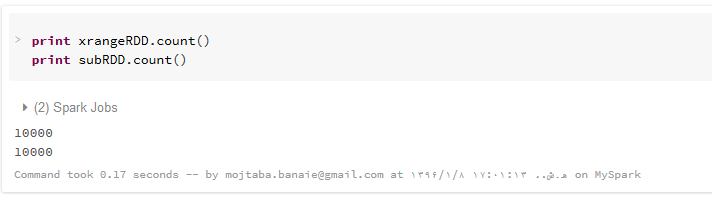
۳-۶ اعمال فیلتر تبدیل و مشاهده ی نتایج با استفاده از collect
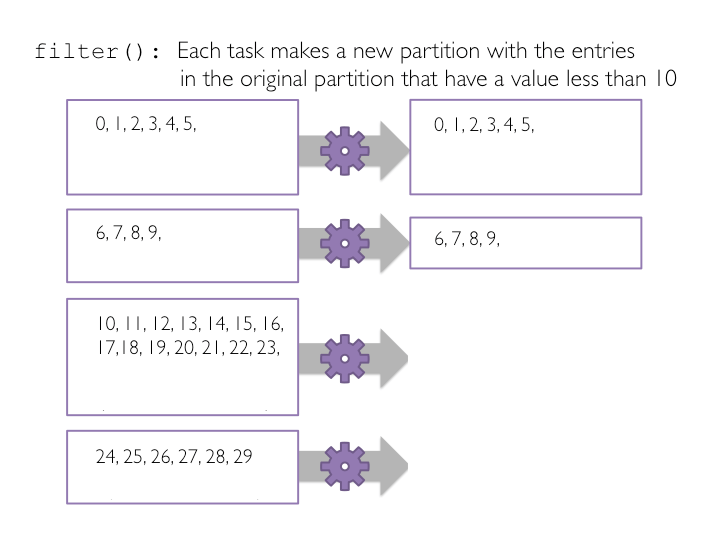
در این بخش ما یک RDD جدید که تنها حاوی مقادیر کمتر از ده است را با استفاده از تبدیل (filter(f، ایجاد خواهیم کرد. متد (filter(f، یک عملیات تبدیل است که یک RDD جدید را از روی RDD ورودی و براساس اعمال فیلتر f بر روی هر آیتم RDD والد ایجاد می کند و تنها شامل عناصری است که در تابع فیلتر، مقدار True را برگردانند. عناصری که مقدار true را برنگردانند حذف می شوند. مشابه عمل نگاشت، تابع فیلتر نیز بر روی هر ورودی در مجموعه داده اعمال می شود، بنابراین انجام عملیات موازی سازی آن توسط اسپارک ،به راحتی انجام خواهد شد.
تصویر زیر چگونگی انجام این کار را با استفاده از مجموعه داده ی حاوی چهار پارتیشن نمایش می دهد.
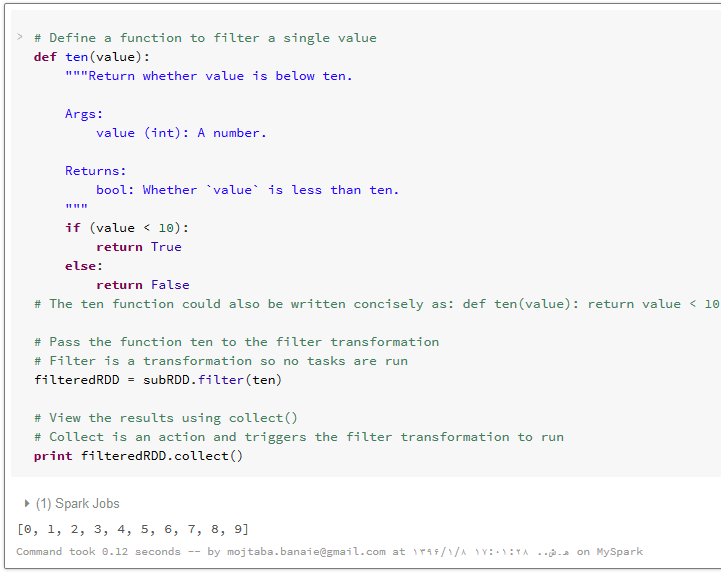
برای فیلتر کردن مجموعه داده، باید تابعی با نام ()ten را تعریف کنیم که اگر ورودی آن، کمتر از مقدار ۱۰ باشد، مقدار True را برگرداند. این تابع در تبدیل فیلتر به جای f قرار خواهد گرفت.
برای مشاهده ی لیست عناصر فیلتر شده ی کمتر از ۱۰، ما باید یک لیست جدید از داده های توزیع شده بر روی ماشین های اجراکننده در درایور ایجاد کنیم. برای برگرداندن لیستی که شامل همه ی عناصر RDD فیلتر شده روی درایور باشد، از تابع ()collect استفاده می کنیم. نتیجه اجرای این تابع را در زیر مشاهده می کنید :
۴- توابع لامبدا
پایتون توابع یک خطی کوچک و بدون نام را که به توابع لامبدا معروفند، را نیز پشتیبانی می کند. با اقتباس از LISP، این توابع لامبدا می توانند در هر جایی که تابع نیاز باشد، استفاده شوند. این توابع از لحاظ دستوری به یک عبارت محدود هستند. توجه داشته باشید که به هیچ وجه استفاده از این توابع الزامی نیست و تنها برای سادگی کار از آنها استفاده می کنیم. شما همیشه می توانید یک تابع را به صورت جداگانه تعریف کنید، اما استفاده از یک تابع لامبدا، فرم معادل و جمع و جورتری برای برنامه نویسی ارائه می دهد. در حالت ایده آل، در جایی که نیاز به استفاده مجدد از توابع کوتاه ندارید، بهتر است از توابع لامبدا استفاده کنید.
در اینجا، به جای تعریف یک تابع جداگانه برای تبدیل ()filter، ما از یک تابع درون خطی لامبدا استفاده خواهیم کرد. در قسمت اول، اعداد کمتر از ده را فیلتر می کنیم و در مرحله دوم هم در بین این اعداد، آنهایی که زوج هستند، فیلتر شده و در لیستی جدید قرار می گیرند.
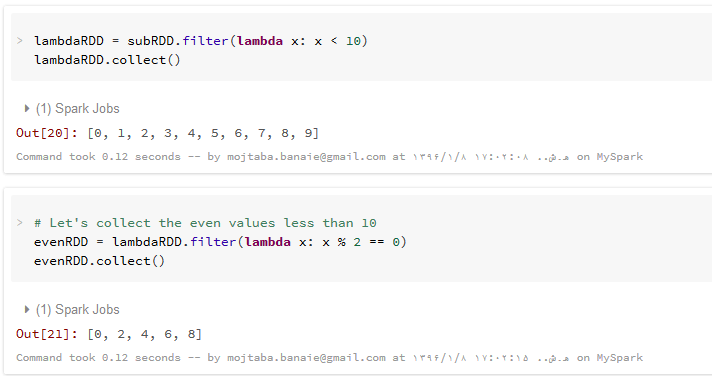
برای مشاهده مستندات توابع لامبدا در پایتون می توانید به این آدرس مراجعه کنید.
۵- سایر عملیات اجرایی RDD
۱-۵ عملیات اجرایی پرکاربرد (Common Actions)
بیایید علاوه بر اکشن جمع آوری نتایج و شمارش، به بررسی برخی از اکشن های پرکاربرد دیگر بپردازیم: ()first()، take()، takeOrdered و ()reduce.
هنگامی که ما یک مجموعه داده ی جدید داریم یکی از کارهای مفیدی که می توان انجام داد، نگاه کردن به چند ورودی نخست برای بدست آوردن یک ایده ی کلی از اطلاعات موجود در آن است. در اسپارک، ما می توانیم از عملیات first, take, top, takeOrdered استفاده کنیم. توجه داشته باشید که برای عملیات first و take، عناصری که بازگشت داده می شوند به تعداد پارتیشن های RDD وابسته اند.
به جای استفاده از عمل ()collect، ما می توانیم از عملیات take(n) برای برگرداندن n عنصر نخست RDD استفاده کنیم. عملیات ()first اولین عنصر یک RDD را بازمی گرداند و معادل با عملیات (take(1 می باشد.
عملیات takeOrdered()، n عنصر نخست RDD را با استفاده از ترتیب طبیعی یا یک روند مقایسه ی سفارشی بازمی گرداند. مزیت اصلی استفاده از ()takeOrdered به جای() first یا ()take، این است که ()takeOrdered یک نتیجه ی قطعی را بر می گرداند. درحالی که دو عمل دیگر ممکن است بسته به تعداد پارتیشن ها یا محیط اجرا نتایج متفاوتی را بازگردانند. ()takeOrdered یک لیست طبقه بندی شده به ترتیب صعودی را بازمی گرداند. عمل top() شبیه به ()takeOrdered است با این تفاوت که لیست را به ترتیب نزولی باز می گرداند.
عمل reduce() با اعمال تابعی که دو پارامتر گرفته و یک مقدار برمی گرداند، روی تمام عناصر RDD به صورت دو تا دو تا اعمال شده و هر دوتا ورودی را به یک ورودی تبدیل می کند و نهایتاً نتیجه آخر را برمیگرداند. شکل زیر فرآیند کاهش (reduce) را با اعمال عمل جمع روی دو عنصر، به خوبی نشان می دهد.
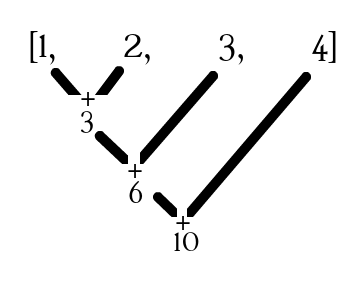
با توجه به اینکه عمل ()reduce در سطح پارتیشن اعمال می شود و سپس دوباره نتایج از پارتیشن ها جمع آوری می گردد و نتیجه هر پارتیشن هم مجددا با تابع داده شده ، کاهش می یابند تا به یک جواب نهایی در کل لیست برسیم، تابع باید قابل جابجایی و انجمنی داشته باشد تا بتوان با هر ترتیبی، جواب هر پارتیشن را با هر پارتیشن دلخواه دیگر، به تابع کاهش داد و خروجی مورد نیاز را تولید کرد. در غیر اینصورت نتایج حاصل از ()reduce باعث ایجاد ناسازگاری خواهند شد. در زیر با انجام مثالهایی هم با کاربرد این توابع آشنا می شوید و هم ناسازگاری حاصل از انتخاب اشتباه تابع کاهش را از نزدیک مشاهده خواهید کرد. از آنجا که بیشتر فرآیند کاهش، به صورت محلی در یک پارتیشن انجام می گردد، این عمل به صورت بسیار موثر و بهینه ای اجرا می گردد و نگران ترافیک شبکه و ادغام نهایی پارتیشن ها نباشید.
ابتدا با تابع first اولین عنصر از filteredRDD را گرفته و نمایش می دهیم. در مثال دوم با تابع take تعداد مشخصی از عناصر لیست را بر می گردانیم . در مثال سوم، تعداد ارسال شده به تابع take را بیشتر از تعداد عناصر آن در نظر می گیریم که باز هم خطایی پیش نمی آید و تمام عناصر برگشت داده می شود. خروجی ها هم در پایین نمایش داده شده است :

در مرحله بعد، با تابع takeordered که عناصر لیست را به صورت صعودی مرتب می کند، سه عنصر کوچکتر و سپس با تابع top که عناصر انتهای لیست مرتب شده را بر می گرداند، پنج عنصر بزرگتر را به دست می آوریم:
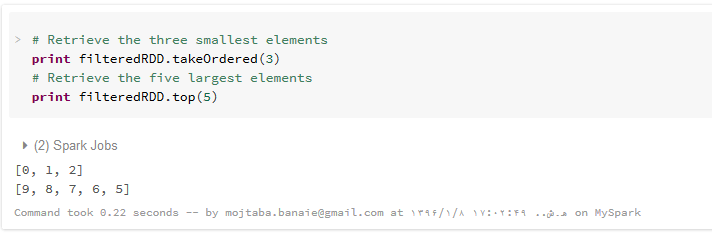
می توانیم ترتیب مرتب کردن عناصر را با یک تابع لامبدا (یا ذکر نام یک تابع معمولی ) به نحو دلخواه تعیین کنیم. به این صورت که تابعی را می نویسیم با یک ورودی که نمایانگر عناصر لیست است و سپس معیار مرتب سازی را بر روی آن ورودی اعمال می کنیم که این معیار می تواند طول یک رشته، تعداد ارقام و مانند آن باشد. به این ترتیب ، اسپارک ابتدا این تابع را بر روی همه عناصر لیست اعمال کرده ، بر اساس نتیجه آن ، عناصر را مرتب می کند و نهایتا تعداد مورد نیاز ما را بر می گرداند. در این مثال، ما از منفی کردن اعداد در تابع لامبدا کمک گرفته ایم که باعث می شود ترتیب عادی اعداد، عکس شود :
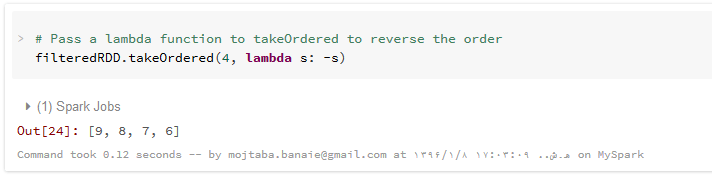
در مثال آخر این بخش، تابع کاهش یا reduce را به صورت عملی به کار برده ایم. ابتدا تابع add استاندارد پایتون را برای محاسبه مجموع تمام عناصر لیست به کار برده ایم. سپس همین کار را با یک تابع لامبدا که به صورت درون خطی تعریف کرده ایم، انجام می دهیم. نتیجه هر دو حالت عدد ۴۵ است . در مرحله بعد تابع تفریق را برای کاهش می کنیم که نتیجه ۴۵- شده است اما تفریق جابجایی و اشتراک پذیری ندارد بنابراین نتیجه عملیات کاهش با استفاده از تفریق، بسته به ترتیب اجرا روی پارتیشن ها متفاوت خواهد بود. برای امتحان این موضوع،با تابع repartition تعداد پارتیشن های filteredRDD را به ۴می رسانیم و تابع تفریق را روی این چهار تا پارتیشن استفاده می کنیم . نتیجه عدد ۲۱ شده است که متفاوت با نتیجه تفریق قبلی است و این یک نوع ناسازگاری است. اما اگر همین کار را برای تابع جمع انجام دهیم ، نتیجه نهایی هیچ فرقی با جمع قبلی نمی کند :
۲-۵ عملیات پیشرفته
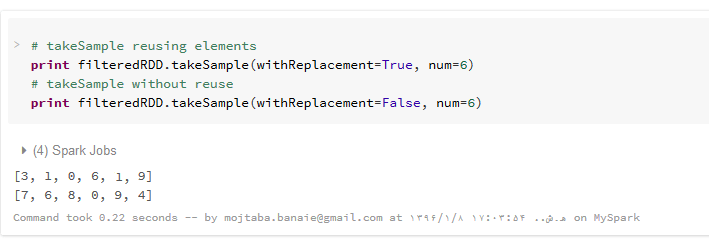
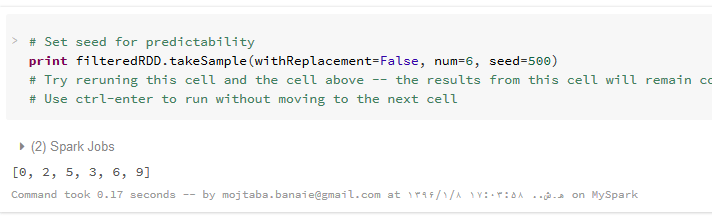
دو عملیات پیشرفته دیگر نیز وجود دارد که در کار با RDD ها مفید هستند: () takeSample و ()countByValue.
عمل ()takeSample، یک آرایه با مقادیر تصادفی از عناصر یک مجموعه داده (RDD) را بر می گرداند. این عمل، پارامتری با نام withReplacement دارد که در صورتی که مقدار True به آن نسبت داده شود، ممکن است یک داده خاص، چندین بار در خروجی ظاهر شود اما اگر مقدار آن برابر False باشد، یک مقدار خاص (منظور یک اندیس خاص در مجموعه داده است نه یک مقدار مشخص چون ممکن است خود مجموعه داده، مقادیر تکراری داشته باشد)، حداکثر یک بار در خروجی ظاهر خواهد شد. علاوه بر این، پارامتری با نام num داریم که تعداد عناصر برگشتی را مشخص می کند. این عمل یک پارامتر اختیاری نیز دارد که به شما اجازه می دهد تا یک مقدار اولیه (seed) برای تولید اعداد تصادفی تعیین کنید. بنابراین نتایجی با قابلیت تولید مجدد بدست می آید. از Seed برای مقداردهی اولیه به مولد اعداد تصادفی استفاده می شود. بنابراین با استفاده از یک مقدار seed مشخص و تعداد num مشخص، می توانیم دقیقاً یک مجموعه عدد را مجدداً تولید کنیم. (به عبارتی مقدار seed مانند یک شناسه برای تولید این اعداد تصادفی عمل می کند.) اطلاعات بیشتر درباره seed را می توانید در اینجا مشاهده نمایید.
عمل ()countByValue، تعداد هر عنصر را در RDD می شمارد و در یک دیکشنری هر عنصر را به تعداد تکرار آن در RDD نگاشت می کند. در زیر نحوه فراخوانی این دو عمل اجرایی، به همراه پارامترهای مختلف و نتایج آنها نشان داده شده است :

۶- سایر تبدیلات پرکاربرد RDD
۱-۶ flatMap
زمانی که ما تبدیل ()map را روی یک مجموعه داده اعمال می کنیم، به ازای هر عنصر لیست، یک خروجی تولید می شود که این خروجی ممکن است خود یک لیست یا یک تاپل یا یک آرایه باشد. اگر فقط مقادیر خروجی برای ما مهم باشد، باید تبدیلاتی را روی این خروجی ها اعمال کنیم و آنها را به یک لیست مسطح که فقط حاوی مجموعه مقادیر باشد تبدیل کنیم. در این جور مواقع، می توانیم به جای تابع نگاشت معمولی از نگاشت مسطح یا flatMap استفاده کنیم که تمام خروجی های تولید شده را در یک لیست نهایی قرار می دهد که غیر از خود عناصر، شامل هیچ لیست، تاپل، دیکشنری یا هر ساختمان داده دیگری نیست و داده ها همه هم سطح هستند.
مثالهای زیر را با دقت نگاه کنید تا دقیقاً مکانیزم تابع پرکاربرد flatMap را متوجه شوید :

در مثال فوق لیستی از کلمات را ایجاد و از روی آن، یک RDD پایه با نام wordsRDD ساخته ایم. سپس با کمک یک تابع لامبدا ، عملیات نگاشت را به گونه ای انجام می دهیم که هر عنصر به یک تاپل دوتایی تبدیل شود شامل خود کلمه و جمع آن . (تاپل، لیستی فقط خواندنی در پایتون است که درون یک پرانتز قرار میگیرد) . بنابراین خروجی تابع نگاشت، لیستی از این تاپل ها خواهد بود به تعداد ۵ عنصر (۵ تاپل دوتایی دقیقا هم اندازه RDD پایه) که در شکل فوق هم کاملا مشهود است.
همین کار را که با تابع نگاشت مسطح (flatMap) انجام می دهیم، یک لیست حاوی ده کلمه تولید می شود و در آن خبری از تاپل و غیره نیست.
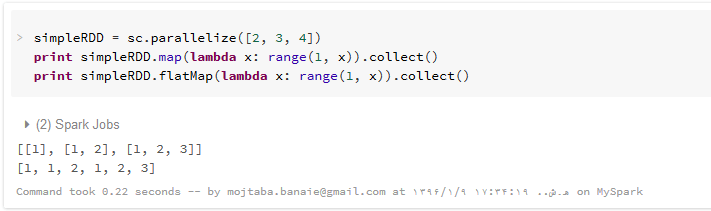
در این مثال هم، به کمک تابع نگاشت، به ازای هر عنصر ، یک لیست از یک تا آن عنصر را تولید می کنیم. بنابراین خروجی نهایی تابع نگاشت، لیستی از لیستها خواهد بود. اما اگر این کار را با تابع نگاشت مسطح یا همان flatMap انجام دهیم، خروجی نهایی یک لیست حاوی فقط اعداد لیست های تولید شده خواهد بود.
2-6 ()groupByKey و ()reduceByKey
در این بخش به بررسی دو تبدیل مهم دیگر می پردازیم: ()groupByKey و ()reduceByKey
هر دو تبدیل بر روی RDD های دوتایی عمل می کنند. یک RDD دوتایی، مجموعه داده ایست که در آن، هر عنصر به شکل دوتایی (key,value) یا همان کلید/ مقدار می باشد. در پایتون، هر عنصر یک RDD دوتایی، یک تاپل دوتایی است که اولین عنصر تاپل ، برابر کلید و عنصر دوم تاپل، مقدار متناظر با آن کلید یا همان مقدار است.
برای مثال، تابع ([(sc.parallelize([(‘a’, 1), (‘a’, 2), (‘b’, 1 ، یک RDD دوتایی با کلید های a،b و c و مقادیر ۱ ،۲ و ۱ ایجاد می کند.
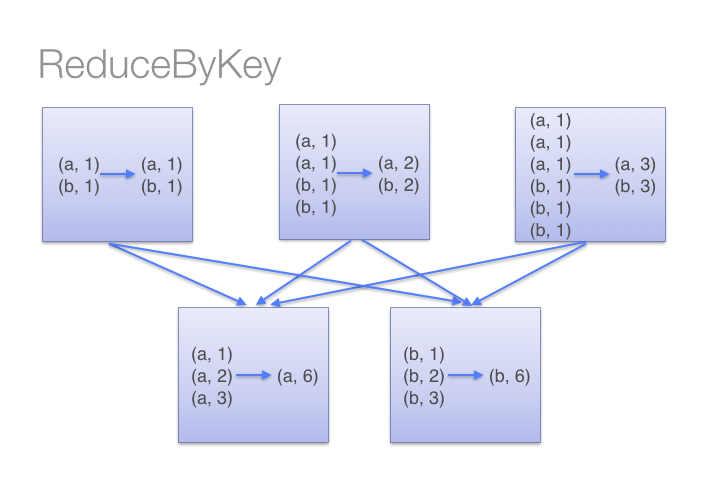
تبدیل ()reduceByKey، جفت هایی که دارای key کلید یکسان هستند را در یک گروه قرار داده وسپس تابع کاهش را روی مقادیر مربوط به هر گروه اعمال می کند. ()reduceByKey ابتدا درون هر پارتیشن بر روی کلیدهای یکسان اعمال شده و سپس بر روی تمام پارتیشن ها اعمال می شود.
هر دو تبدیل ()groupByKey و ()reduceByKey خروجی یکسانی تولید می کنند و هر دو برای اعمال یک تابع بر روی مقادیر دوتایی موجود در کل پارتیشن ها و جمع آوری نتیجه نهایی و نمایش آن به کاربر، استفاده می شوند اما از لحاظ کارآیی و نحوه عملکرد داخلی، تفاوتهایی با هم دارند به گونه ای که عملیات ()reduceByKey در مورد مجموعه داده های توزیع شده ی در مقیاس بزرگ، بهتر عمل می کند. در هر دو روش، گروه بندی داده ها بر اساس کلیدها در هر پارتیشن انجام می گیرد اما در عملیات reduceByKey، روند کاهش و اعمال تابع در همان ماشین اجرا کننده، انجام میشود تا جایی که از هر کلید تنها یک تاپل باقی بماند اما در عملیات groupByKey، بعد از گروه بندی داده ها بر اساس کلیدها، داده ها به صورت گروه بندی شده بین سایر ماشین ها توزیع میشوند (عملیات shuffle یا توزیع مجدد) و در این مرحله است که تابع کاهش، اعمال میشود. بنابراین سربار ترافیک شبکه در روش groupByKey بسیار بیشتر از روش reduceByKey خواهد بود و استفاده از آن چندان توصیه نمی شود مگر اینکه واقعا نیاز داشته باشید تمام داده های با کلید یکسان در یک ماشین جمع شده و سپس تابع کاهش بر روی آنها اعمال شود.
برای درک چگونگی عملکرد reduceByKey و groupByKey به دو تصویر زیر نگاه کنید. البته مرحله آخر که جمع آوری نتایج از تمام ماشین ها و ارائه آن به کاربر است در شکل نمایش داده نشده است.
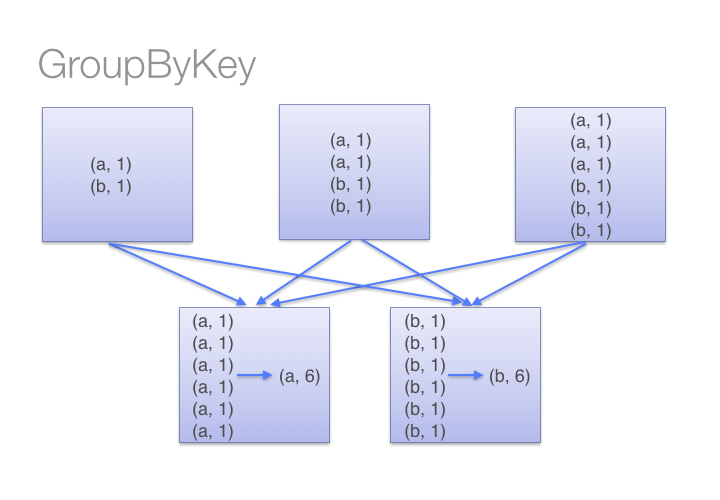
برای تعیین نحوه توزیع دوتایی ها بر روی ماشین ها و اینکه کدام ماشین، داده های با کلید a را جواب دهد و کدام ماشین داده های با کلید b را جواب دهد و … ، اسپارک یک تابع تقسیم بندی را بر روی هر کلید فراخوانی می کند و نتیجه این تابع، ماشینی که باید تمام گره های با کلید مشخص به آن ارسال شوند، را تعیین می کند.
زمانی که داده های ارسال شده به یک ماشین، بیشتر از ظرفیت حافظه آن ماشین باشد، اسپارک داده ها را درون دیسک می ریزد. به دلیل اینکه داده های کلید در یک لحظه به دیسک منتقل شده اند، اگر مقادیر جفت کلید برای یک کلید مشخص، بیشتر از ظرفیت حافظه بوده باشد، یک خطای خروج از حافظه (out of memory exception) رخ خواهد داد. البته این مورد در نسخه های بعدی اسپارک، تصحیح خواهد شد به طوری که با کم آمدن حافظه، برنامه ها متوقف نشود اما باید از این عمل اجتناب کرد چون مراجعه به دیسک برای انجام هر عمل کاهش، نقطه قوت اصلی اسپارک که استفاده از حافظه به جای دیسک است را کاملاً مورد تاثیر قرار خواهد داد. بنابراین منطقی تر این است که تا حد امکان از reduceByKey به جای groupByKey استفاده کنید که به مشکل حافظه برخورد نکنید.
دو تبدیل زیر نسبت به ()groupByKey برتری دارند و در صورت نیاز، بهتر است از آنها استفاده کنیم :
()combineByKey : این عمل می تواند برای ترکیب عناصر استفاده شود. اما نوع خروجی با نوع مقادیر ورودی متفاوت خواهد بود.
()foldByKey : مقادیر هر کلید را با استفاده از یک تابع انجمنی و یک عضو خنثی (zero value) ادغام می کند.
به مثال های ساده ای از ()groupByKey و ()reduceByKey دقت کنید :
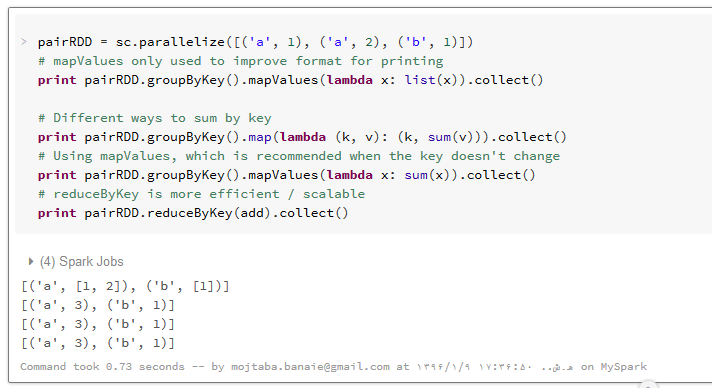
در مثال فوق، تابع mapValues برای دسترسی به تمام مقادیر با کلید یکسان به کار می رود و تابع لامبدا که ورودی این تابع است در حقیقت روی این مقادیر اعمال میشود. در اولین استفاده از این تابع، مقادیر متناظر با هر کلید را به یک لیست تبدیل کرده و نمایش داده ایم و در دومین استفاده هم جمع آنها را با تابع sum محاسبه کرده ایم.
با استفاده از تابع groupByKey به دو روش مختلف، مقادیر متناظر با بک کلید را با هم جمع کرده ایم و در آخر هم به صورت بهینه و اصولی، این کار را با تابع reduceByKey انجام داده ایم. ورودی این عملیات هم نام تابعی است که باید روی تک تک مقادیر هر کلید انجام شود. در اینجا نام تابع add که بالاتر آنرا import کرده ایم، وارد شده است.
۳-۶ تبدیل های پیشرفته [اختیاری]
در این بخش به بررسی دو تبدیل پیشرفته خواهیم پرداخت: ()mapPartitions و ()mapPartitionsWithIndex.
تبدیل ()mapPartitions برای اعمال یک تابع روی مقادیر هر پارتیشن از یک RDD به کار می رود و خروجی آن لیستی است شامل نتایج هر پارتیشن . ورودی این تابع یک iterator است (یعنی یک لیست یا مشابه با آن که با حلقه for می توان عناصر آنرا پیمایش کرد).
تبدیل ()mapPartitionsWithIndex، مشابه تابع فوق است با این تفاوت که اندیس یا شماره هر پارتیشن را هم در تابع نگاشت مختص هر پارتیشن، داریم و می توانیم از این شماره هم استفاده کنیم.
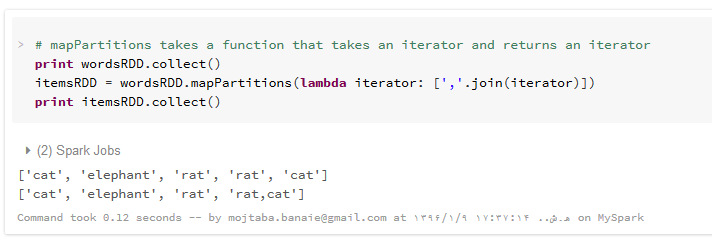
اگر بخاطر داشته باشید، هنگام نشان دادن نحوه استفاده از flatMap یک لیست از لغات را با نام words به یک RDD پایه به نام WordsRDD با چهار پارتیشن تبدیل کردیم. در مثال فوق، به کمک تابع لامبدا، عناصر هر پارتیشن را با کاما به هم می چسبانیم و چون دو لغت انتهایی rat و cat در یک پارتیشن قرار گرفته بودند، RDD جدید شامل لیستی چهار تایی (به تعداد پارتیشن ها) خواهد بود که عنصر انتهایی آن، ترکیب دو کلمه ایست که در یک پارتیشن قرار گرفته اند.

در این مثال هم ، به کمک یک تابع لامبدا، اندیس و عناصر یک پارتیشن را گرفته، یک تاپل شامل اندیس و لیست عناصر آن پارتیشن بر می گردانیم که در لیست نهایی این چهار تاپل کنار هم قرار می گیرند. به عبارت دیگر با این کار، توانسته ایم مشخص کنیم که در هر پارتیشن چه کلماتی قرار گرفته اند. در مثال اول، تابع لامبدا یک لیست از تاپل ها را تولید کرده است و در مثال دوم، بدون ایجاد یک لیست، یک تاپل شامل اندیس و لیست کلمات آن، ایجاد شده است .
۷- ذخیره یک RDD و گزینه های ذخیره سازی
۱-۷ ذخیره موقت RDD ها – Caching
برای افزایش بهره وری، اسپارک RDD ها را درون حافظه نگهداری می کند. با این کار، اسپارک می تواند به سرعت به داده ها دسترسی داشته باشد. با این حال، حافظه محدود است، بنابراین اگر RDDهای زیادی در برنامه خود ایجاد کرده باشید، اسپارک به صورت خودکار RDD های قدیمی را برای ایجاد فضا برای RDDهای جدید حذف می کند اما نگران نباشید ؛ اگر شما بعدا به یکی از این RDD های حذف شده مراجعه کنید، اسپارک به صورت خودکار، آنرا برای شما از روی RDD پایه به کمک تبدیل هایی که باید روی آن صورت گیرد،ایجاد می کند اما این عمل مدتی طول خواهد کشید.
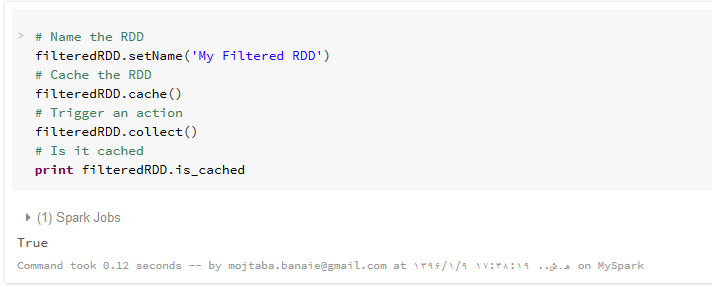
منطقی است اگر شما بیش از یک بار قصد استفاده از یک RDD را دارید، باید به اسپارک اعلام کنید تا آنرا برای شما ذخیره کند.شما می توانید از عمل ()cache برای نگهداری RDD در حافظه استفاده کنید. با این حال، در ذهن داشته باشید که یک RDD زمانی در حافظه ذخیره می شود که ابتدا ایجاد شده باشد و ایجاد یک RDD در حافظه هم منوط به این است که یک عملیات اجرایی مانند collect را بر روی آن اجرا کنید. به خاطر داشته باشید که اگر شما بیش از حد از cache جهت ذخیره سازی RDD ها استفاده کنید، اسپارک با کمبود حافظه مواجه شده و به صورت خودکار، قدیمترین RDD ،را حذف خواهد کرد و همانطور که قبلاً گفته شد، در صورت نیاز، مجدداً قابل تولید است.
شما می توانید ذخیره سازی یک RDD در حافظه را با استفاده از ویژگی is_cached، بررسی کنید. RDD های ذخیره شده در بخش storage در رابط کاربری تحت وب اسپارک قابل مشاهده هستند. کافیست بر روی نام RDD کلیک کنید تا قادر به مشاهده ی اطلاعات مربوط به موقعیت RDD باشید.
۲-۷ پاکسازی حافظه و گزینه های ذخیره سازی
اسپارک به طور خودکار RDD های ذخیره شده در حافظه را مدیریت کرده و در صورت پرشدن حافظه، آنها را درون دیسک ذخیره خواهد کرد. برای کارایی بهتر، زمانی که کارتان با یک RDD به پایان می رسد، می توانید با استفاده از متد() unpersist، به اسپارک اعلام کنید که کار شما با RDD تمام شده و ذخیره سازی در حافظه را متوقف کند.
شما می توانید مجموعه ی تبدیل های اعمال شده بر روی یک RDD را با استفاده از متد ()toDebugString مشاهده کنید، که شامل اطلاعات ذخیره سازی نیز می باشد. از طرفی، به صورت مستقیم نیز می توانید اطلاعات فعلی مکان ذخیره سازی یک RDD را با استفاده از تابع ()getStorageLevel مشاهده و بررسی نمایید.
توصیه: اسپارک گزینه های زیادی را جهت مدیریت نحوه ی ذخیره سازی RDD ها در حافظه و یا حتی روی دیسک ارائه نموده است. شما می توانید با استفاده از تابع help یا مراجعه به مستندات، گزینه های مختلف اکشن ()persist را مشاهده نمایید. برای اطلاعات بیشتر درباره ی StorageLevel به اینجا مراجعه کنید.
۸ – بررسی ارزیابی با تاخیر و چالش های اشکال زدایی حاصل از آن
نحوه ی اجرای برنامه های پایتون در اسپارک
اسپارک با استفاده از ماشین مجازی جاوا (JVM) اجرا می شود. pySpark کد پایتون را با استفاده از Py4J بر روی ماشین مجازی جاوا اجرا می کند. Py4J برنامه های پایتون را قادر می سازد تا به کلاس های جاوا در ماشین مجازی جاوا دسترسی داشته باشند. به این ترتیب، تمامی متدها و امکانات جاوا در اختیار برنامه های پایتون قرار می گیرد و همچنین Py4J برنامه های جاوا را قادر می سازد تا از کتابخانه های پایتون، استفاده نمایند.
به دلیل استفاده ی pySpark از Py4J، خطاهای کدنویسی اغلب پیچیده هستند، و ردیابی پشته اجرایی برنامه هنگام بروز خطا، می تواند بسیار سخت و نامفهوم باشد. در بخش زیر، ما به بررسی نحوه ی ردیابی پشته اجرایی برنامه و نحوه تفسیر خطاها می پردازیم.
۱-۸ چالش های پیش روی lazy evaluation در استفاده از تبدیل ها و عملیات اجرایی
استفاده از lرزیابی با تاخیر، می تواند اشکال زدایی برنامه را سخت کند، به این دلیل که کدها همیشه در همان لحظه اجرای دستورات، اجرا نمی شوند. برای مشاهده ی نمونه ای از چگونگی این اتفاق، اجازه دهید ابتدا یک تابع فیلتر را به گونه ای تعریف کنیم که حاوی یک خطا باشد و به این تابع، نام فیلتر شکسته (broken filter) را اختصاص می دهیم. در این مرحله هیچ خطایی در استفاده از lazy evaluation (ارزیابی با تاخیر) در اسپارک، رخ نخواهد داد.
متد ()filter تا زمانی که یک عملیات (action) روی RDD اجرا نشود، اعمال نخواهد شد بنابراین از اکشن ()collect برای برگرداندن یک لیست حاوی همه ی عناصر فیلتر شده در RDD استفاده می کنیم تا محیط اجرایی اسپارک را مجبور کنیم که تبدیلات مورد نیاز (اعمال فیلتر) را انجام دهد.
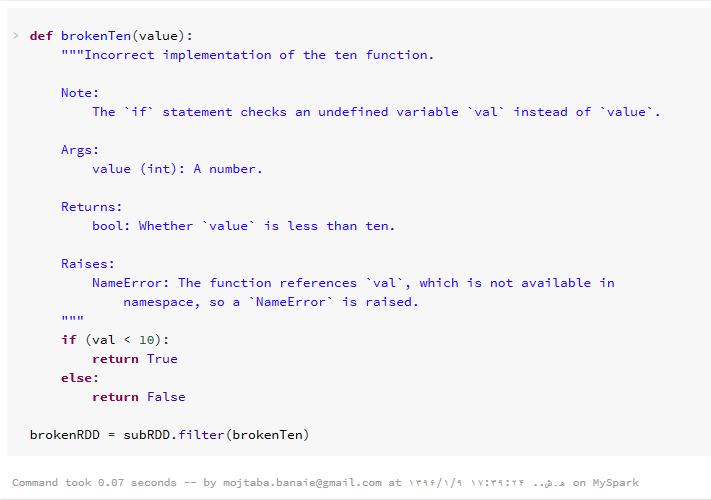
در مثال فوق، نام پارامتر ورودی تابع، value است اما در داخل تابع ما از نام val استفاده کرده ایم که باعث خطا در هنگام اجرای فیلتر خواهد شد اما خطای نمایش داده شده، گویای این استفاده نابجا از یک متغیر تعریف نشده، نیست.
۲-۸ یافتن خطا
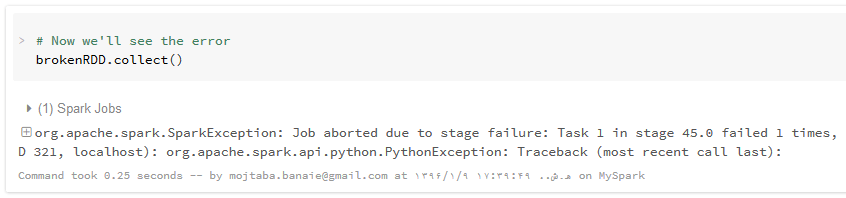
زمانی که متد() filter اجرا می شود، اسپارک RDD جدید را با استفاده از اجرای متدهای ()parallelize و ()filter تولید می کند. از آنجا که متد ()filter با اجرای تابع ()brokenTen که دارای خطاست، قصد فیلتر کردن داده ها را دارد،یک خطا رخ می دهد.
علامت + کنار خروجی را بزنید تا پشته اجرایی برنامه در هنگام خطا برایتان باز شود. عنوان ذکر شده برای خطا “(Py4JJavaError Traceback (most recent call last”است. خطی که خطا را تولید کرده است، مربوط به خط حاوی فراخوانی متد ()collect می باشد. هیچ اشتباهی در این خط وجود ندارد اما این اکشن collect بوده است که باعث اجرای تبدیلات گذشته و نهایتاً رخداد خطا شده است بنابراین به حرکت بین خطوط ارزیابی خطا را ادامه می دهیم تا به بخش خطاهای Py4JJavaError برسیم . در این بخش، این خطا را مشاهده خواهیم کرد:
این خطا کاملاً گویاست و می شود فهمید که استفاده نابجا از نام متغیر در تابع فیلتر ()brokenTen، باعث رخدا آن شده است.
۳-۸ حرکت به سمت حرفه ای شدن
همانطور که به آموزش اسپارک مشغول هستید، ما توصیه می کنیم که کدهای خود را به این فرم بنویسید:
استفاده از این سبک، اشکال زدایی کد را آسان می کند. همچنین مکان یابی خطاهایی که در زمان اجرای عمل بعدی در تبدیل های شما رخ می دهد را ساده تر خواهد کرد. همچنین برای خوانایی بیشتر و مختصر سازی کدها از توابع لامبدا به جای تعریف مجزای توابع استفاده می کنیم.
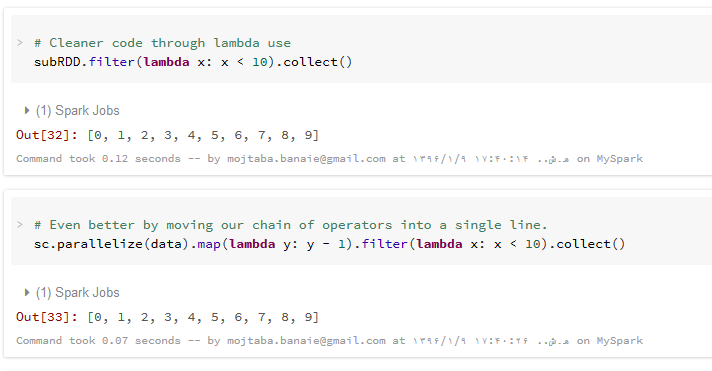
کمی که حرفه ای تر شدید، از این سبک برای کدنویسی استفاده کنید:
به مثالهای زیر که معمولاً در نمونه کدهای حرفه ای مشاهده می کنید، توجه کنید :
۴-۸ شیوه ی کدنویسی و خوانایی
برای خوانایی بیشتر و کدنویسی حرفه ای تر، جملات را درون پرانتز قرار داده و هر متد، تبدیل یا اکشن را در خطوط جداگانه قرار دهید.