
بررسی معیارهای سنجش دستهبندی – بخش دوم
در مقاله قبلی به تشریح ماتریس پراکنش ( Confusion Matrix ) و نیز بررسی دو معیار مهم در سنجش کارآیی مدلهای دستهبندی یعنی معیار صحت ( Precision ) و بازخوانی ( Recall ) و نهایتا معیار ترکیبی F1-Score که میانگین هارمونیک این دو معیار است، پرداختیم و بیان شد که هدف اصلی ما در یافتن یک مدل دستهبندی افزایش F1-Score آن خواهد بود. در ادامه مسیر، به نمودار دیگری میپردازیم که میزان جداکنندگی یک مدل یا دقت آن در تمییز دادن بین دو دسته را به ما نشان میدهد و در علم داده به نمودار ROC شناخته میشود.
فرض کنید قرار است مدلی بسازیم که تعییین کند یک شخص خاص، فلان بیماری را دارد یا نه. یعنی اگر مدل ما، یک شخص را مثبت ارزیابی کرد، یعنی آن شخص به احتمال زیاد دارای آن بیماری خواهد بود.از طرفی فرض کنید که این بیماری فراگیر شده است و حدود نصف مردم یک منطقه را درگیر نموده است.
مدلی که برای تشخیص بیماری با توجه به نشانهها و آزمایشات بالینی خواهیم ساخت، به هر فرد احتمالی بین ۰ تا ۱ اختصاص میدهد که با توجه به آن، بیمار بودن یا سالم بودن شخص را حدس خواهیم زد. اگر نمودار توزیع این احتمال را بر اساس درصد احتمال ما به عضویت در گروه بیماران یا افراد سالم رسم کنیم به نمودار ساده زیر می رسیم که در آن نمودار سبزرنگ، احتمال بیمار بودن و نمودار قرمز رنگ، احتمال سالم بودن یک شخص را نشان میدهد.

همانطور که مشخص است اگر خروجی مدل ما زیر عدد ۰.۴ باشد، شخص مورد نظر قطعا سالم است و اگر عدد خروجی مدل ما بالای ۰.۶ باشد، نشان دهنده بیمار بودن شخص است اما اگر عددی بین این دو تولید شد، مثلاً عدد ۰٫۵ ، با قطعیت نمیتوانیم بیان کنیم که شخص بررسی شده، سالم است یا نه. اگر بین ۰٫۴ تا ۰٫۵ باشد، احتمال سالم بودن شخص بیشتر است و اگر بین ۰٫۵ تا ۰٫۶ باشد، احتمال بیمار بودن شخص ،قوت میگیرد که این امر، باعث میشود دقت مدل کمی پایین بیاید و ناخواسته، نتایج اشتباهی حاصل شود.
در هر صورت، ما نیاز داریم نقطه برشی را تعیین کنیم که از آنجا به بالا را بیمار و از آنجا به پایین را سالم فرض کنیم.
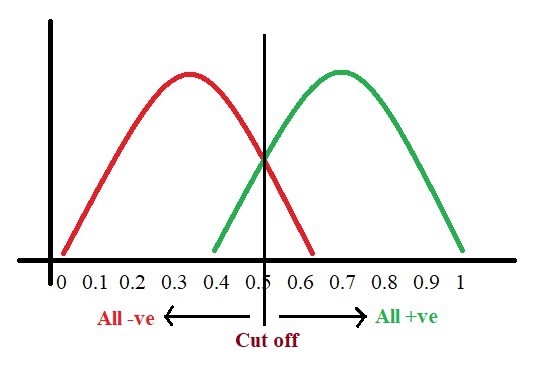
تعیین این نقطه در این مثال، عدد ۰٫۵ و در مثالهای واقعی کاملا بسته به شرایط عددی بین ۰ تا ۱ خواهد بود، باعث ایجاد خطاهایی ناخواسته خواهد شد :
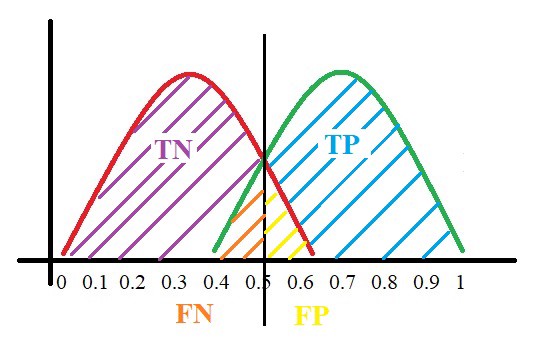
ناحیه زرد رنگ بیانگر افرادی است که اشتباهاً بیمار تشخیص داده خواهند شد (False Positive – نادرست مثبت) و ناحیه نارنجی رنگ هم بیانگر افرادی است که به اشتباه سالم تشخیص داده شده اند (نادرست منفی – False Negative).
هر چه مدل ما دقیقتر باشد، این دو خط قرمز و سبز باید اشتراک کمتری داشته باشند یعنی بتوانیم با قطعیت بیشتری دستهبندی دادهها را انجام دهیم و نتیجتا خطای کمتری هم تولید شود.
انتخاب درست نقطه تقسیم یا تعیین آستانه تقسیم در یک مدل، تصمیم مهمی است چون تغییر آن باعث افزایش یا کاهش خطا خواهد شد. برای سنجش خطاهای تولید شده، دو معیار Sensitivity (Recall) و Specificity را به صورت زیر تعریف می کنیم :
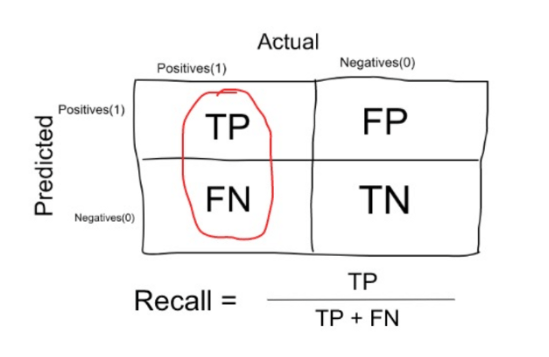
معیار بازخوانی یا همان Sensitivity (حساسیت) را قبلاً تشریح کردهایم، معیاری که نشان میدهد چقدر از بیماران واقعی (دسته مثبت) را نسبت به کل جامعه بیماران، شناسایی کردهایم. یعنی نسبت آنهایی که درست شناسایی شدهاند به مجموع تمام بیماران (آنهایی که به درستی بیمار شناخته شده اند + آنهایی که اشتباهاً سالم تشخیص داده شدهاند). هدف ما این است که حساسیت مدل ما بالا باشد یعنی تعداد بیشتری از بیماران را شناسایی کند.
معیار Specificity همین مفهوم را برای افراد سالم (یا دسته منفی) نشان میدهد یعنی چند نفر از افراد واقعا سالم را از کل افراد سالم، درست تشخیص دادهایم :
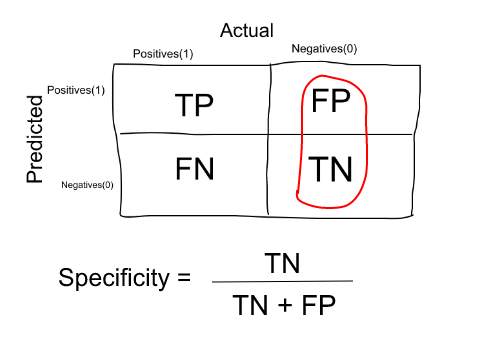
میزان افرادی که بیمار نیستند (درست منفی – TN) به کل افراد سالم (آنهایی که سالم تشخیص داده شدهاند و آنهایی که اشتباهاً بیمار فرض شدهاند)، Specificity مدل را تشکیل میدهد.
حال میخواهیم با تغییر حد آستانه در دستهبندی، تغییرات این دو معیار را با هم بسنجیم. اگر حد آستانه را پایین بیاوریم مثلا در مثال فوق آنرا روی ۰٫۴ تنظیم کنیم و بالاتر از آنرا بیمار اعلام کنیم، طبق شکل متوجه میشویم که تمام بیماران را تشخیص خواهیم داد یعنی حساسیت مدل بالاست اما میزان زیادی از افراد سالم را هم بیمار اعلام خواهیم کرد یعنی Specificity ما پایین خواهد آمد. بالعکس اگر حد آستانه را بالا ببریم، مثلا آنرا روی ۰٫۶ تنظیم کنیم، تمام افراد سالم را درست تشخیص خواهیم داد اما بیماران زیادی را هم به اشتباه، سالم اعلام خواهیم کرد یعنی Specificity مدل بالا و حساسیت آن کم خواهد شد. با تغییر این آستانه به شکل زیر برای بیان نسبت میان حساسیت و Specificity خواهیم رسید :

برای اینکه بهتر بتوانیم از این نمودار استفاده کنیم و مقادیر هر دو محور با هم رشد یا کاهش پیدا کنند به جای Specificity از ۱ منهای Specificity استفاده میکنیم :

با این ترتیب، نموداری حاصل میشود که به آن نمودار ROC - Receiver Operating Characteristics و یا منحنی ROC میگوییم.

اگر بخواهیم دقیقتر به این نمودار که میزان جداکنندگی و دقت کار مدل ما را نشان میدهد، نگاه کنیم متوجه این رابطه خواهیم شد :
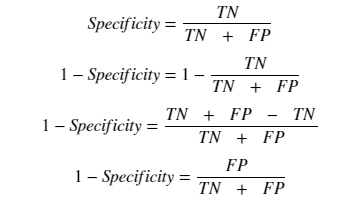
۱ منهای Specificity نرخ تولید خطای دستهبندی (برای دسته مثبت) را نشان میدهد. تعداد افراد سالمی که بیمار تشخیص داده شدهاند به کل افراد سالم. به این معیار FPR هم گفته میشود :
طبق این تعریف میتوانیم نرخ تولید دادههای درست (برای دسته مثبت) را هم به صورت زیر تعریف کنیم :
که همان فرمول حساسیت یا بازخوانی (Recall) است. هر دوی این فرمولها عددی بین صفر تا یک را تولید میکنند. در نمودار ROC نرخ تولید دادههای درست یعنی TPR،محور Y را نشان میدهد و نرخ تولید خطا برای دادههای مثبت هم (FPR) محور X را تشکیل میدهد. با این توصیف نموداری مناسب تر خواهد بود که محور Y آن به یک نزدیک باشد و محور X آن یعنی میزان تولید خطای آن، به صفر نزدیک باشد:

اما در دنیای واقعی، نمودار ما بیشتر شبیه شکل زیر خواهد بود :
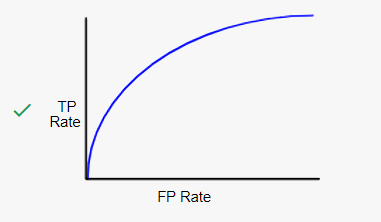
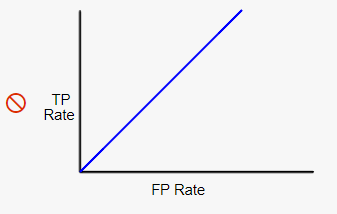
که اگر آنرا نسبت به حالت تصادفی یعنی حالتی که کاملا تصادفی اشخاص را به دو دسته بیمار و سالم تقسیم کنیم (نمودار زیر)، بهبود مدل کاملاً مشخص است :
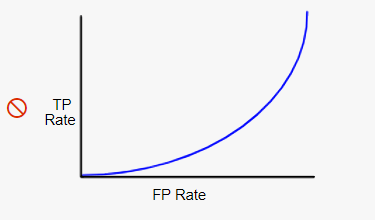
مطمئنا ایجاد نموداری به شکل زیر نشان دهنده خطای محرز در مدل است چون حتی از حالت تصادفی هم بدتر عمل کرده است :
نحوه رسم نمودار ROC
برای رسم نمودار ROC از تغییر میزان آستانه تعیین دسته مثبت و منفی استفاده میکنیم. این امر را با یک مثال به صورت دقیقتر بررسی میکنیم. فرض کنید برای صد نفر که نصف آنها بیمار و نصف آنها سالم هستند، مدلی ساختهایم که اگر حد آستانه تشخیص یک دسته از صفر تا یک تغییر بدهیم، اعداد زیر حاصل میشوند :
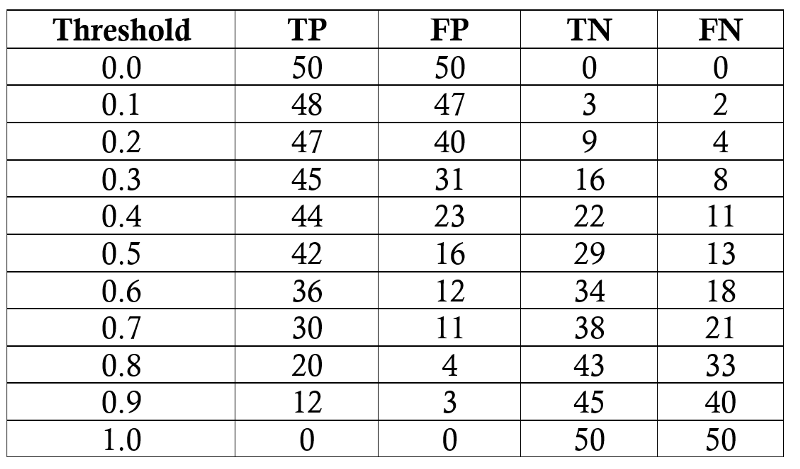
برای حد آستانه ۰٫۵ جدول پراکنش زیر را خواهیم داشت :

با اعداد فوق برای حد آستانه ۰٫۵ سه معیار صحت، بازخوانی و F1 را به صورت زیر محاسبه میکنیم :
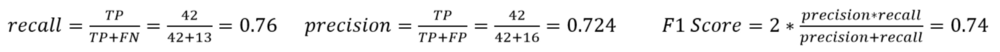
نرخ تولید خطا و نرخ تولید دادههای درست هم به صورت زیر محاسبه میشود :
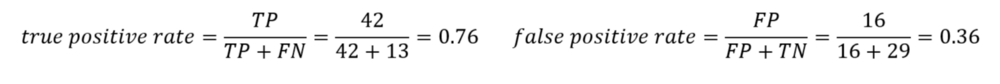
حال با محاسبه این اعداد برای مقادیر مختلف حد آستانه، جدول زیر را خواهیم داشت :
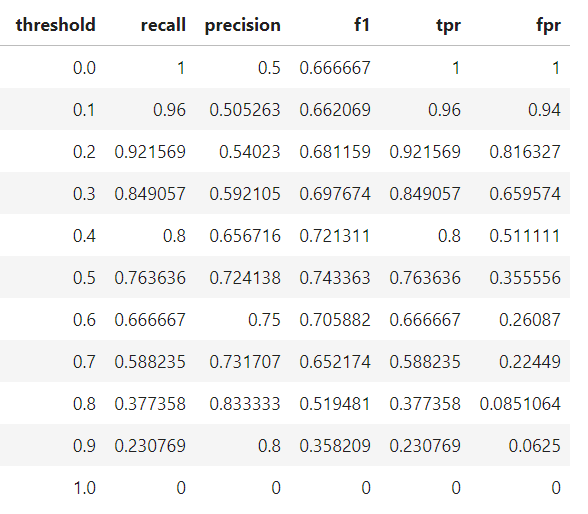
به کمک درونیابی یا افزایش نقاط ، میتوانیم نمودار زیر را برای مدل ساخته شده به دست آوریم :
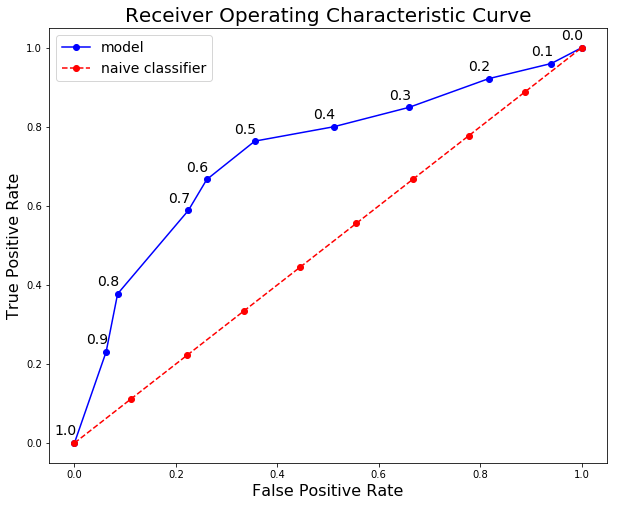
به همین ترتیب برای مدلهای بعدی هم با تغییر حد آستانه و محاسبه اعداد فوق، نمودار ROC قابل رسم خواهد بود.
سطح زیر نمودار – AUC(Area Under Curve)
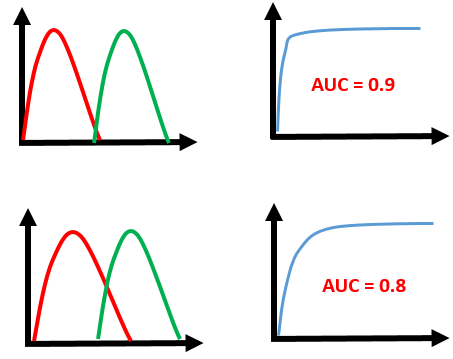
با توجه به اینکه نرخ تولید خطا و نرخ تولید دادههای درست هر دو عددی بین صفر تا یک است، در حالت ایدهآل (شکل ایدهآل نمودار ROC) ، مساحت زیر نمودار عدد یک را نشان میدهد و در حالت تصادفی عدد ۰٫۵ و در بیشتر موارد، عددی بین این دو خواهد بود که هر چه به یک نزدیکتر باشد نشان از دقت بیشتر مدل ما در تشخیص دادههای مثبت است. این مساحت که با معیار AUC نشان داده میشود، معیار دیگری است برای سنجش میزان کارآیی یک مدل که هر چه مدل دقیقتری داشته باشیم عدد آن به یک نزدیک و هر چه عملکرد ضعیفتری در تشخیص دستهها داشته باشد به عدد صفر نزدیک خواهد بود. این مفهوم را در نمودارهای زیر به خوبی میتوانید مشاهده کنید :

منابع :
- https://medium.com/greyatom/lets-learn-about-auc-roc-curve-4a94b4d88152
- https://towardsdatascience.com/beyond-accuracy-precision-and-recall-3da06bea9f6c
- https://medium.com/datadriveninvestor/understanding-roc-auc-curve-7b706fb710cb
با سلام و احترام چقدر زیبا و جانانه مفهوم مطلب رو ادا کردین خیلی ممنون بابت این اطلاعات مفیدتون که توی هیچ کلاسی نمیشد پیدا کنیم بنده درس یادگیری ماشین دارم ولی به این زیبایی که مطلب رو گفتید در سر کلاس بیان نشده بود یعنی مطلب نامفهوم ماند و در حد فرمول بیان شد