
مهارت های حوزه تحلیل و پردازش داده در یک نگاه
قبلاً درباره شروع کار در حوزه مهندسی داده در این سایت مطلبی را خدمت علاقه مندان ارائه کرده بودیم . چند روز پیش به تعدادی نمودار گرافیکی مناسب برای شناسایی مهارت های مورد نیاز برای کار در حوزه تحلیل و مهندسی داده برخوردم که آنها را هم برای علاقه مندان این حوزه مناسب می دانم.
مهم ترین این مهارتها در جدول زیر فهرست شده اند :

سایت Dataconomy یک نمودار شبکه ای از این مهارت ها به همراه ارتباطاتشان رسم کرده که کوچکی و بزرگی هر گره، نشانگر اهمیت و رواج آن مهارت در بین تحلیلگران داده می باشد. در زیر این نمودار را مشاهده می کنید. ( برای مشاهده نسخه با کیفیت آن کلیک کنید )

این مهارتها را به صورت دسته بندی شده و با رهیافت ابرکلمات در شکل زیر هم می توانید مشاهده کنید :
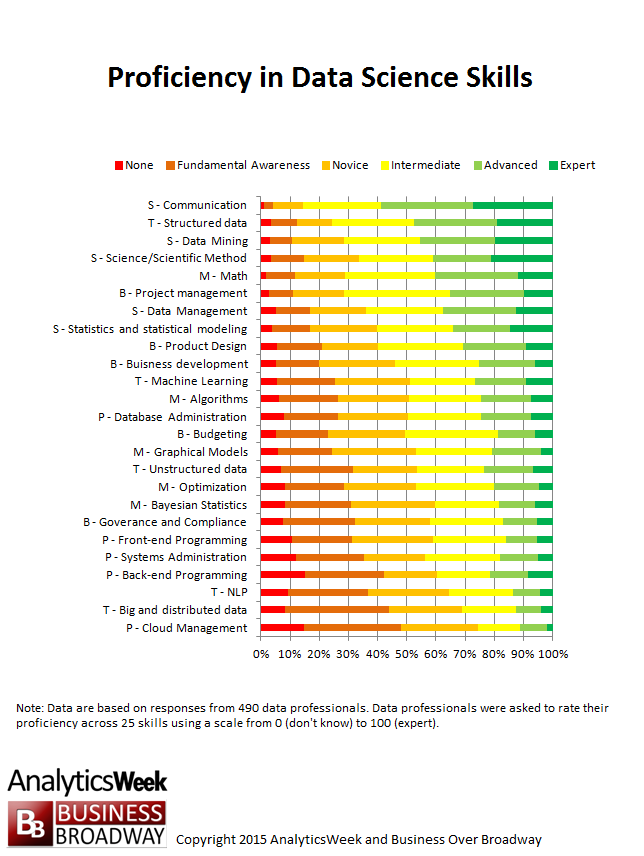
با انجام بررسی میدانی و جمع آوری اطلاعات حدود پانصد نفر از فعالان حوزه مهندسی داده نیز نمودار زیر به دست آمده است که میزان تسلط و یا مبتدی بودن هر مهارت را در بین جواب دهندگان سوالات می توانید مشاهده کنید :
 و آخرین نمودار هم مهارتهای لازم در حوزه های مختلف فناوری اطلاعات را با ذکر اهمیت هر مهارت در هر حوزه نمایش داده است :
و آخرین نمودار هم مهارتهای لازم در حوزه های مختلف فناوری اطلاعات را با ذکر اهمیت هر مهارت در هر حوزه نمایش داده است :
آقا سایتتون بی نظیره!
یعنی از خوب و خیلی خوب و عالی چند لول بالاتره!
تو ایران هیچ منبع و سایتی توی این حیطه به گرد پای شما نمیرسه.
واقعاً ممنون از این مطالب مفید.