
نصب و راهاندازی هدوپ – بخش دوم
در ادامه مطلب سری پیش که به نصب و پیکربندی اوبونتو سرور ۲۰۱۸ بر روی یک ماشین مجازی (به کمک VirtualBox ) پرداختیم، در این بخش به نصب هدوپ و بالاآوردن سرویسهای پایه آن خواهیم پرداخت. اگر اوبونتو را قبلاً نصب کردهاید آنرا اجرا کنید، WinSCP را طبق راهنمایی مقاله قبل، باز کنید تا به راحتی بتوانیم عملیات جابجایی فایلها بین ویندوز و سرور هدوپ را انجام دهیم. با زدن دکمه Ctrl+P درون WinSCP، نرم افزار Putty را هم باز کنید که هر جا لازم به وارد کردن دستورات خط فرمان بود از آن استفاده کنیم. جهت یادآوری، نام کاربری اوبونتو برای نصب هدوپ را hduser گذاشتهایم.
نصب هدوپ از طریق نسخه اصلی سایت آپاچی
در ادامهی فصل، روشهای مختلف نصب هدوپ بر روی یک سیستم را خواهیم آموخت. اگر میخواهید بدون دردسر، نسخه اصلی هدوپ و مولفههای اصلی آن یعنی HDFS ، MapReduce و Yarn را مستقیماً نصب و تنظیمات آنها را خودتان انجام دهید، از روش موجود در این بخش استفاده کنید که پیچیدگی خاصی نداشته و به راحتی قابل انجام است.
وارد سایت رسمی هدوپ شده، با کلیک بر روی دکمه دانلود، وارد بخش دانلود شوید. آخرین نسخه هدوپ که در حال حاضر ۳٫۲ است را انتخاب کرده، گزینه binary را بزنید تا وارد صفحه اصلی دانلود این نسخه شود و از صفحه باز شده، یکی از آدرسهای دانلود آنرا انتخاب کنید.
این نسخه حدود ۳۳۰ مگابایتی را دانلود نموده و آنرا با نرم افزار WinSCP به پوشه مخصوص کاربر (/home/hduser) که مجوزهای ایجاد و ویرایش فایلها را در آن دارد، منتقل کنید. میتوانید در خط فرمان لینوکس و درون پوشه کاربر، با دستور wget و دادن آدرس این فایل زیپ، آنرا مستقیماً دانلود نمایید.
حال در خط فرمان لینوکس، با رفتن به پوشهای که فایل زیپ هدوپ را در آنجا کپی یا دانلود نمودهاید، با دستور زیر آن را ازحالت فشرده خارج کنید:
با این کار، محتوای فایل زیپ هدوپ درون پوشه hadoop-3.2.0 قرار میگیرد. این کار را در WinSCP با کلیک راست بر روی فایل فوق و استفاده از File Custom Commands -> UnTar/GZip هم میتوانید انجام دهید. این پوشه را مشابه سایر نرمافزارهای اصلی لینوکس به پوشه /usr/local با نام hadoop منتقل میکنیم و مجوزهای لازم برای اجرای آن را تنظیم میکنیم.
دستور اول، یک پوشه با نام hadoop را در مسیر /usr/local ایجاد کرده و دستور دوم، محتویات پوشهی hadoop-3.2.0 را به درون پوشهی مقصد منتقل میکند ( mv مخفف move است). دستور سوم، سب میشود تا مالکیت پوشهی hadoop و تمامی محتویات آن اعم از فایل و زیرپوشهها، به کاربر جاری یعنی hduser اختصاص یابد. دستور آخر نیز خود پوشهی مبدأ یعنی hadoop-3.2.0 را که اکنون خالی است، پاکسازی مینماید ( rm مخفف remove است). فایل زیپ را برای احتیاط، فعلاً نگه میداریم.
در دستورات فوق، هر جا که نیاز به مجوز کاربر اَدمین داشتهایم، از sudo استفاده کردهایم و هر جا که خود کاربر جاری مجاز به انجام دستور بوده است مانند حذف یک پوشه درون فضای کاری خود کاربر، آنرا به کار نبردهایم.
تنظیمات اولیه هدوپ و اجرای آن
فایل اجرایی اصلی هدوپ که دستورات خط فرمان آنرا برای ما اجرا میکند، فایلی است با نام hadoop درون پوشه bin . قبل از هر کاری، این فایل را اجرا میکنیم تا مطمئن شویم تا اینجا همه چیز به خوبی پیش رفته است.
اگر در خط اول خروجی، پیام
را مشاهده کردید، تبریک میگوییم، تا اینجای کار را درست انجام دادهاید و هدوپ شما آماده پیکربندی و تنظیمات اولیه است.
تنظیمات اولیه هدوپ
برای اجرای هدوپ در ابتدا باید متغیرهای محیطی مورد نیاز کل سیستم را مقداردهی کنیم. ابتدا فایل hadoop-env.sh را به صورت زیر با nano باز کرده، مقدار متغیر $JAVA_HOME آنرا مشابه مقاله قبل، تنظیم و مقدار دهی کنید (این کار با WinScp راحتتر انجام میشود):
بگردید. علامت # را از ابتدای خط بردارید تا از حالت توضیح خارج شود و بعد آنرا مقداردهی کنید. با دکمه ترکیبی Ctrl+O تغییرات را ذخیره کرده و با Ctrl+X از ویرایشگر نانو خارج شوید.
برای تنظیمکردن متغیرهای محیطی هدوپ به گونهای که در همه جای سیستم بتوان به راحتی آن را اجرا نمود، تنظیمات را در انتهای فایل /etc/profile با اجرای nano به صورت زیر وارد کنید.
از فایل ~/.profile هم میتوانید برای مقدار دادن به تنظیمات محیطی لینوکس برای کاربر جاری استفاده کنید.
دستورات زیر را در بخش انتهایی از فایل باز شده وارد کنید:
همانطور که مشاهده میکنید، در تنظیمات بالا، هر جا که نیاز به تنظیم کاربر مربوطه بوده است، از کاربر فعلی یعنی hduser استفاده کردهایم. در ضمن، حواستان به دوگیومه ابتدا و انتهای متغیر HADOOP_OPTS باشد که بهتر است خودتان آنها را تایپ نمائید و کپی پیست نشود. یادتان نرود که بعد از ذخیره این مقادیر، آنها را با دستور زیر در سیستم اعمال کنید:
ساخت پوشه های مورد نیاز در هدوپ
یک پوشه برای ذخیره موقت دادههای هدوپ و دو پوشه هم برای دادههای سرویسنام(Name Node) و سرویسداده(Data Node) آن، باید ایجاد کنیم. می توانید از آدرسهای زیر استفاده کنید:
فایلهای پیکربندی هدوپ
بعد از این مرحله باید فایلهای مختلف پیکربندی هدوپ را ویرایش کرده، تنظیماتی را به آنها اضافه کنیم. با توجه به اینکه مالک اصلی پوشه نصبی هدوپ را کاربر hduser تنظیم کردهایم، تمام ویرایشهای زیر را به راحتی درون WinScp هم میتوانید انجام دهید. کافی است به پوشه /usr/local/hadoop/etc/hadoop بروید و روی هر فایل ذکر شده در زیر، دو بار کلیک کنید تا آماده ویرایش شود.
ابتدا از فایل etc/hadoop/core-site.xml در مسیر نصب نرمافزار هدوپ شروع می کنیم. به جای آدرس دقیق پوشه هدوپ، از متغیر محیطی $HADOOP_HOME که در بالا آنرا تنظیم کرده ایم، استفاده میکنیم که اگر برخی کاربران پوشه دیگری را برای نصب هدوپ استفاده کرده باشند، بتوانند دستور زیر را بدون تغییر ، کپی کرده و استفاده کنند :
و مقادیر زیر را به انتهای آن اضافه میکنیم (دقت کنید که تگ < configuration > از قبل در فایل core-site.xml موجود است و تنها بخش داخلی متن زیر را به آن اضافه کنید).
دقت کنید که در کد فوق، دو ویژگی هدوپ را تنظیم کردهایم. اولی آدرس وب پیشفرض دسترسی به فایلسیستم هدوپ و دومی، آدرس پوشهی موقت هدوپ است.
مرحله بعد، نوبت فایل etc/hadoop/hdfs-site.xml در مسیر نصب هدوپ است. مشابه فوق، این فایل را هم با دستور زیر، درون ویرایشگر باز میکنیم (البته با WinScp این کار سریعتر و راحتتر انجام میشود):
و مقادیر زیر را مطابق فوق به آن اضافه میکنیم :
اگر به مقادیر فوق دقت کنید، میبینید که ضریب تکرار بلاکهای یک فایل را عدد یک (۱) تعیین کردهایم که برای نصب محلی هدوپ همین مقدار کافی است. همچنین، آدرس محل ذخیرهی دادههای سرویس نام و سرویس دادهی هدوپ را هم مشخص کردهایم (همان پوشههایی که چند مرحله قبل آنها را ساختهایم).
اگر بخواهیم با Yarn برنامههای توزیع و تجمیع ( map/reduce ) خود را اجرا کنیم به تنظیمات زیر هم نیاز داریم. درون فایل $HADOOP_HOME/etc/hadoop/mapred-site.xml مقادیر زیر را وارد می کنیم:
به عنوان آخرین تنظیمات، درون فایل yarn-site.xmlمقادیر زیر را وارد کنید :
با این تنظیمات، آماده شروع کار با هدوپ هستیم. به تدریج که با هدوپ کار کنید، با تنظیمات فوق و ضرورت هر یک، آشنا خواهید شد اما قبل از آن با دستور زیر باید HDFS یا همان فضای ذخیرهسازی هدوپ را فرمت کنیم تا آماده به کار شود (اگر از شما سوالی برای فرمت کردن پوشه دادهها پرسید با Y جواب بدهید):
اجرای سرویسها و آزمایش نهایی
بعد از انجام تمام تنظیمات فوق ، نوبت استارت دو سرویس HDFS و YARN است. با دو دستور زیر این کار را انجام می دهیم:
توضیح اینکه این دو فایل در پوشه $HADOOP_HOME/sbin قرار گرفتهاند و چون این آدرس را در فایل /etc/profile درون متغیر محیطی PATH ریختهایم، لینوکس به راحتی آن را پیدا کرده و نیاز به ذکر آدرس دقیق آن نیست.
نکته: میتوانید از دستور start-all.sh برای راهاندازی تمامی سرویسهای هدوپ و stop-all.sh هم برای متوقفکردن آنها استفاده کنید.
حال کافیست تا درون مرورگر در سیستم عامل میزبان یعنی ویندوز برویم و این دو آدرس را وارد کنیم که اگر نام سرور هدوپ را در تنظیمات هاست ویندوز انجام ندادهاید، از آدرس آی پی سرور هدوپ به جای نام هاست استفاده کنید:
که اولی برای نمایش اطلاعات کامل کلاستر شامل تعداد نودها، کارهای در حال انجام و فایلهای لاگ استفاده میشود و دومی برای کار با HDFS و ذخیره و نمایش فایلهای ذخیرهشده در آن از طریق وب کاربرد دارد. پورتهای ذکرشده، پورتهای پیشفرض هدوپ ۳ هستند که میتوانید در فایلهای تنظیمات هدوپ، آنها را تغییر دهید.
با استفاده از دستور jps هم میتوانید سرویسهای جاوای در حال اجرا را مشاهده کنید:
با دستور زیر هم میتوانید پورتهایی که برنامههای جاوا اشغال کردهاند را ببینید:
که در خروجی این دستور پورت ۹۸۷۰ و ۸۰۸۸ را هم باید حتماً مشاهده کنید. اگر همه چیز اکی باشد، روی پورت ۹۸۷۰ باید واسط وب پیشفرض HDFS را مشاهده کنید :
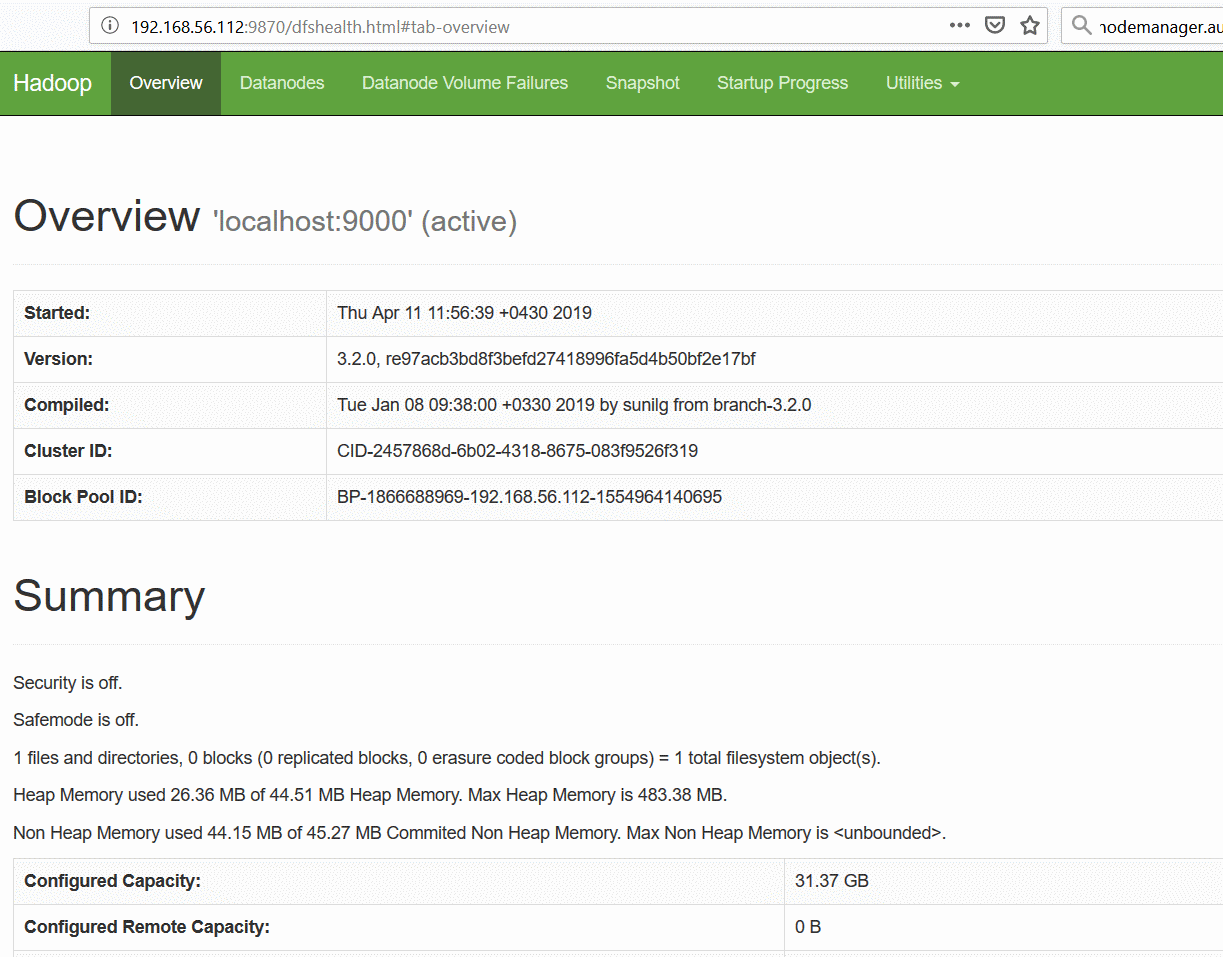
همانطور که در شکل فوق مشاهده می کنید، اطلاعات کاملی را درباره HDFSمی توانید در آدرس ۹۸۷۰ بیابید. در منوی utilities این صفحه، با زدن browse the file system می توانیم فایلهای ذخیره شده در هدوپ را ببینیم، پوشه بسازیم، داده های موجود در آن را دانلود و یا فایل دادهای را آپلود کنیم. در ادامه سری آموزشی کلانداده به زبان ساده که به اجرای برنامههای مبتنی بر روش توزیع و تجمیع[۱] بپردازیم، از این واسط وب، بسیار استفاده خواهیم کرد.
اگر با این واسط وب، قصد ساخت پوشه و یا آپلود فایلی را در HDFS داشته باشید با خطای مجوز مواجه خواهید شد. برای رفع این مشکل این خصوصیت را به فایل core-site.xml اضافه نمایید (اختصاص نام کاربری hduser به کاربر وب هدوپ):
بعد از راهاندازی مجدد سرویسهای هدوپ، مشکل مجوز برای واسط وب پیشفرض هدوپ هم رفع خواهد شد. در آموزش بعدی، به نحوه کار با HDFS و مدیریت فایلها در هدوپ خواهیم پرداخت. با ما همراه باشید.
[۱] Map/Reduce
سلام
ممنون از اموزش خوبتون
میخواستم بدونم قسمت بعد کی بارگزاری خواهد شد؟؟
متشکرم
ممنونم از نظر لطفتون. دارم بخش HDFS را آماده می کنم از زودتر از ده روز آینده نخواهد شد.
ممنون بابت آموزش
ممنون از آموزش خوبتون
میخواستم بپرسم ادامه مطالب را کی قرار خواهد گرفت ؟
باتشکر
سلام. مطالب زیادی در این حوزه آماده کرده ام اما متاسفانه وقت کافی برای به روز رسانی سایت ندارم. امیدوارم به تدریج ادامه این بخش از سایت یعنی قسمت کلان داده به زبان ساده تکمیل شود.
سلام. خیلی ممنون از آموزش خیلی خوبتون. میشه لطفا راهنمایی کنید که در ادامه mahout رو چطور نصب کنم؟
سلام،
از تمامی دوستان دعوت میکنم به وبلاگ من هم سری بزنند،
آموزش نصب هدوپ رو هم گذاشتم.
narmafzaria.blogfa.com