
مقدمه ای بر سامانه های توصیه گر (Recommender Systems)
مقدمه
شاید تا بحال برای شما این سوال پیش آمده باشد که شرکت گوگل با چه الگوریتمی تبلیغات هوشمند را به کاربران نمایش می دهد ؟ و یا سایتهای تجارت الکترونیک با چه روشی بخش افرادی که این محصول را خریده اند، این محصولات را نیز سفارش داده اند را مدیریت می کنند و یا فیس بوک چگونه هنگام آپلود عکس ها و برچسب زنی آنها توسط ما، نام درست دوستان را به ما پیشنهاد می دهد ؟
پاسخ تمام این سوالات ، استفاده این سایتها از سامانه های توصیه گر است که با رشد روزافزون اطلاعات در دنیای حاضر و نیز افزایش چشمگیر کاربران آنلاین، تحویل اطلاعات درست و مناسب به آنها اهمیتی حیاتی برای این شرکتها یافته است که این امر خود منجر به افزایش تحقیقات در حوزه الگوریتم های توصیه گر شده است .
شرکتها با ساخت سامانه های هوشمندی که رفتار گذشته کاربر و نیز رفتار کاربران مشابه را بررسی می کند، پیشنهادات و توصیه های مناسب و مورد توجه کاربر را به او ارائه می دهند . مواردی از قبیل فرصتهای شغلی مناسب کاربر ، فیلمهای مورد علاقه کاربر، ویدئوهای پیشنهادی، دوستان فیس بوکی که احتمالاً آنها را می شناسید ، افرادی که این محصول را خریده اند،این محصولات را نیز خریده اند و ….. از جمله موارد پیشنهادی به کاربران می تواند باشد.
این مقاله ترجمه ای آزاد از مقاله ای با همین نام در سایت آنالیتیکز ویدیا است.
سامانه های توصیه گر چه هستند ؟
سامانه های توصیه گر، الگوریتم های نسبتاً ساده ای هستند که مناسب ترین و دقیق ترین پیشنهادات را با بررسی و کاوش اطلاعات مرتبط با کاربران از بانک اطلاعاتی مربوطه، به کاربر ارائه می کنند. این سامانه ها، با بررسی انتخاب های کاربران در گذشته ، الگوهایی را در داده ها پیدا می کنند که با توجه به آن الگوهای رفتاری ، برای هر کاربر توصیه مناسب را نمایش می دهند.
انواع موتورهای (الگوریتم) توصیه گر
سیستم های توصیه گر معمولا بر اساس چگونگی تولید توصیه ها، به دسته های زیر طبقه بندی میشوند:
- محتوا محور: براساس خصوصیات کالاها و اقلام و مشابهت بین آنها و نیز علایق کاربر (در صورت وجود)، توصیه هایی به کاربر ارائه خواهیم کرد.
- مشارکت محور (Collaborative filtering) : به کاربر اقلامی توصیه خواهد شد که دیگران در گذشته با تمایلات و ترجیحات مشابه او این اقلام را پسندیدند. یعنی بر اساس رابطه بین کاربران و کالاها، اقلام جدید به کاربر توصیه می شود . در این روشها، خود کالا اهمیتی ندارد و بر اساس انتخاب کاربران دیگر و انتخاب های گذشته خود کاربر، به او پیشنهادهای جدیدی ارائه می کنیم . این روش بر سلایق مشترک بنا نهاده شده است .
روشهای مشارکت محور خود به چند دسته تقسیم می شوند :
- کاربر – کاربر : در این روش بر اساس یافتن مشابهت بین کاربران (می توان از الگوریتم های دسته بندی یا خوشه بندی برای این منظور استفاده کرد)، به هر کاربر اقلامی را پیشنهاد می کنیم که کاربرهای شبیه به او، معمولاْ آنها را انتخاب کرده اند. البته جدیداْ روشهای اعتماد محور هم بوجود آمده اند که بر اساس روابط کاربر با سایرین در شبکه های اجتماعی، اولویت توصیه ها را به کاربران مورد اعتماد یک کاربر اختصاص میدهیم و بر اساس انتخاب های آنان،پیشنهادهایی مطرح می کنیم.
- کالا – کالا : در این روش بر اساس مشابهت بین کالاها ، کالایی را به کاربر توصیه می کنیم که با کالاهای قبلی انتخابی او ، بیشترین مشابهت را داشته باشد .
- روشهای متفرقه : روشهایی مانند تحلیل سبد خرید که جزء روشهای کلاسیک داده کاوی هم محسوب میشود، می تواند در یافتن اقلام مشابه با یک محصول براساس سلایق کلی مشتریان، به ما کمک کند .
- دانش محور : متدهای مبتنی بر دانش با استدلال در مورد آن اقلامی که نیازمندی های کاربر را رفع میکنند، توصیه هایی ایجاد میکند. این روشها به اطلاعات کاملی از کاربر و علایق و نیازمندیهای او وابسته هستند.
- رویکردهای ترکیبی : در این رویکردها، از ترکیبی از رویکردهای بالا استفاده میشود.
در این مقاله به توضیح دو نوع اصلی از الگوریتم های توصیه گر فوق که توسط اغلب شرکتهای بزرگ دنیا مانند گوگل و فیس بوک مورد استفاده قرار می گیرند، خواهیم پرداخت . این دو نوع اصلی عبارتند روشهای محتوامحور و روشهای مشارکت محور (همکاری و استفاده از کاربران مشابه) .
برای توصیف این دو نوع از موتورهای توصیه گر، از یک سناریو و مثال ساده استفاده می کنیم . فرض کنید که یک فروشگاه آنلاین فروش گوشی های هوشمند داریم و قصد داریم به مشتریان خود بهترین پیشنهاد خرید را ارائه کنیم که به نیازها و سلیقه او بسیار نزدیک باشد و احتمال خرید گوشی را برای ما بالا ببرد.
برای سادگی بیشتر ، این سناریو را به پنج گوشی هوشمند S1 تا S2 محدود می کنیم که دو ویژگی اصلی آنها برای کاربران اهمیت دارد یکی طول عمر باتری و دیگری کیفیت صفحه نمایش. درباره این گوشی ها اطلاعات زیر را داریم :
- S1 طول عمر باتری مناسب و صفحه نمایش بی کیفیتی دارد .
- S2 باتری با کارآیی بالایی دارد اما صفحه نمایش آن بسیار بی کیفیت است.
- S3 باتری ای دارد که جزء بهترین های بازار است اما صفحه نمایش آن کیفیت مناسبی ندارد.
- S4 و S5 صفحه نمایش خوبی دارند اما کارآیی باتری آنها پایین است .
با داشتن این خصوصیات راجع به هر گوشی، ما یک جدول یا ماتریس محصول – ویژگی (Item-Feature) ایجاد می کنیم که هر سطر آن نمایانگر یک گوشی بوده و ستون های آن هم میزان کیفیت باتری و صفحه نمایش را به صورت عددی بین صفر تا یک نمایش می دهد.
ماتریس محصول – ویژگی
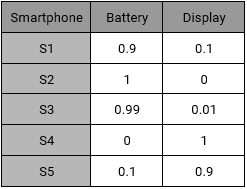
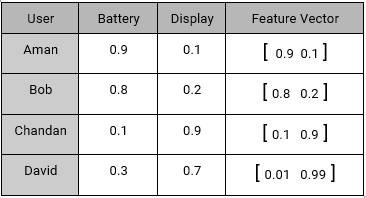
علاوه بر اطلاعات گوشی ها، اطلاعات سلیقه ای چهار تا از کاربران فعال خود را نیز داریم :
- امان برایش باتری از صفحه نمایش مهم تر است .
- باب هم یک گوشی با باتری خوب را ترجیح می دهد.
- چاندا هم کیفیت مناسب صفحه نمایش برایش مهم است و طول عمر نرمال گوشی برایش کفایت می کند.
- دیوید کیفیت صفحه نمایش برایش اهمیت زیادی دارد اما باتری را چندان با اهمیت نمی داند.
این اطلاعات را هم باید به صورت عددی تبدیل کنیم و جدول یا ماتریس کاربر – ویژگی را به کمک آن بسازیم :
ماتریس کاربر – ویژگی
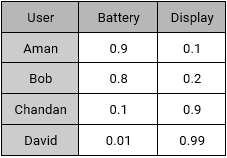
حال با توجه به دو جدول یا ماتریسی که ساخته ایم (ماتریس کاربر-ویژگی و ماتریس محصول-ویژگی) می توانیم از سامانه توصیه گرخود را برای این فروشگاه آنلاین با توجه به یکی از دو الگوریتم زیر ایجاد کنیم .
سامانه محتوا محور
سامانه های توصیه گر مبتنی بر محتوا، بر اساس میزان مشابهت ویژگی های محصولات و ویژگیهای کاربر ، توصیه های خود را انتخاب می کنند. برای این منظور برای هر محصول و هر کاربر یک بردار ویژگی ایجاد می کنیم و به کمک ضرب بردارها، بیشترین مشابهت بین محصول و کاربر را به ترتیب زیر تعیین می کنیم و به کاربر نمایش می دهیم.
ابتدا بردار ویژگی متناظر با کاربران را ایجاد میکنیم :
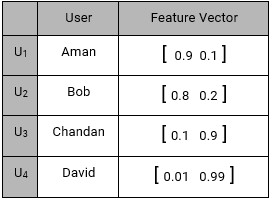
سپس بردار ویژگی محصولات را مشابه فوق ایجاد می کنیم :
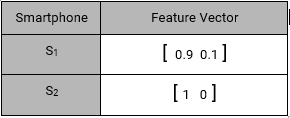
برای بقیه محصولات هم این بردارها را محاسبه و تولید می کنیم.
حال به کمک رابطه زیر توصیه محصول – کاربر مبتنی بر محتوای خود را ارائه می کنیم :
MAX ( U(j)T . I(i) ) i,j -> n,m
همانطور که می بینید ترانهاده بردار ویژگی کاربر در بردار محصول ضرب می شود و بیشترین مقدار حاصل ، بهترین انتخاب برای کاربر خواهد بود. برای یوزر U1 یا همان امان، به ترتیب زیر محصولات پیشنهادی را تعیین می کنیم :
بنابراین سه محصول S1,S2 و S3 بیشترین امتیاز را به دست می آورند و به عنوان محصولات پیشنهادی ما به کاربر معرفی میشوند.
سامانه مشارکت محور (روش فیلتر همکاری یا سلایق مشترک)
توصیه های محتوا محور علیرغم سادگی خود، چند ضعف عمده دارند . اول اینکه سلیقه یک کاربر را ما ممکن است در ابتدای کار نداشته باشیم و فقط مشخصات کلی او مانند سن و تحصیلات و شهر و … برای ما مشخص باشد . نکته دوم اینکه روابط بین ویژگی ها را با این روش نمی توان مدل کرد مثلا کاربری داریم که صفحه نمایش برایش مهم است به شرطی که نوع آن رتینا باشد و گرنه صفحه نمایش برایش چندان اهمیت ندارد. این مورد را با جداول فوق نمی توانیم مدلسازی کنیم. اینجاست که به سراغ روش دوم موتورهای توصیه گر می رویم . روش فیلتر بر اساس رفتار سایر کاربران یا روش سلایق مشترک . در این روش رفتار سایر کاربران مشابه با این کاربر مانند سابقه خرید، محصولات لایک شده، امتیازدهی ها و سبد خرید آنها بررسی می شود و بسته به رفتار آنان، محصولاتی به کاربران جدید پیشنهاد می گردد.
در شکل زیر که از ویکی پدیای روش مشارکت محور برداشته شده است ، این مفاهیم را به صورت گرافیکی می توانید مشاهده کنید :

البته در این روش، ما رهیافت های مختلفی داریم . مثلاً می توانیم بر اساس کاربر، فیلتر خود را انجام دهیم (منظور از فیلتر انتخاب یک یا چند محصول از بین چندین محصول ) یعنی کاربری را بیابیم که بیشترین مشابهت را با کاربر جاری از لحاظ خرید و امتیازدهی و … دارد و با توجه به انتخاب های آن کاربر، پیشنهادهای خود را مطرح کنیم یا اینکه بر اساس محصولات ، فیلتر خود را انجام دهیم . یعنی بر اساس اینکه کاربر جاری قبلاً چه محصولی را خریده است و بررسی بقیه کاربرانی که آن محصولات را خریده اند، چه محصولات دیگری را سفارش داده اند، به کاربر هم همانها را پیشنهاد بدهیم . نسخه ساده ای از این حالت را در این مثال، با هم بررسی می کنیم .
در این روش ما ماتریس محصول-ویژگی نداریم که باید آنرا به نحوی تولید کنیم اما فرض می کنیم که جدول یا ماتریس کاربر – ویژگی را مشابه قبل داریم :
ماتریس کاربر- ویژگی
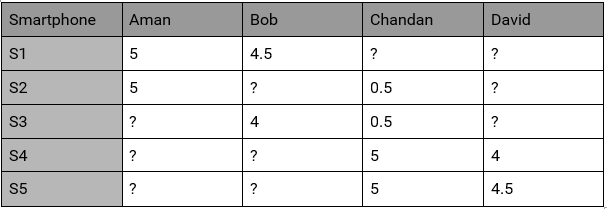
همانطور که گفتیم در این روش ما ویژگی محصولات را نداریم اما رفتار کاربران تا حدودی برایمان مشخص شده است مثلاً امتیازدهی بعضی از کاربران را به محصولات مطابق جدول زیر در بانک اطلاعاتی خود داریم :
ماتریس کاربر-رفتار
مقادیر ماتریس فوق طبق قانون ساده زیر محاسبه می شوند :
Bi,j = {r , if Uj has given “r” rating to a Si
?, if no rating is given
یعنی اگر کاربر به محصول Si امتیاز داده باشد همان امتیاز را نمایش می دهیم و در غیر اینصورت علامت سوال را نشان می دهیم به این معنا که کاربر نظرش را راجع به این محصول نمی دانیم .
از این ماتریس می توانیم استفاده کنیم تا بردار ویژگی هر محصول را به کمک رفتار سایر کاربران حدس بزنیم (مشارکت) یعنی به کمک رفتار تعدادی از کاربران در امتیاز به یک محصول و با دانستن تعداد ویژگی های محصول، به کمک چند معادله ریاضی ، بردار ویژگی متناظر با آن محصول را به دست آوریم . برای این مثال ما طول بردار را همان دو در نظر می گیریم و هدف ما برای هر محصول به دست آوردن x1 و x2 خواهد بود که متناظر با دو ویژگی محصول هستند .
در این مساله و با توجه به ماتریس فوق در می یابیم که S1 توسط دو کاربر امان و باب به ترتیب دو امتیاز ۵ و ۴.۵ را گرفته است و امتیاز دیوید و چاندا به این محصول مشخص نیست . پس برای گوشی S1 ما دو مقدار نامعلوم x1 و x2 را داریم :
که این بردار دوتایی می تواند همان بردار محصول-ویژگی ما باشد.
برای یافتن این دو مقدار به یک دستگاه دو معادله دو مجهولی نیاز داریم که آنرا با دو معادله زیر و با توجه به رفتار امان و باب می توانیم به راحتی به دست آوریم :
حل این معادله به ما این مقادیر را می دهد : x1 = 5.5 and x2 = 0.5
و به طور مشابه داریم :
اکنون که ماتریس محصول – ویژگی را به کمک رفتار کاربران توانستیم ایجاد کنیم، می توانیم با روش قبلی یعنی ضرب برداری دو ماتریس کاربر-ویژگی که موجود است و ماتریس محصول-ویژگی که آنرا ایجاد کردیم و انتخاب محصولاتی با بیشترین امتیاز، توصیه مناسب به کاربران را انجام بدهیم :
که نتیجه آن برای کاربر اول یعنی امان پیشنهاد سه گوشی S1,S2 و S3 خواهد بود و چون دو گوشی اول را خود این کاربر قبلاً امتیاز داده است ، پس پیشنهاد نهایی ما به او محصول S3 خواهد بود .
در مثال فوق ما فرض کردیم که محصولات ما دو ویژگی دارند و بر همین مبنا بردار ویژگی که برای هر گوشی تشکیل دادیم دو عنصر بیشتر نداشت و آنرا با رفتار کاربران تا حدودی توانستیم حدس بزنیم . در دنیای واقعی این ویژگیها می توانند بسیار بیشتر از این باشند و یا حتی شاید مجبور باشیم به ازای هر کاربر که به محصولی رای داده اند یک ویژگی جداگانه در نظر بگیریم تا بردار ویژگی محصول نهایی از حل دستگاه معادله n مجهولی ایجاد شود. البته به روشهای دیگری هم می توان مشابهت دو کاربر را
سخن نهایی :
در این مقاله به بررسی دو روش اصلی مورد استفاده در سامانه های توصیه گر یعنی روش توصیه مبتنی بر محتوی و روش توصیه مبتنی بر سلایق مشترک با تشریح یک مثال ساده پرداختیم . در دنیای واقعی روشهای پیشرفته تر و حرفه ای تری مورد استفاده قرار می گیرند مانند دو روش ALS : Alternating Least Square Recommendations and Hybrid Recommendation Engines
مطلبی هم قبلاً درباره سامانه های توصیه گر با استفاده از بانکهای اطلاعاتی گراف محور نیز در همین سایت منتشر شده است .
یک مثال کامل با داده های واقعی در مورد توصیه فیلم به کاربران که با استفاده از اسپارک و فلسک (یک فریمورک پایتون) انجام شده است را می توانید از این آدرس مشاهده کنید.
لیست پایان نامه های ارشد کار شده در سیستمهای توصیه گر و بهبودهایی که در این زمینه روی الگوریتم های مختلف انجام شده است را هم می توانید در سایت ایران داک، مشاهده کنید .
چند منبع مفید :
برای مشاهده یک نمونه کار انجام شده در زبان فارسی هم می توانید به این آدرس مراجعه کنید .
یکی دیگر از روشهای ساخت سامانه های توصیه گر، استفاده از روش تجزیه ماتریس است که برای دیدن توضیحات و مثالی با زبان پایتون در این زمینه، می توانید به این نوشتار رجوع کنید .
ویدئوی آشنایی با الگوریتمهای سامانه های توصیه گر را هم حتماً مشاهده کنید.
سلام و عرض ادب
مطالبتون واقعا عالی و کاربردیه. لطفا در مورد متن کاوی و داده کاوی مقالات بیشتری در سایت بذارید.
ممنون.
ممنونم از شما . خیلی دوست دارم که مطالب بیشتری را منتشر کنیم اما متاسفانه فرصت و نیروی انسانی لازم برای این کار را نداریم.
خسته نباشيد،. واقعا عالي و جامع بود??????????
بسیار عالی
مساله سامانه خیلی فراگیر شده و یادگیری اش به نظرم ضروری هست.