
تحلیل جام جهانی ۲۰۱۴ برزیل با Power BI – بخش دوم
در ادامه سری آموزشی نرم افزار های هوش تجاری، در بخش دوم آموزش نرم افزار Power BI مایکروسافت به رسم نمودارهای مختلف با این ابزار و مصورسازی داده ها می پردازیم .
مصورسازی یا نمایش گرافیکی داده ها
در این بخش به مصورسازی و رسم چند نمودار به کمک مدل داده ای که در آموزش قبلی با داده های جام جهانی برزیل در سایت فیفا ایجاد کرده ایم، می پردازیم.
نمودار ستونی برای گل ها
از بخش Fields ، زیر جدول TeamGoals، مقدار داده ای Teams را به روی پنجرک اصلی بکشید و رها کنید (Drag & Drop). در مرحله بعد ستون Goals Scored یا گل های زده شده را به این مجموعه ایجاد شده با کشیدن و رها کردن اضافه کنید . باید جدولی ببینید که مقادیر این دو ستون را به این شکل نمایش دهد :
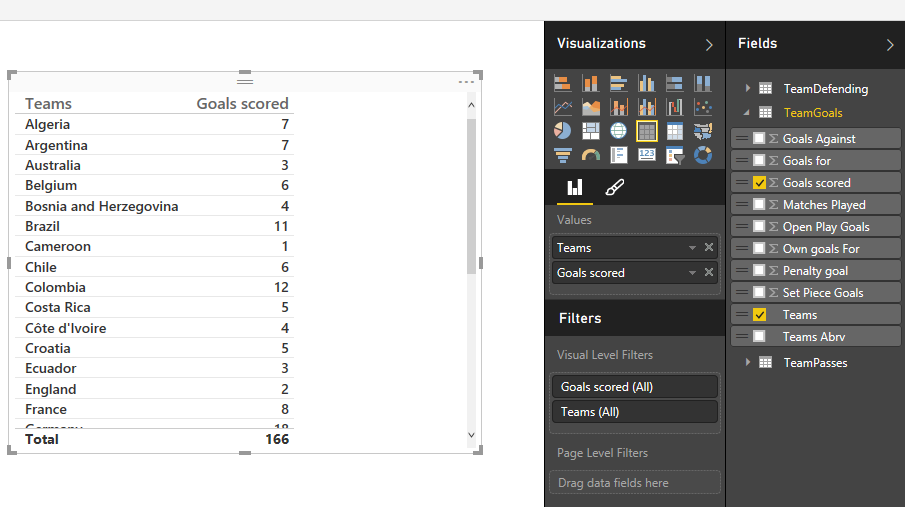
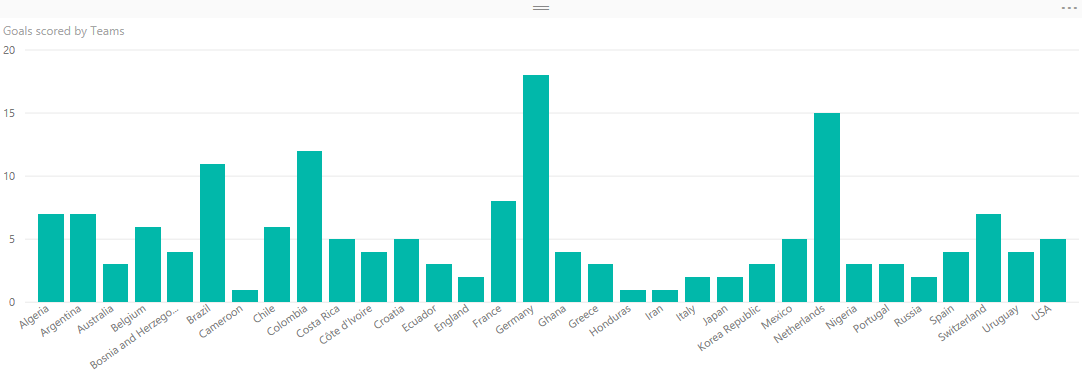
اکنون که داده های موردنظر خود برای نمایش گرافیکی را انتخاب کرده اید، از بخش Visualizations روی نمودار ستونی (Column chart) کلیک کنید و نتیجه را به راحتی مشاهده خواهید کرد.
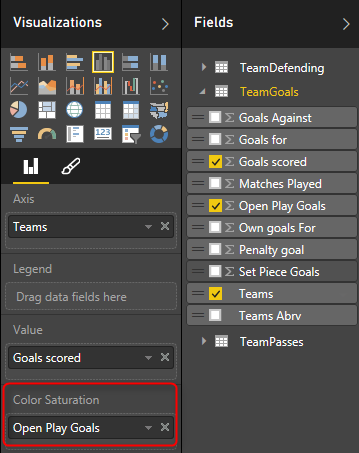
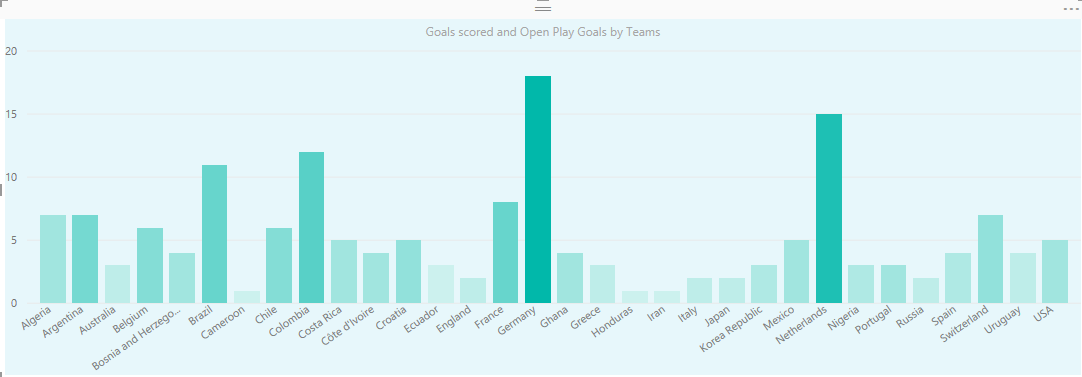
در این مرحله بیایید کمی به این نمودار ساده، اطلاعات کاملتری اضافه کنیم . می خواهیم تیم ها را بر اساس گل هایی که جوانمردانه زده اند پررنگ تر کنیم به نسبت گلهایی که با پنالتی یا گل به خود، جزء امتیازشان محاسبه شده است که البته هر سه نوع گل هم جزء داده های هر تیم در جدول تیم ها، وجود دارد. برای اینکار می توانیم از یک امکان جدید که به power BI با نام Color Saturation اضافه شده است، استفاده کنیم. از شکل زیر برای این منظور کمک بگیرید که در آن علاوه بر مشخص کردن مقدار اصلی ستون، مقداری که اشباع رنگ ستون بر اساس آن باید انجام شود نیز تعیین میشود :
می توانید رنگ زمینه نمودار را هم تغییر دهید، عناوین ستون ها را وسط چین کنید و تنظیمات نمایشی دیگری که همه در زیربخش قالب بندی (Format) از بخش visualization قرار دارند. نتیجه باید شبیه شکل زیر باشد :
نقشه
می خواهیم تیم ها را روی نقشه نشان دهیم و تیم هایی که پاس های بیشتری بینشان رد و بدل شده است را برجسته تر نمایش دهیم . برای این منظور از بخش visualization روی نمودار Map دوبار کلیک کنید .نقشه ای در پنجرک اصلی ظاهر میشود حالا از منوی Fields و از جدول TeamPasses مقدار داده ای Teams را به بخش Location از تنظیمات نقشه می کشیم و رها می کنیم . برای بخش مقادیر یا Values هم از ستون Passes Completed استفاده می کنیم .
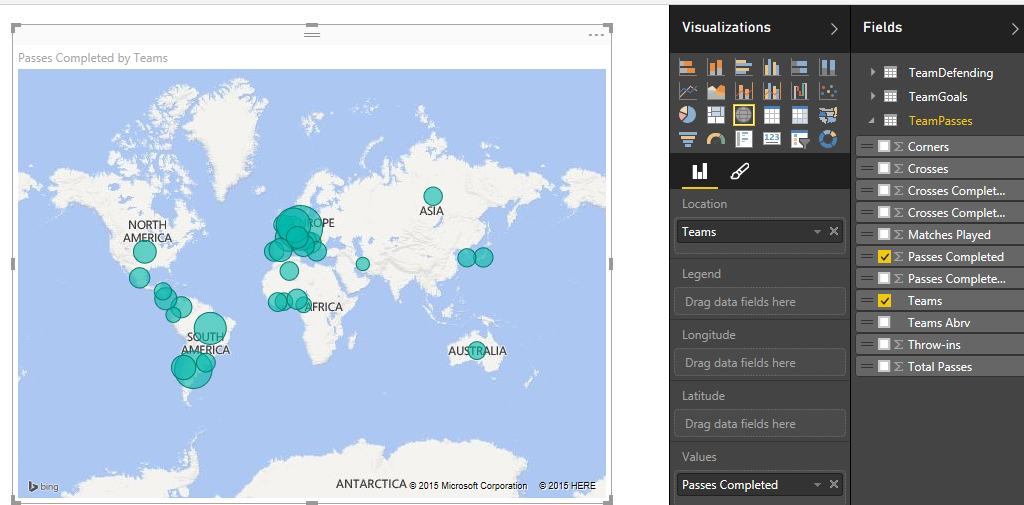
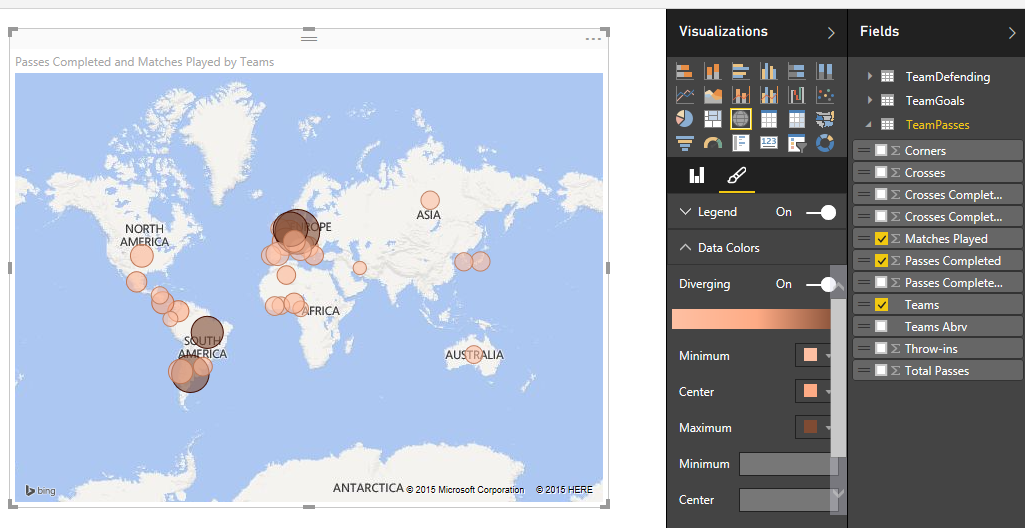
بیایید رنگ تیم ها را عوض کنیم و میزان اشباع یا پررنگ بودن هر تیم را هم به تعداد بازی که انجام داده است ، متصل کنیم . از شکل زیر بهره بگیرید :
نمودار Gauge
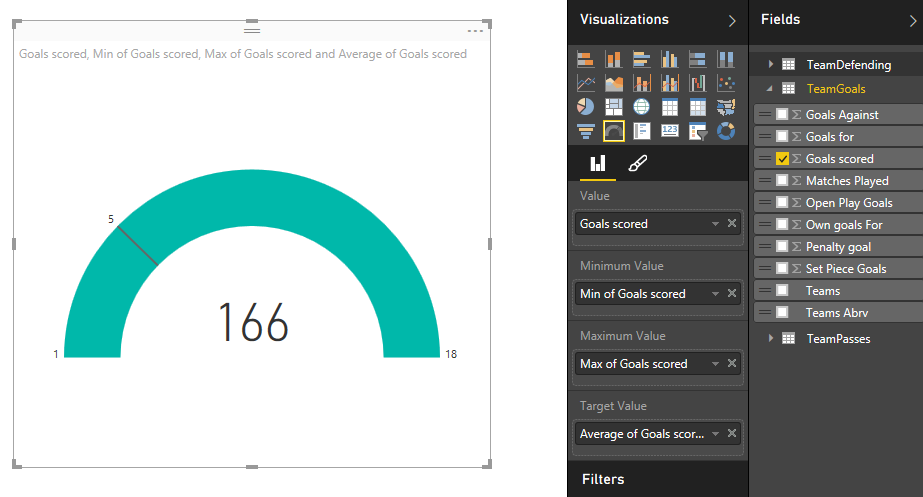
در این مرحله از سفر به دنیای Power BI ، قصد ایجاد یک نمودار Gauge بر اساس گل های رد و بدل شده داریم که در آن کمینه و بیشینه نمودار ، ماکزیمم و مینیمم گلهای رد و بدل شده و مقدار هدف هم میانگین این گلها خواهد بود . از شکل زیر برای تنظیمات این نمودار استفاده کنید :
ستون های به هم پیوسته (Clustered) و نمودار خطی
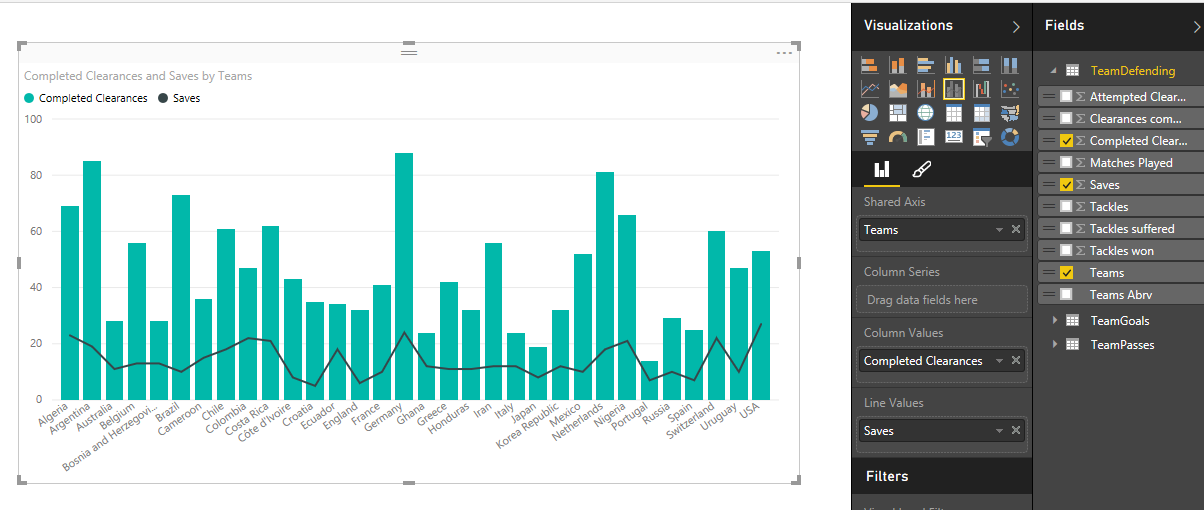
به عنوان آخرین کار، مطابق شکل زیر روی نمودار ستونی Clustered کلیک کنید تا میزان دفاع کامل هر تیم Completed Clearance به همراه میزان Saves (احتمالا مهار توپ) را در یک نمودار بتوانیم نشان دهیم . تنظیمات را مطابق زیر انجام دهید :
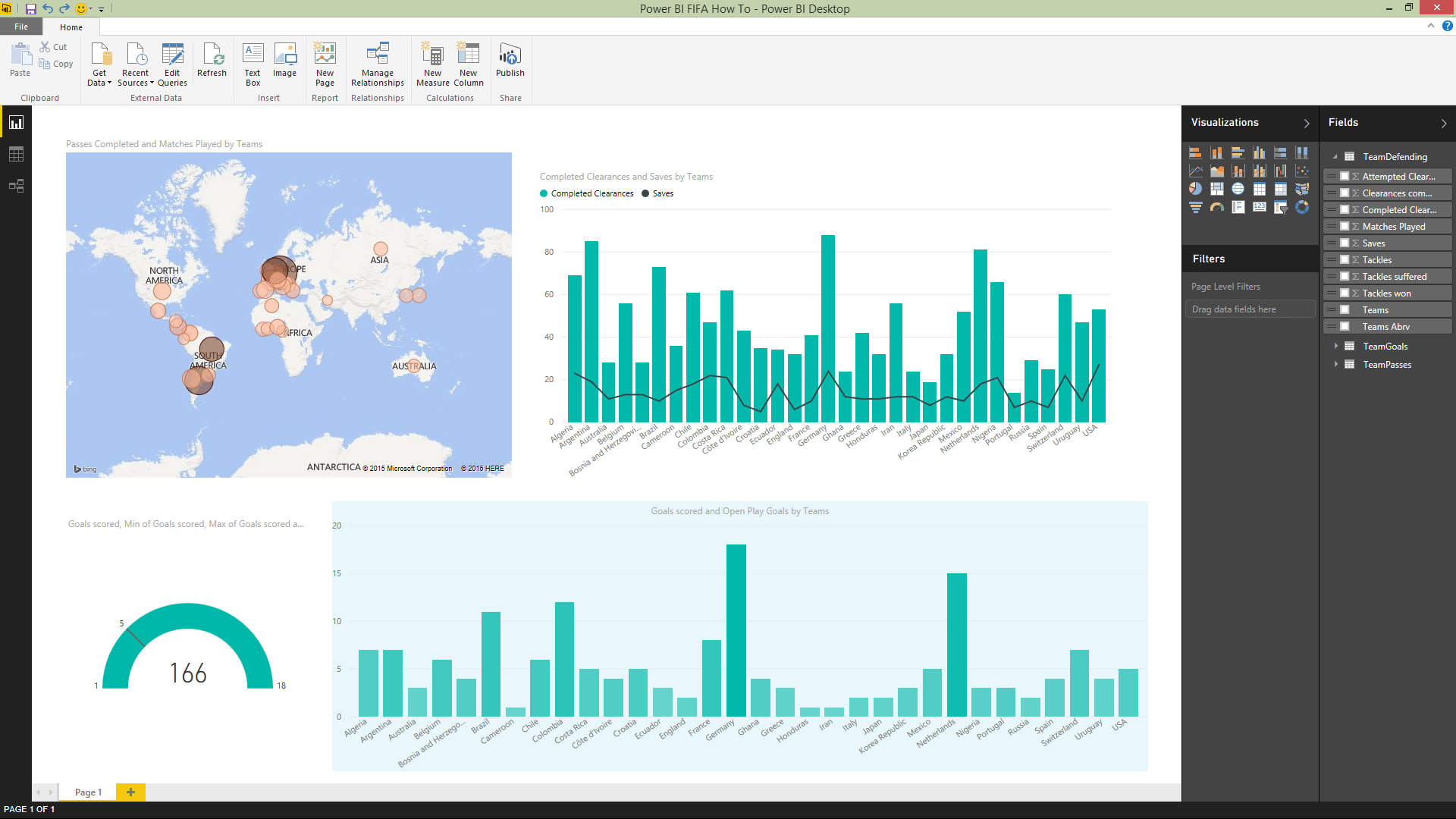
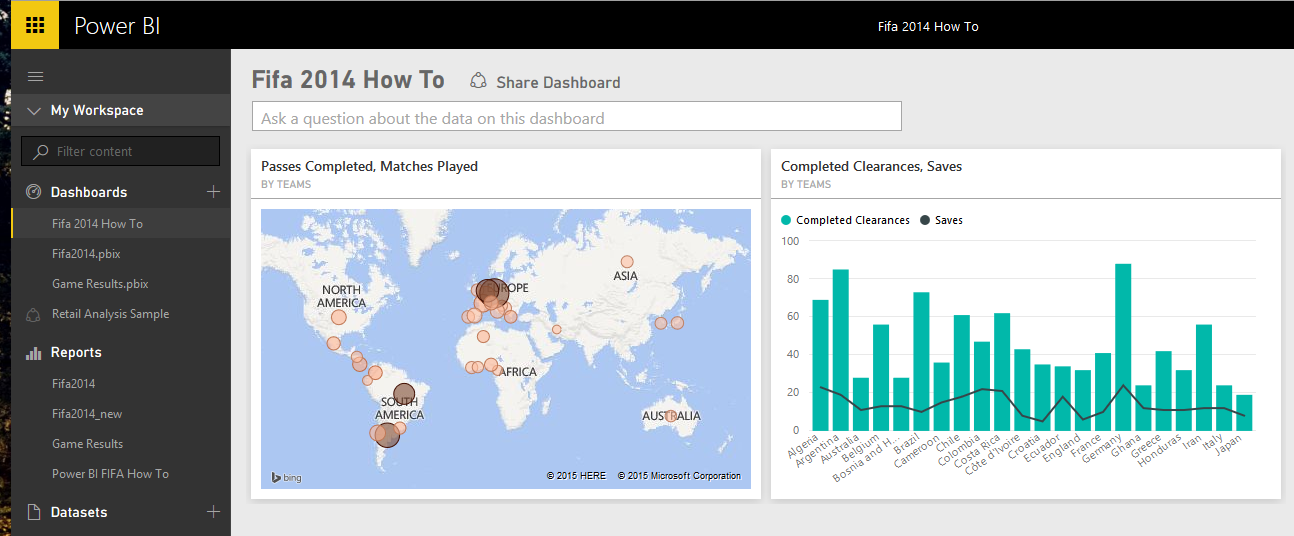
تبریک !!! داشبورد تحلیلی ما آماده شد . این داشبورد نهایی باید شبیه به شکل زیر باشد :
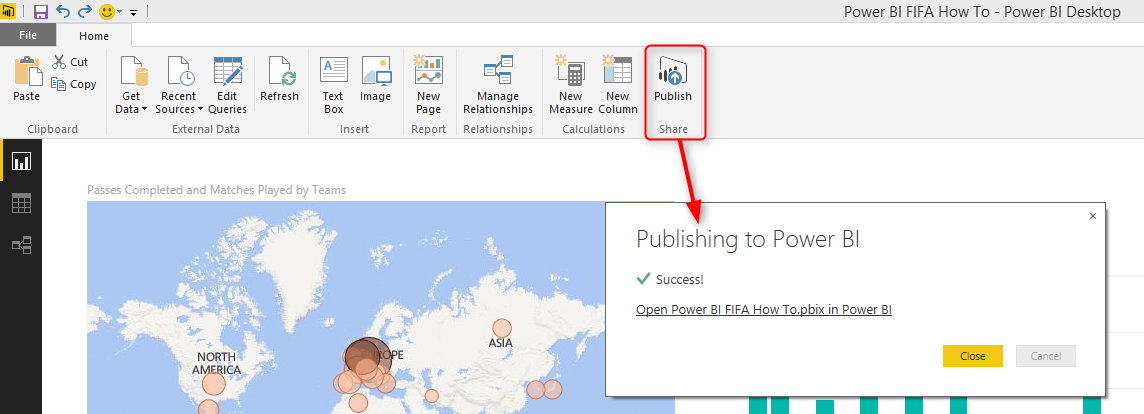
انتشار کار
بعد از اتمام تحلیل و ساخت نمودارهای مورد نیاز، می توانیم آنرا روی سایت Power BI منتشر کنیم تا در اختیار بقیه هم قرار گیرد.برای این منظور در سایت Power BI یک اکانت که مجانی نیز هست ایجاد کنید.حال روی گزینه انتشار کلیک کنید تا این داشبورد و نمودارها به وب سایت نرم افزار منتقل شود. به همین راحتی !
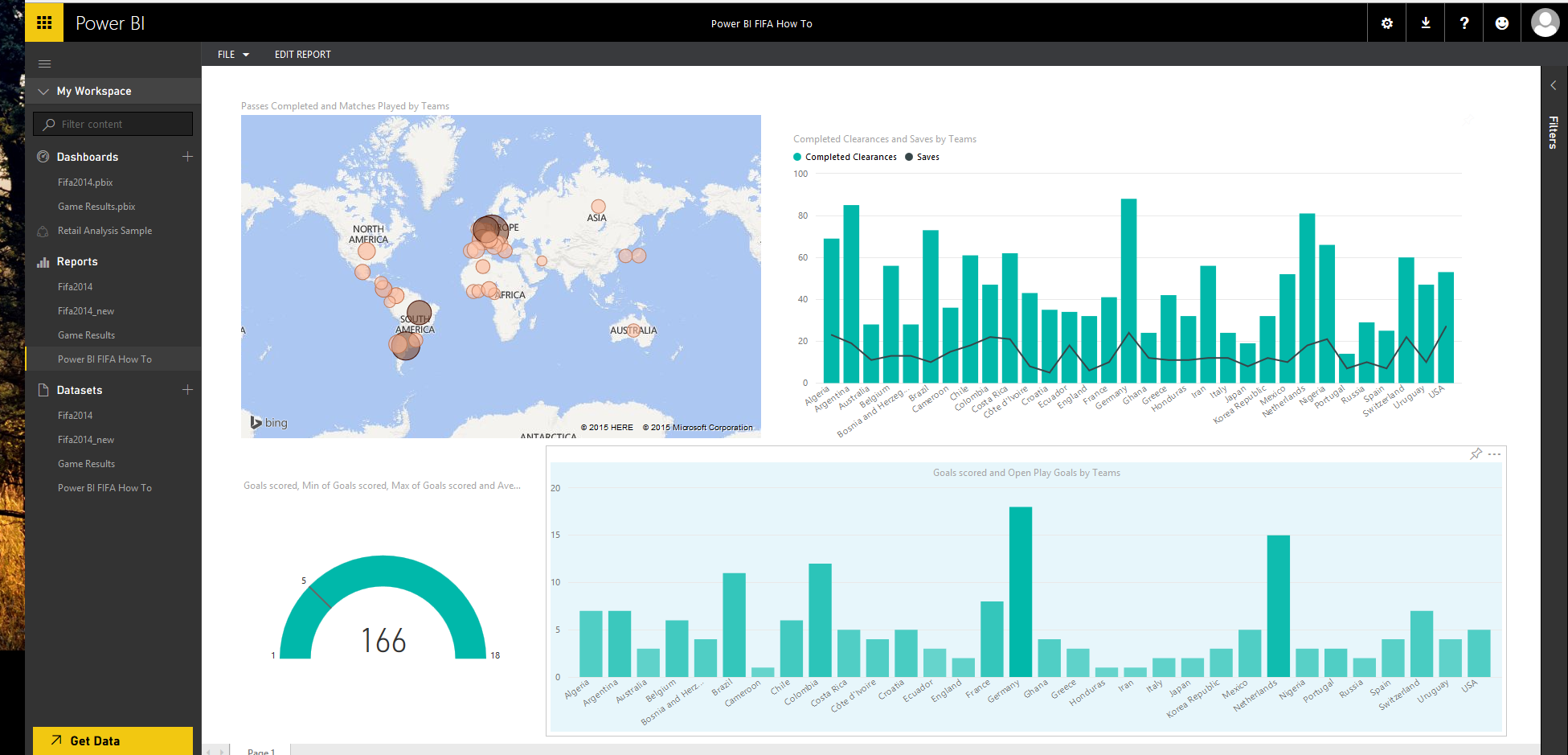
بعد از اتمام انتشار ، وارد حساب کاربری خود شده و گزارش ایجاد شده را باز کنید :
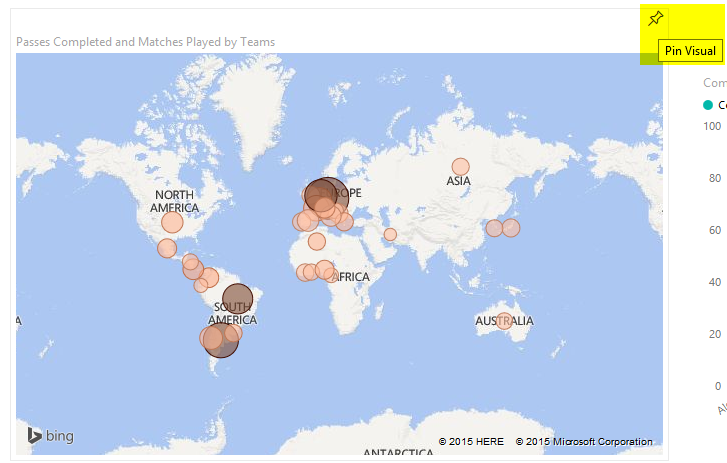
در این بخش شما می توانید بخشی از این نمودارها را به عنوان یک داشبورد جدید برای خودتان انتخاب کنید :
این نمودارهایی که آنها را به داشبورد جدید نسبت می دهید، به عنوان یک گزارش جداگانه در بخش داشبوردهای شما قرار میگیرند :
منتظر آموزشهای بعدی ما باشید …..