
ساخت وب سایت شخصی با پایتون، پلیکان و گیتهاب – بخش دوم
در ادامه مقاله آموزشی ساخت وبسایت شخصی با پایتون، پلیکان و گیتهاب، در این نوشتار به تکمیل بحث و نحوه استفاده از پلیکان، قالبها، پلاگینها و نحوه انتشار آن در اینترنت میپردازیم.
آماده سازی محیط کار
اگر آخرین مرحله بخش اول این مقاله را انجام داده باشید، یعنی آن سایت استاتیک تک صفحهای را برای وب سایت خود بارگذاری کرده باشید، نیاز داریم که این تغییرات را برگردانیم به اولین مرحله از ایجاد سایت که در آن تنها یک فایل readme.md وجود داشت و پوشه سایت ما شبیه این بود :

سادهترین راهحل برای برگشت به این حالت این است که تمام فایلهای اضافه را پاک کنید و بعد از این کار، تغییرات را به گیت اعلام کرده و آنها را کامیت کنید. (همان سه دستور قبلی که بعد از افزودن فایلها یا تغییرات در آنها، اجرا میکردیم). راه دوم و حرفهای تر این است که از امکانات خود گیت استفاده کنید و تاریخچه گیت را به اولین کامیت که با ساختن ریپوزیتوری و ایجاد فایل readme.md ساخته شده است، برگردانید.
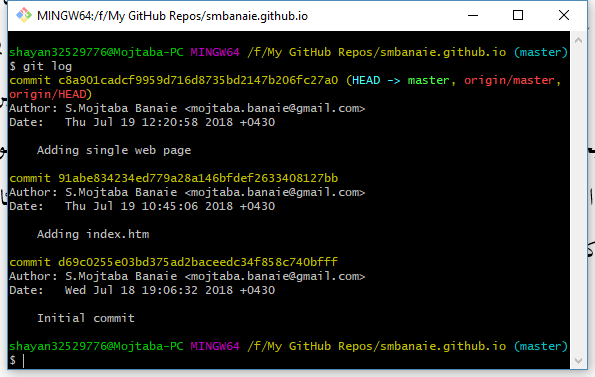
برای این منظور از دستور reset استفاده میکنیم که اگر علاقهمند به حرفهای شدن در گیت باشید، میتوانید مستندات آنرا در اینترنت مشاهده کنید. با استفاده از دستور git log ابتدا شناسه اولین کامیت را (ترکیبی طولانی از حرف و عدد) به دست آورید (شکل زیر) و سپس با دستور git reset COMMIT-ID –hard ، کل مخزن کد را به کامیت شماره COMMIT-ID برگردانید.
آخرین کاری که در این مرحله و برای آمادهسازی سایت انجام میدهیم، افزودن پوشه output به فایل gitignore. است. این پوشه حاوی خروجی نهایی سایت ماست و نیاز به ذخیره آن در گیت نداریم چون هر زمان به تولید آن نیاز داشتیم، با انجام چند دستور ساده، پلیکان آنرا برای ما تولید خواهد کرد. بنابراین فایل gitignore. را باز کنید و در آخرین خط آن نام پوشهای که میخواهید، گیت از آن همیشه صرفنظر کند به صورت زیر وارد کنید و فایل را ذخیره نمایید :
output/
نصب پلیکان و ساخت پوشههای اصلی سایت
برای کار با پلیکان و تولید محتوای سایت به صورت حرفهایتر، نیاز به نصب پایتون ۳ خواهید داشت که توصیه میکنم از توزیع آناکوندا که یک توزیع حرفهای پایتون شامل بسیاری از کتابخانههای مورد نیاز پایتون و ابزارهای گرافیکی مدیریت آنهاست، استفاده کنید.
دقت کنید که برای تولید محتوی و انتشار آنها بر روی اینترنت، نیازی به کدنویسی پایتون ندارید و تنها کافیست اصول نوشتن و تولید محتوی در پلیکان و تولید خروجی HTML به کمک آنرا یاد داشته باشید. برای این منظور همان نسخه معمولی پایتون ۳ هم کافیست اما اگر هدف شما فعالیت در حوزه علم داده است از توزیع حرفهای آناکوندا استفاده کنید.
درون پوشه سایت که اسمی مشابه با smbanaie.github.io باید داشته باشد، روی فضای خالی کلیک راست کرده، خط فرمان گیت را باز کنید (git bash here). توضیح اینکه با خط فرمان ویندوز هم میتوانید کار کنید و بعد از انتقال به این پوشه، دستورات زیر را در آن اجرا کنید اما کار با خط فرمان گیت را چون شبیه لینوکس عمل میکند، به شخصه ترجیح میدهم.
با خط فرمان میخواهیم پلیکان و سایر کتابخانههای پایتون لازم را نصب کنیم . ابتدا نسخه پایتون خود را چک کنید که حتما ۳.۵ به بالا باشد :
python --version
اگر نبود، نسخه مناسب را نصب کنید.
سپس پلیکان و سایر کتابخانه لازم دیگر را با دستور زیر نصب کنید :
pip install pelican markdown ghp-import invoke pysvg pygments requests webassets
مدتی طول میکشد که کتابخانههای لازم دانلود و نصب شود.
حال دستور زیر را اجرا کنید تا پوشههای اصلی سایت و تنظیمات پایه آن ایجاد شود :
pelican-quickstart
تنظیمات را مشابه زیر انجام دهید (میتوانید با زدن کلید Enter پیش فرضهای نمایش دادهشده را بپذیرید) :
بخشهای پررنگتر را حتماً به همین صورت وارد کنید یعنی کلید y یا yes را برای آنها بزنید.
> Where do you want to create your new web site? [.] ./
> What will be the title of this web site? Mojtaba Banaie Weblog
> Who will be the author of this web site? S.Motaba Banaie
> What will be the default language of this web site? [English]
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n) y
> How many articles per page do you want? [10]
> What is your time zone? [Europe/Paris] Asia/Tehran
> Do you want to generate a task.py/Makefile to automate generation and publishing? (Y/n) Y
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) n
> Do you want to upload your website using FTP? (y/N) n
> Do you want to upload your website using SSH? (y/N) n
> Do you want to upload your website using Dropbox? (y/N) n
> Do you want to upload your website using S3? (y/N) n
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
> Do you want to upload your website using GitHub Pages? (y/N) y
> Is this your personal page (username.github.io)? (y/N) y
Done. Your new project is available at F:\My GitHub Repos\smbanaie.github.io
اکنون پوشه سایت باید شبیه به این تصویر به نظر برسد :

قبل از ساختن اولین صفحه وب سایت و ارسال آن بر روی اینترنت، پوشهها و فایلهای اصلی پلیکان را با هم مرور میکنیم.
پوشه content همانطور که از اسمش مشخص است، حاوی مطالب و فایلهای اصلی و محتویات سایت ما خواهد بود. پوشه output، با هر تغییری که در سایت میدهیم و مطلب جدیدی به آن اضافه میکنیم، حاوی نسخه جدید سایت خواهد بود. این پوشه همان چیزی است که کاربران سایت خواهند دید.
فایل pelicanconf.py حاوی تنظیمات اصلی سایت است و اگر به محتوای آن نگاهی بیندازید، بسیاری از اطلاعاتی که با اجرای pelican-quickstart از شما پرسیده شده است را در آن مشاهده خواهید کرد و در صورت نیاز میتوانید آنها را تغییر دهید. در ادامه به این فایل، فایل تنظیمات خواهیم گفت. سایر فایلها و پوشهها را در ادامه آموزش و درصورت نیاز، بررسی خواهیم کرد.
آشنایی با مارکداون و ساخت اولین صفحه سایت
روش سنتی نوشتن مطلب و تولید محتوی در اینترنت، استفاده از قالب استاندارد HTML است. از آنجا که خیلی از کاربران با این استاندارد آشنا نیستند، هنگام تایپ مطلب به صورت آنلاین، از ویرایشگرهایی در صفحات وب استفاده میکنیم که این ویرایشگرها هم به صورت سنتی برای صفحهآرایی نیازمند این هستند که کاربر بخشی از متن که مثلاً میخواهد پررنگ شود را انتخاب کرده، دکمهای را بزند تا تغییرات اعمال شود. اما میتوان این فرآیند نوشتن مطالب و صفحهآرایی آن را همزمان با تایپ کردن و بدون استفاده از دکمههای کمکی انجام داد. فرض کنید قصد پررنگ کردن یک کلمه را دارید، میتوانید استانداردی تعریف کنید که دو طرف آن علامت ** را همزمان با خود کلمه تایپ کنید و سرآخر، این تغییرات به قالب استاندارد HTML تبدیل شده،به کاربر نمایش داده شود. این همان فلسفه تولید قالب بسیار ساده و کاربردیتری است که برای نوشتن مطالب و تولید محتوی در چند سال گذشته با نام مارکداون رایج شده است.
این قالب که ساده شده HTML برای تولید مطلب است، قالب اصلی تولید محتوی در پلیکان به عنوان یک سیستم مدیریت محتوای استاتیک است. برای آشنایی با مارکداون این مطلب تکصفحهای را مطالعه کنید. برای کار عملی با این قالب و نوشتن یک مطلب آموزشی با آن، سری به وب سایت ویرایشگر فارسی مرتب بزنید و متن موجود در آن را که حالت آموزشی هم دارد را ویرایش کرده و همان لحظه خروجی آنرا مشاهده کنید. بعداً به این ویرایشگر مرتب بر میگردیم و برای تولید محتوای فارسی از آن استفاده خواهیم کرد. مطلب نوشته شده را کپی کرده و در فایل زیر بعد از پارامترهای مقاله، بچسبانید.
فایلهای مارکداون با پسوند .md ذخیره میشوند. درون پوشه content یک فایل با نام hello-world.md با محتوای زیر ایجاد کنید (آنرا با فرمت utf-8 حتما ذخیره کنید):
Title: سرآغاز یک راه
Date: 2018-07-23
Modified: 2018-07-23
Category: اخبار
Tags: متفرقه, شخصی
Slug: My-first-post
Authors: Mojtaba-Banaie
Summary: اولین مطلب آزمایشی سایت
## سلام دنیا
اولین محتوایی که برای مقاصد آزمایشی بر روی [سایت](http://bigdata.ir) ، منتشر شده است . همواره به یاد داشته باشید :
> همواره سخت ترین کارها با **اولین گام ** شروع میشود.
تولید محتوای مفید و دست اول در وب ، کاری است که همه ما در *اوقات فراغت* خود میتوانیم انجام دهیم.
میتوانید این فایل را از این آدرس دانلود کنید.
به خط فرمان گیت برگردید و دستور زیر را در پوشه اصلی سایت، برای تولید خروجی در پنجره ظاهر شده وارد کنید :
pelican
کمی صبر کنید تا خروجی اچتیامال در پوشه output که پوشه پیشفرض برای تولید محتوی است، تولید شده و پیغامی مشابه با زیر نمایش داده شود:
Done: Processed 1 article, 0 drafts, 0 pages and 0 hidden pages in 1.85 seconds.
همانطور که میبینید پیغام فوق اعلام میکند که یک مقاله ، ۰ پیشنویس، ۰ صفحه و ۰ صفحه مخفی پردازش شده است.
پوشه خروجی یا همان output را باز کنید. محتوای زیر را در آن مشاهده خواهید کرد :
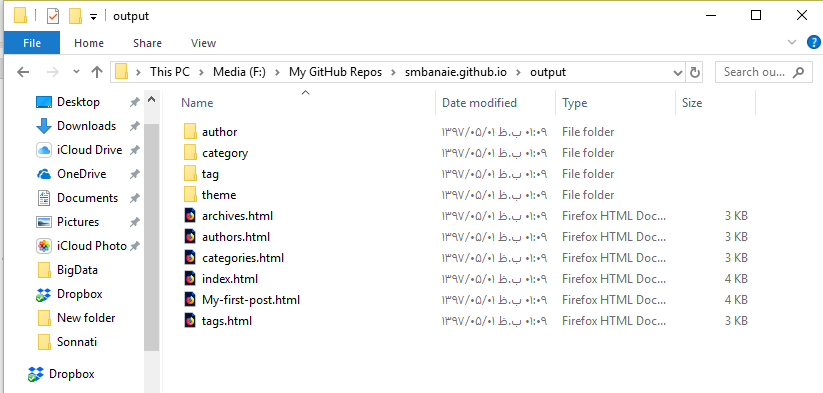
اگر دقت کنید علاوه بر index.html که نمایش دهنده صفحه اصلی سایت ماست، یک فایل اچتیامال برای نمایش مطالب بر حسب نویسندگان (authors.html)، گروهبندیها(categories.html)، برچسبها(tags.html) و آرشیو مطالب (archives.html) ایجاد شده است که مطالب را درون پوشههایی با همین نامها، آدرسدهی کرده و به کاربر نمایش میدهند. مثلاً اگر پوشه برچسبها (tag) را باز کنید، دو فایل mtfrqh.html (تبدیل حروف فارسی به لاتین کلمه متفرقه – ترنسلیتریت) و shkhsy.html (ترنسلیتریت کلمه شخصی) را مشاهده میکنید. این دو فایل، هر یک حاوی مطالبی است که برچسب متفرقه و شخصی داشتهاند و فهرست آنها در فایل tags.html قرار دارد.
دقت کنید که هنگام تولید اولین مطلب و محتوی، پارامتر slug نام فایل مرتبط با آن مطلب را تعیین میکند (البته میتوانید نحوه نامگذاری را در فایل تنظیمات پلیکان به دلخواه تغییر دهید) که اکنون فایل My-first-post.html بر همین اساس در این پوشه تولید شده است و پارامتر tags و Category و Authors هم برچسبها، گروهبندیها و نویسندگان مطلب را مشخص میکند که بسته به این پارامترها که ابتدای هر فایل و مطلب مینویسیم، خروجی مناسب تولید خواهد شد.
مشاهده خروجی و ارسال آن به گیتهاب
بعد از نوشتن اولین مطلب و تولید خروجی اچتیامال، ابتدا در حالت محلی باید خروجی سایت خود را مشاهده کنیم. برای این منظور از یک وب سرور ساده در پایتون استفاده میکنیم که فایلهای موجود در یک پوشه را مشابه با سرور برایمان شبیهسازی میکند. وارد پوشه output میشویم و این وبسرور را اجرا میکنیم :
cd output
python -m http.server
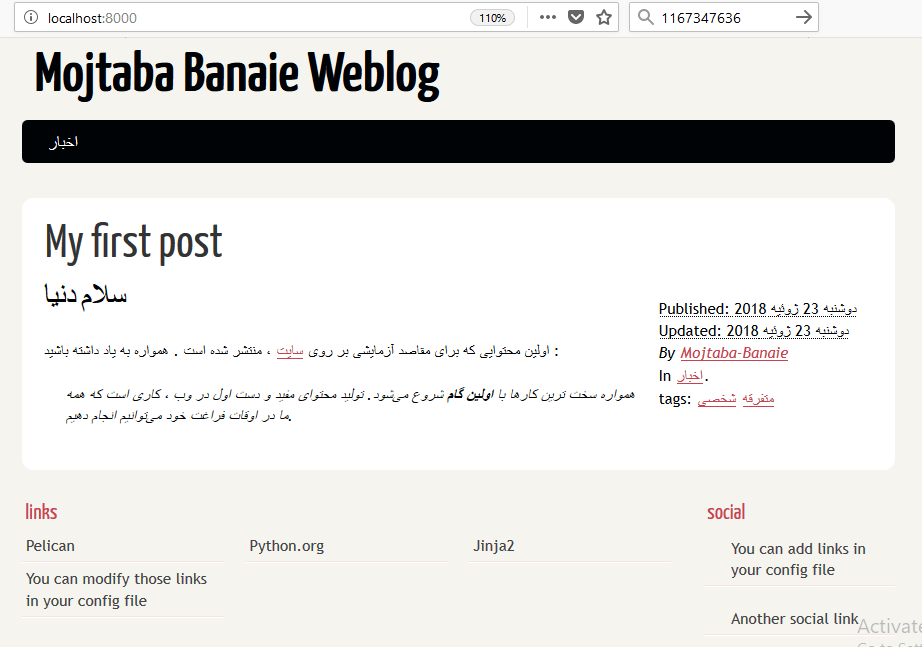
حال کافیست آدرس http://localhost:8000 را در مرورگر باز کنید (احتمالاً ویندوز پنجرهای باز کند و از شما سوال کند که اجازه اجرای یک سرویس پشت پورت ۸۰۰۰ را بدهد یا نه که گزینه Allow را انتخاب کنید). اولین نسخه از سایت خود را مشابه با تصویر زیر باید مشاهده کنید :
نکته : راه ساده تر صدا مشاهده خروجی سایت استفاده از تابع serve است که درون پوشه اصلی پلیکان و در خط فرمان بعد از تولید خروجی، می توانید آنرا به صورت زیر فراخوانی کنید :
invoke serve
تا بحال همه چیز به خوبی پیش رفته است و میتوانیم این مطلب و نسخه جدید سایت را به گیتهاب ارسال کنیم. اما بهتر است چندین تغییر کوچک در سایت خود بدهیم. یکی اینکه عنوان سایت که خط اول به زبان لاتین نوشته شده است یعنی Mojtaba Banaie Weblog به فارسی نوشته شود. نیز در پایین صفحه در قسمت links و Social دادههای مناسب باید نوشته شود. این تنظیمات در فایل pelicanconf.py قرار گرفته است. کافیست این فایل را باز کنید پارامتر SITENAME را برابر«سایت شخصی سید مجتبی بنائی» و پارامتر LINKS و SOCIAL را هم با دادههای مناسب پر کنید مشابه زیر :

دومین تغییری که باید به سایت بدهیم، تغییر عنوان مطلب اول سایت از My First Post به سرآغاز یک راه است. این تغییر را در مطلب نوشته شده باید بدهیم یعنی باید فایل hello-world.md در پوشه content را باز کنیم و خط اول آن را اینگونه به روزرسانی کنیم :
Title: سرآغاز یک راه
بعد از انجام این کار، فایلهای تغییر کرده را ذخیره کنید.
حال مجدد باید خروجی اچ تی ام ال سایت را تولید کنیم. در خط فرمان،کلید Ctrl+C (کنترل+C) را بزنید تا وب سرور متوقف شود. سپس به پوشه اصلی بروید و مجدداً دستور pelican برای تولید خروجی را اجرا کرده با دستور invoke serve خروجی را مشاهده کنید:
cd ..
pelican
invoke serve
افزودن تصویر به مطالب :
قبل از گرفتن خروجی نهایی، بهتر است فرآیند افزودن تصویر به مطالب را هم فرابگیریم که روند سر راست و سادهای هم هست. ابتدا یک پوشه درون content به نام images یا هر نام دلخواه دیگری ایجاد کنید که میزبان تصاویر شما باشد. برای جلوگیری از شلوغ شدن این پوشه، ما یک زیرپوشه برای سال ۹۷ و یک زیرپوشه با نام ۵ درون سال ۹۷ برای ماه مرداد در این پوشه اصلی ایجاد میکنیم. فرض کنید تصویر start.jpg در این آدرس یعنی content\images\1397\5\start.jpg وجود دارد.
فایل pelicanconf.py را باز کنید و به پلیکان اعلام کنید که پوشه استاتیکی به نام images درون پوشه محتوی وجود دارد که هنگام آدرسدهی فایلهای تصویر از آن استفاده خواهید کرد. منظور از پوشههای استاتیک پوشههایی است که حاوی فایلهای ثابت و غیرمتغیر سایت خواهد بود و عیناً در خروجی سایت ظاهر خواهند شد. این پوشهها میتوانند مثلاً تصاویر، فیلمها، پیدیاف ها و مانند آن باشند. این خط را به این فایل اضافه کنید :
STATIC_PATHS = ['images']
و اگر قصد ذخیره و آدرسدهی فایلهای PDF را هم داشته باشیم، این خط به صورت زیر در خواهد آمد :
STATIC_PATHS = ['images','pdfs']
اکنون برای آدرسدهی تصاویر درون متن، از گرامر زیر استفاده میکنیم :

علامت تعجب برای اعلام آدرس دهی فایل، توضیح فایل که هنگام لود نشدن عکس به کاربر نمایش داده میشود، درون کروشه، و آدرس عکس هم درون پرانتز که یک آدرسدهی دوقسمتی است ابتدا کلمه کلیدی filename درون آکولاد و سپس آدرس نسبی فایل با شروع از پوشه images قرار میگیرد.
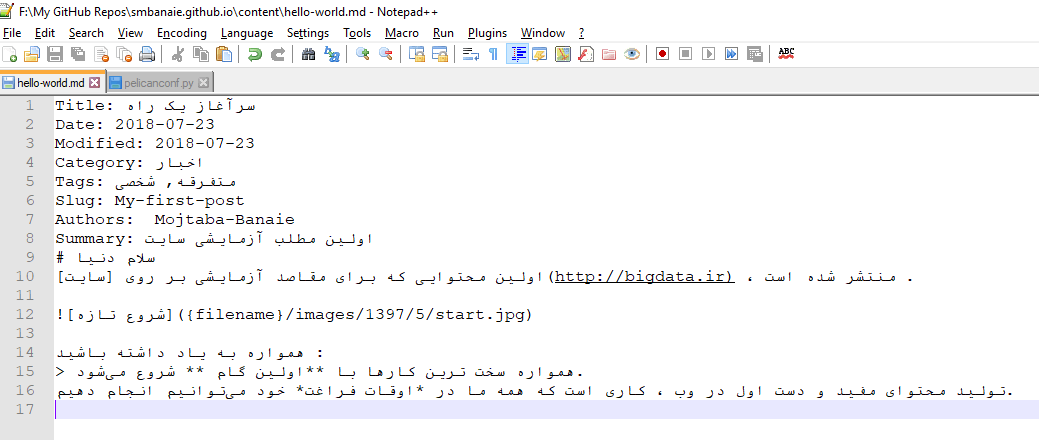
متن نهایی اولین مطلب سایت ما اکنون به این صورت خواهد بود :
اکنون میتوانیم مجدداً خروجی سایت را تولید کنیم. وب سرور را متوقف کرده (کنترل + C)، وارد پوشه اصلی سایت میشویم و دستور pelican را دوباره اجرا میکنیم تا محتوای سایت ما مجدداً تولید شود. سپس به پوشه output رفته و وب سرور را اجرا میکنیم. سایت را در مرورگر مجدداً باز کرده یا آنرا رفرش کنید. اکنون باید سایت شما شبیه زیر باشد :
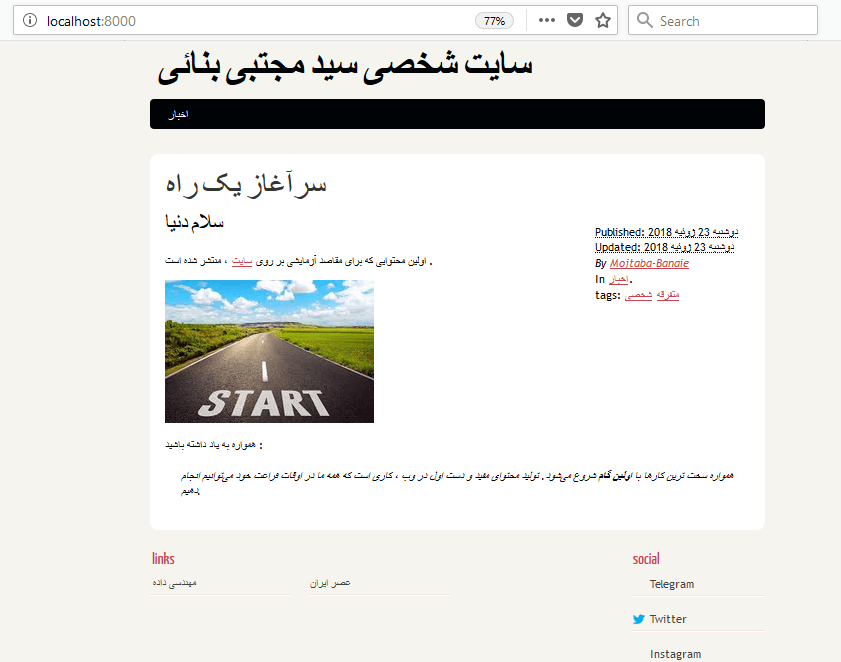
درمورد فارسی سازی و راستچین کردن مطالب کمی صبر کنید. در قسمت نصب قالب، بعد از آموزش نصب قالب بر روی سایت، نحوه فارسی سازی آنرا هم توضیح خواهیم داد.
اکنون وب سرور را متوقف کرده (کنترل + C) و وارد پوشه اصلی سایت میشویم. تمام تغییرات را کامیت میکنیم:
cd ..
git add .
git commit -m "My First Publication"
git push
برای ارسال مطالب به ریپوزیتوری اصلی و قرار گرفتن آنها در اینترنت از کتابخانه invoke پایتون که در بالا آنرا نصب کردهایم، استفاده خواهیم کرد.
اگر به پوشه اصلی سایت نگاه کنید فایلی به نام tasks.py مشاهده میکنید. این فایل حاوی تنظیمات و توابعی است که کتابخانه invoke با آنها کار خواهد کرد. از این به بعد با این کتابخانه برای تولید خروجی، پیشنمایش سایت، ارسال خروجی به گیتهاب و مانند آن استفاده خواهیم کرد. مثلاً دستور
invoke build
همان خروجی مطالب را برای شما تولید خواهد کرد یا دستور زیر هم خروجی را تولید کرده، هم آنرا روی پورت ۸۰۰۰ بالا میآورد که بتوانید سریعاً خروجی را مشاهده کنید:
invoke reserve
که با همان کنترل+C میتوانید از آن خارج شوید.
مهمترین دستور invoke که از آن به کرات استفاده خواهیم کرد، دستور ghpages آن است که محتوای پوشه output را به ریپوزیتوری اصلی منتقل کرده و به صورت خودکار سایت ما به روزرسانی میشود(همانطور که در بالا توضیح داده شده است، نام این تابع ممکن است حاوی خط زیر باشد که آنرا به صورت دستی حذف کنید تا هنگام فراخوانی خطایی تولید نشود). در خط فرمان گیت اول مطمئن شوید که در پوشه اصلی سایت هستید و مطالب جدید را هم وارد کرده و آنها را کامیت کردهاید. دستور زیر به صورت خودکار خروجی جدید را تولید کرده و آنها را به اینترنت منتقل خواهد کرد :
invoke ghpages
در حین اجرا، نام کاربری و پسورد گیتهاب شما پرسیده خواهد شد. بعد از اتمام کار، کافیست وبسایت خود را که آدرسی مشابه زیر دارد در مرورگر بازکنید و تغییرات را به صورت آنلاین مشاهده کنید :
smbanaie.github.io
افزودن صفحات ثابت و ساختاردهی به مطالب
برای نمایش محتوای ثابتی که باید دمدست کاربر باشد مانند صفحات درباره ما، تماس با ما و مانند آن، مفهومی در پلیکان داریم با نام page که این صفحات اولویت بالاتری نسبت به محتوای معمولی سایت دارند و معمولاً در منوهای اصلی سایت و دردسترس کاربر قرار میگیرند.
برای تولید صفحات ثابت یا همان page ها، کافی است که پوشهای به نام pages در پوشه content ایجاد کنیم و صفحات ثابت سایت را مشابه با سایر مطالب در این پوشه قرار دهیم (البته میتوانید از هر پوشه دیگری هم استفاده کنید فقط باید مقدار پیشفرض پارامتر PAGE_PATHS = [‘pages’] را تغییر دهید). حال با تولید مجدد خروجی سایت، این صفحات به صورت خودکار در منوی سایت ظاهر خواهند شد.
نمایش صفحات ثابت در منوی اصلی سایت ، بسته به تنظیم زیر دارد که در فایل تنظیمات پلیکان میتوانید مقدار پیشفرض آنرا تغییر دهید.
DISPLAY_PAGES_ON_MENU = True
با توجه به اینکه در دراز مدت، حجم مطالب سایت زیاد خواهد شد، بهتر است ساختار مناسبی به پوشه content بدهیم. میتوانیم درون این پوشه یک پوشه blog ایجاد کرده و درون این پوشه، به ازای هر گروه از مطالب یک پوشه ایجاد کنیم و سپس درون هر گروه، سال تولید مطلب را به عنوان یک پوشه ایجاد کرده و نهایتاً مطالب را درون این زیرپوشهها بنویسیم. مثلاً اگر مطلبی ورزشی در سال ۱۳۹۷ بخواهیم بنویسیم با نام sport.md این فایل در آدرس زیر ذخیره خواهد شد :
content/blog/sports/1397/sport.md
حال برای تولید خروجی بر همین مبنا باید پارامترهای زیر را در pelicanconf.py اضافه کنیم :
ARTICLE_PATHS = ['blog']
ARTICLE_SAVE_AS = 'blog/{category}/{date:%Y}/{slug}.html'
ARTICLE_URL = 'blog/{category}/{date:%Y}/{slug}.html'
پارامتر اول، آدرس پوشه مقالات سایت را درون پوشه content مشخص میکند و دو پارامتر دوم، نحوه تولید خروجی مقالات و سازماندهی آنها را تعیین میکند. در این مثال به پلیکان گفتهایم که مقالات را در پوشه blog سپس زیر پوشه سال سپس زیرپوشه ماه و نهایتاً نام مقاله با پسوند html تولید کند و به کاربر نمایش دهد.
نکته : سالی که در خروجی مشاهده میکنیم، سال میلادی خواهد بود و اگر قصد ایجاد زیر پوشهای برای هر ماه هم داشته باشید میتوانید از قالب زیر استفاده کنید :
ARTICLE_SAVE_AS = 'blog/{date:%Y}/{date:%m}/{slug}.html'
ARTICLE_URL = 'blog/{date:%Y}/{date:%m}/{slug}.html'
افزودن قالب و تنظیمات مرتبط با آن
برای افزودن یک قالب جدید به سایت، کافیست به سایت قالبهای پلیکان مراجعه کنیم و با مشاهده پیشنمایش قالبهای مختلف، یک قالب مناسب را انتخاب میکنیم و سپس با مراجعه به مخزن قالبهای پلیکان به این آدرس، قالب مورد نظر را دانلود میکنیم و سپس آنرا با یک نام مناسب درون پوشه اصلی سایت ذخیره میکنیم.
نکته : با کلیک بر روی بیشتر قالبها، امکان دانلود تکی آنها وجود دارد. اگر قالبی را از مخزن اصلی قالبهای پلیکان انتخاب کردید و امکان دانلود آن وجود نداشت، باید کل مخزن قالبهای پلیکان را دانلود کنید و سپس پوشه قالب مورد نظر خود را از بین قالبهای دانلود شده انتخاب کرده و آنرا به پوشه اصلی سایت منتقل کنید.
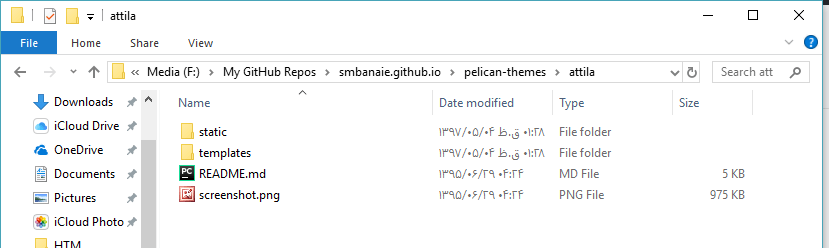
برای این آموزش، قالب attila را از این آدرس، دانلود کرده و سپس پوشهای به نام pelican-themes در پوشه اصلی سایت ایجاد کرده، قالب آتیلا را به این پوشه منتقل کنید (نام قالب بعد از دانلود یک نام طولانی است که آنرا به attila تغییر دهید و سپس به پوشه pelican-themes انتقال دهید).
درون تصویر زیر به آدرسی که فایلهای قالب قرار گرفتهاند، دقت کنید:
برای استفاده از این قالب، ابتدا باید آنرا نصب کرده و به لیست قالبهای پلیکان اضافه کنیم. در خط فرمان گیت، این دستور را اجرا کنید :
pelican-themes -i pelican-themes/attila/
حال میتوانید با دستور زیر لیست قالبهای نصب شده پلیکان بر روی سیستم خود را مشاهده کنید :
pelican-themes -l
در مرحله بعد باید آدرس این قالب را در فایل تنظیمات پلیکان وارد کنیم و نیز چندین پارامتر مرتبط با این قالب را هم مقداردهی کنیم.
فایل pelicanconf.py را باز کرده، نام قالب مورد استفاده را در آن وارد کنید:
THEME = 'pelican-themes/attila'
هر قالبی تنظیمات خاص خود را هم دارد که معمولاً در فایل readme.md قالب نحوه استفاده از آنها توضیح داده شده است. برای قالب آتیلا این تنظیمات را انتهای فایل pelicanconf.py وارد کنید :
COLOR_SCHEME_CSS = 'github.css'
### Theme specific settings
HEADER_COVER = '/images/static/header.jpg'
AUTHORS_BIO = {
"smbanaie": {
"name": "S.Mojtaba Banaie",
"cover": "/images/static/header.jpg",
"image": "assets/images/avatar.png",
"website": "http://banaie.ir",
"linkedin": "unavailable",
"github": "smbanaie",
"location": "iran",
"bio": "This is the place for a small biography "
}
}
همانطور که میبینید فایل تصویری با نام header.jpg را در پوشه /images/static ذخیره کردهایم و آدرس آنها را در تنظیمات قالب برای هدر صفحه اصلی وارد کردهایم.
اکنون دستور fab reserve را اجرا کنید تا خروجی سایت را با قالب جدید مشاهده کنید :
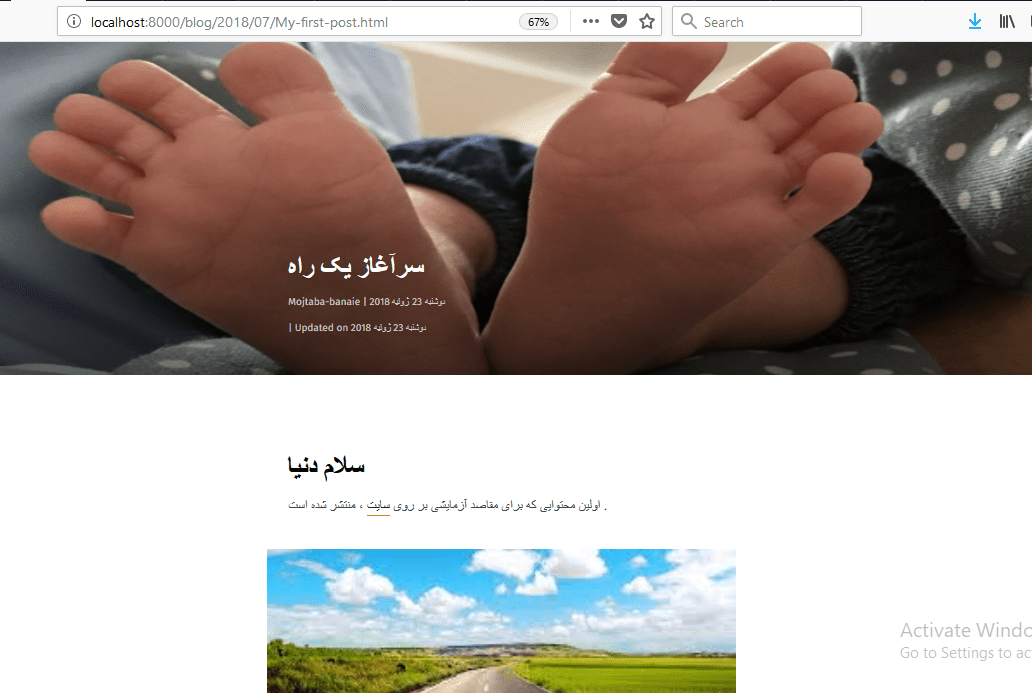
اکنون میتوانیم تنظیمات قالب و راستچین کردن آنها را انجام دهیم. پوشه attila را باز کرده درون پوشه templates، فایل base.html را باز کنید. این فایل که قالب اصلی صفحات سایت را تعیین میکند با زبان نگارشی موتور تولید قالب معروف جینجا (jinja) تولید شده است. در این زبان ساده تولید قالب، مفاهیمی مثل ارثبری و بلوکبندی صفحات را داریم و با دستورات شرطی و حلقه مانند سایر زبانهای برنامهنویسی، میتوانیم به صورت دینامیک، فایلهای HTML خود را تولید کنیم.
کافی است کمی به این فایل با دقت نگاه کنید. فایل index.html که از فایل base با دستور extends ارثبری میکند، قالب صفحه اصلی سایت و دو فایل loop.html و navigation.html درون پوشه partials قالب نمایش مطالب و نیز منوی کناری را مشخص میکنند که اگر با HTML آشنایی دارید میتوانید آنها را بسته به نیاز، سفارشی کنید.
ابتدا چند فونت فارسی را در پوشه pelican-themes\attila\static\fonts کپی میکنیم. من از فونتهای ایرانسنس که قبلاً تهیه کردهام، استفاده خواهم کرد. سپس فایل fontiran.css را در آدرس pelican-themes\attila\static\css ایجاد کرده، نام فونت و آدرس آنها را به شرح ذیل در آن قرار میدهم (طبق راهنمای ایرانسنس عمل کردهام) :
@font-face {
font-family: IRANSans;
font-style: normal;
font-weight: 900;
src: url('../fonts/eot/IRANSansWeb_Black.eot');
src: url('../fonts/eot/IRANSansWeb_Black.eot?#iefix') format('embedded-opentype'), /* IE6-8 */
url('../fonts/woff2/IRANSansWeb_Black.woff2') format('woff2'), /* FF39+,Chrome36+, Opera24+*/
url('../fonts/woff/IRANSansWeb_Black.woff') format('woff'), /* FF3.6+, IE9, Chrome6+, Saf5.1+*/
url('../fonts/ttf/IRANSansWeb_Black.ttf') format('truetype');
}
@font-face {
font-family: IRANSans;
font-style: normal;
font-weight: bold;
src: url('../fonts/eot/IRANSansWeb_Bold.eot');
src: url('../fonts/eot/IRANSansWeb_Bold.eot?#iefix') format('embedded-opentype'), /* IE6-8 */
url('../fonts/woff2/IRANSansWeb_Bold.woff2') format('woff2'), /* FF39+,Chrome36+, Opera24+*/
url('../fonts/woff/IRANSansWeb_Bold.woff') format('woff'), /* FF3.6+, IE9, Chrome6+, Saf5.1+*/
url('../fonts/ttf/IRANSansWeb_Bold.ttf') format('truetype');
}
@font-face {
font-family: IRANSans;
font-style: normal;
font-weight: 500;
src: url('../fonts/eot/IRANSansWeb_Medium.eot');
src: url('../fonts/eot/IRANSansWeb_Medium.eot?#iefix') format('embedded-opentype'), /* IE6-8 */
url('../fonts/woff2/IRANSansWeb_Medium.woff2') format('woff2'), /* FF39+,Chrome36+, Opera24+*/
url('../fonts/woff/IRANSansWeb_Medium.woff') format('woff'), /* FF3.6+, IE9, Chrome6+, Saf5.1+*/
url('../fonts/ttf/IRANSansWeb_Medium.ttf') format('truetype');
}
@font-face {
font-family: IRANSans;
font-style: normal;
font-weight: 300;
src: url('../fonts/eot/IRANSansWeb_Light.eot');
src: url('../fonts/eot/IRANSansWeb_Light.eot?#iefix') format('embedded-opentype'), /* IE6-8 */
url('../fonts/woff2/IRANSansWeb_Light.woff2') format('woff2'), /* FF39+,Chrome36+, Opera24+*/
url('../fonts/woff/IRANSansWeb_Light.woff') format('woff'), /* FF3.6+, IE9, Chrome6+, Saf5.1+*/
url('../fonts/ttf/IRANSansWeb_Light.ttf') format('truetype');
}
@font-face {
font-family: IRANSans;
font-style: normal;
font-weight: 200;
src: url('../fonts/eot/IRANSansWeb_UltraLight.eot');
src: url('../fonts/eot/IRANSansWeb_UltraLight.eot?#iefix') format('embedded-opentype'), /* IE6-8 */
url('../fonts/woff2/IRANSansWeb_UltraLight.woff2') format('woff2'), /* FF39+,Chrome36+, Opera24+*/
url('../fonts/woff/IRANSansWeb_UltraLight.woff') format('woff'), /* FF3.6+, IE9, Chrome6+, Saf5.1+*/
url('../fonts/ttf/IRANSansWeb_UltraLight.ttf') format('truetype');
}
@font-face {
font-family: IRANSans;
font-style: normal;
font-weight: normal;
src: url('../fonts/eot/IRANSansWeb.eot');
src: url('../fonts/eot/IRANSansWeb.eot?#iefix') format('embedded-opentype'), /* IE6-8 */
url('../fonts/woff2/IRANSansWeb.woff2') format('woff2'), /* FF39+,Chrome36+, Opera24+*/
url('../fonts/woff/IRANSansWeb.woff') format('woff'), /* FF3.6+, IE9, Chrome6+, Saf5.1+*/
url('../fonts/ttf/IRANSansWeb.ttf') format('truetype');
}
دقت کنید که پارامتر url آدرس دقیق هر نوع فونت که برای یک مرورگر خاص لازم خواهد بود را دربردارد. حال فایل style.css در همان پوشه را باز میکنیم و تغییرات زیر را در ابتدای آن اعمال میکنیم :
@import url(fontiran.css);
html {
-ms-text-size-adjust: 100%;
-webkit-text-size-adjust: 100%
}
body {
font-family: IRANSans !important;
font-weight: 300;
direction: rtl;
#background-color: #E2E2E2;
margin: 0;
}
h1, h2, h3, h4, h5, h6,input, textarea {
font-family: IRANSans !important;
}
h1 {
font-weight: bold;
}
در استایلهایی که به برچسب body در کد فوق اعمال شده است، کد direction:rtl کل صفحه را راستچین خواهد کرد. البته گاهی باید text-align:right یا float:right را به برخی عناصر صفحه اضافه کنیم تا همه چیز به درستی راست چین شود.
مجدداً دستور زیر را برای تولید مجدد خروجی و پیش نمایش سایت در خط فرمان اجرا میکنیم :
invoke reserve
اکنون در مرورگر و در آدرس http://localhost:8000 باید تغییرات فوق را مشاهده نمایید. هنوز قالب سایت نیاز به بهینهسازی دارد مثلاً فونت تیتر یک مقاله خیلی بزرگ است یا عکس هدر، بخش زیادی از صفحه را اشغال میکند، فونت برچسبها مناسب نیست و مسائلی از این دست که با بررسی و تغییر در فایل style.css قابل رفع خواهد بود.
فرض کنید در صفحه اول سایت میبینیم که تنها عنوان مقاله نمایش داده میشود و متن آن نمایش داده نمیشود. میخواهیم کاری کنیم که حداقل چند خط اول هر مقاله هم نمایش داده شود. اگر یادتان باشد، فایل loop.html داخل پوشه pelican-themes\attila\templates حاوی کد نمایش مقالات بود. این فایل را باز میکنیم و مشاهده میکنیم شرط زیر چک میکند اگر پارامتر SHOW_FULL_ARTICLE برابر True باشد، کل مقاله یعنی {{article.content}} نمایش داده شود و گرنه فقط خلاصه آن، دیده شود. خط زیر را در فایل تنظیمات اضافه میکنیم :
SHOW_FULL_ARTICLE=True
و سپس تنها ۱۵۰ کاراکتر اول یک مقاله را با دستور زیر به کاربر نشان میدهیم :
{{ article.content|striptags|truncate(150) }}
در کد فوق که به جای کد قبلی قرار گرفته است، بر روی محتوی فایل ابتدا فیلتر striptags برای حذف برچسبهای HTML اعمال میشود و سپس تابع truncate برای انتخاب ۱۵۰ کاراکتر اول، صدا زده میشود.
یا اگر بخواهیم به جای کلمه Tag در صفحه نمایش لیست مقالات آن برچسب، فارسی نوشته شود «برچسب» و یا به جای posts نوشته شود «تعداد مقالات» کافیست فایل tag.html را درون پوشه pelican-themes\attila\templates باز کرده، این کلمات را یافته و با معادل فارسی جایگزین کنیم.
مشابه با این تغییرات را به تدریج و بسته به نیاز خودتان، بر روی سایت اعمال خواهید کرد.
حال تغییرات را کامیت کرده و آنها را به اینترنت منتقل میکنیم :
git add .
git commit -m "adding Attila template"
invoke ghpages
بعد از چند دقیقه باید تغییرات را به صورت آنلاین مشاهده کنید. احیاناً اگر لازم شد کلید کنترل+F5 را بزنید تا کش مرورگر خالی شود و سایت از اول بارگذاری و نمایش داده شود.
توصیه : برای سایتهای رزومه و شخصی، قالب Resume هم قالب زیبا و سادهای است که به راحتی نصب میشود و مشابه فوق، فارسی سازی میشود. سایت شخصی خودم هم بر اساس قالب زیبای ماربل شکل گرفته است.
کار با پلاگینها در پلیکان
با توجه به اینکه سایتهای استاتیک، امکانات برنامهنویسی و سفارشیسازی را در اختیار ما قرار نمیدهند، به کمک پلاگینها هنگام تولید خروجی، امکانات لازم را تا حد امکان به سایت خود اضافه میکنیم. امکاناتی از قبیل تولید سایتمپ یا نقشه سایت، امکان تولید ابرکلمات از برچسبها، تولید تاریخ فارسی و مانند آن.
برخی امکانات مانند جستجو و ثبت نظرات و فرم تماس با ما نیاز به سایتهای واسط دارند که اطلاعات ما را ذخیره و یا پردازش کنند. پلاگینها این امکانات را هم در اختیار ما میگذارند.
روش کار با پلاگینها هم درست شبیه به نحوه نصب قالبهاست. کافی است سری به آدرس https://github.com/getpelican/pelican-plugins بزنید و با بررسی و مرور هر پلاگین، آن پلاگین را دانلود و در پوشهای مثلاً با نام pelican-plugins ذخیره کنید و تنظیمات آن را درون فایل تنظیمات پلیکان وارد کنید. نحوه دانلود هم مشابه با قبل است. کل پوشه پلاگینها را دانلود و در پوشهای ذخیره کنید و سپس هر پلاگینی که لازم دارید را به سایت اصلی خود منتقل کنید.
فرض کنید قصد تولید نقشهسایت را دارید. پلاگین sitemap را دانلود کنید و در پوشه pelican-plugins ذخیره کنید.
پوشه سایت مپ به صورت زیر باید در سایت شما قرار گرفته باشد :
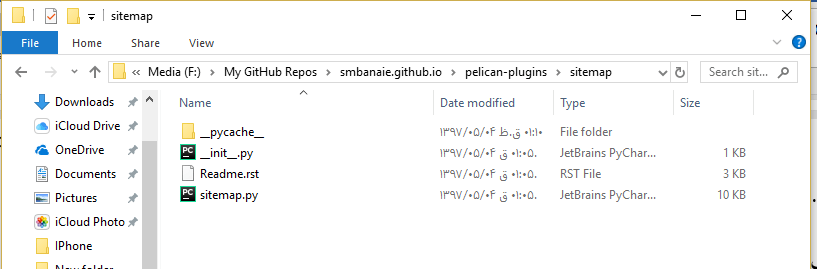
برای فعالسازی و استفاده از این پلاگین دو کار باید انجام دهیم. ابتدا مسیر پوشه پلاگینها و لیست پلاگینهایی که قصد استفاده از آنها را داریم را باید به پلیکان اعلام کنیم. خطوط زیر را به تنظیمات پلیکان برای این منظور اضافه کنید:
### Plugins PLUGIN_PATHS = [ 'pelican-plugins' ] PLUGINS = [ 'sitemap', ]
برای نصب پلاگین بعدی، تنها کافیست که نام آنرا به لیست جلوی PLUGINS اضافه کنیم.
گام دومی که باید برداریم، افزودن تنظیمات مخصوص پلاگین مورد نیاز ماست. برای سایتمپ باید قالب خروجی و اولویت ایندکس کردن سایت و نیز میزان بهروز رسانی محتوا را بیان کنیم. این پارامترها را به صورت زیر به فایل تنظیمات اضافه میکنیم :
# Sitemap
SITEMAP = {
'format': 'xml',
'priorities': {
'articles': 0.5,
'indexes': 0.5,
'pages': 0.5
},
'changefreqs': {
'articles': 'monthly',
'indexes': 'daily',
'pages': 'monthly'
}
}
حال مجددا با دستور fab reserve خروجی سایت را مشاهده میکنیم. در پوشه output فایل sitemap.xml باید تولید شده باشد. حال میتوانید این فایل را در قسمت links تنظیمات با عنوان نقشهسایت اضافه کنید (ذکر نام فایل کافی است )
به همین ترتیب میتوانید سایر پلاگینهای پلیکان را هم به سایت خود اضافه کنید. برای افزودن چند پلاگین مفید مانند امکان جستجو و گذاشتن نظر در پایین هر نوشته، این آموزش ساده و مفید را از دست ندهید.
یکی از مهمترین پلاگینهایی که به آن حتماً نیاز خواهید داشت، پلاگین تاریخ فارسی است. این پلاگین که تاریخ نمایشی مقالات را به فارسی نمایش خواهد داد، از این آدرس قابل دانلود و نصب است.
اتصال یک دامنه به سایت
در مرحله آخر می خواهیم ، یک دامنه ترجیحاً .ir را به این آدرس گیتهاب متصل کنیم. توصیه میکنم ابتدا اکانتی در سایت nic.ir که مرکز اصلی ثبت دامنههای ملی است ایجاد کنید .سپس برای خریداری دامنه از سایتهای واسط که مبلغی بسیار کمتر از nic دریافت میکنند (مثلاً در سایت host97 با مبلغی حدود ۴ هزار تومان برای یکسال به سرعت انجام پذیر است)، دامنه خود را خریداری و همان ایمیل استفاده شده در nic را وارد کنید. سپس میتوانید با مراجعه به سایت nic در بخش دامنهها، نام این دامنه را مشاهده کنید که در ادامه به این قسمت برای تغییر نامهای کارگزاری دامنه نیاز خواهیم داشت.
قبل از هر چیز در پوشه content یک پوشه extra ایجاد کنید و سپس یک فایل با نامه CNAME (حروف بزرگ و بدون پسوند) در این پوشه ایجاد کرده و داخل آن نام دامنه خود را به صورت کامل بنویسید. داخل فایل CNAME سایت شخصی بنده این مقدار وارد شده است :
banaie.ir
حال برای اینکه این فایل در پوشه اصلی خروجی output کپی شود (فایل CNAME حتماً باید درپوشه اصلی وب سایت باشد)، تغییرات زیر را در فایل تنظیمات پلیکان وارد کنید:
STATIC_PATHS = ['images', 'extra/CNAME']
EXTRA_PATH_METADATA = {'extra/CNAME': {'path': 'CNAME'},}
این تغییرات را ذخیره و کامیت و پوش کنید. حال با زدن نام سایت smbanaie.github.io باید به این دامنه هدایت شود و چون هنوز دامنه روی این اکانت گیت هاب ست نشده است، باید خطایی مشاهده کنید.
نکته : از همین روش برای افزودن فایلهایی که در ریشه سایت به آنها نیاز دارید مانند favicon یا robots.txt میتوانید استفاده کنید. کافی است این فایلها را در پوشه extra کپی کنید و متغیر را به صورت زیر بازنویسی کنید :
EXTRA_PATH_METADATA = {
'extra/robots.txt': {'path': 'robots.txt'},
'extra/favicon.ico': {'path': 'favicon.ico'},
'extra/CNAME': {'path': 'CNAME'}
}
متغیر path که در هر خط تکرار شده است، مکان قرارگیری هر فایل را نسبت به ریشه و پوشه اصلی سایت تعیین میکند.
در مرحله بعد، وارد سایت cloudflare شوید و از قسمت sign up یک اکانت جدید برای خود ایجاد کنید. (میتوانید از این روش هم استفاده کنید) بعد از ساخت اکانت، پیغامی مشاهده میکنید که شما هیچ سایتی ندارید. افزودن سایت را بزنید و در قسمت DNS آن کارهای زیر را انجام میدهیم(در زیر فرض کردهایم دامنه ما hesabvaketab.ir است) :
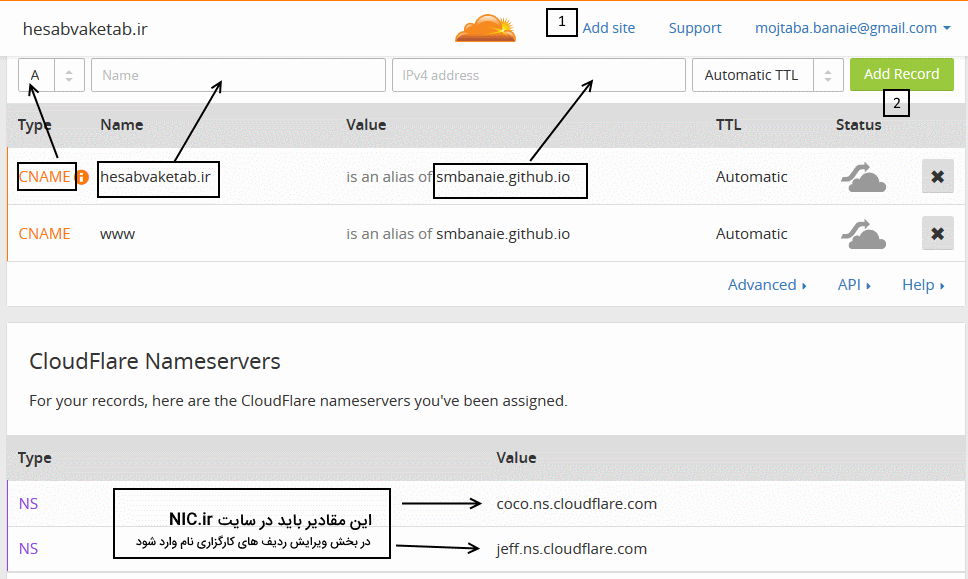
بعد از افزودن این رکوردها و رفتن به صفحه بعد، تنظیمات DNS را مشاهده میکنیم. همانطور که مشخص شده است تنظیمات مشخص شده را باید در سایت nic.ir وارد کنید. وارد سایت nic شده و بر روی دامنه های من، روی نام دامنه کلیک کرده و سپس گزینه ویرایش نام های کارگزاری را انتخاب کرده و مقادیر فوق را وارد کنید.
حداکثر بعد از ۲۴ ساعت باید سایت شما با زدن نام دامنه در مرورگر باز شود
ساخت وب سایت با هر ریپوزیتوری در گیتهاب
دو نوع وبسایت با گیتهاب میتوانیم بسازیم : سایتهای شخصی و سایتهای پروژه. سایتهای شخصی را که در بالا توضیح دادیم. سایت پروژه هم به ریپوزیتوریهایی در گیت گفته میشود که با نام دلخواه ساخته میشوند و معمولاً توضیحاتی درباره پروژههای متنباز گیت هستند. بنابراین اگر قصد دارید یک مخزن کد معمولی خود را به یک وب سایت تعریف کنید، شما باید یک سایت پروژه راهاندازی کنید.
برای ساخت یک سایت پروژه، هنگام ساخت اولیه سایت با pelican-quickstart، کافی است که نوع وب سایت را غیرشخصی اعلام کنید.
> Is this your personal page (username.github.io)? (y/N) N
با این ترتیب، خود پلیکان تنظیمات لازم را در فایل fabfile.py اعمال میکند و با همان دستور
invoke ghpages
سایت شما در مخزن کد وارد شده، آپلود خواهد شد. جزییات بیشتر را در این آدرس میتوانید مشاهده کنید.
چرخه تولید محتوی
حتماً تا الان از این همه کاری که برای راهاندازی سایت باید انجام دهید، کمی نگران شدهاید اما بعد از تنظیمات قالب سایت و سازماندهی مطالب، تولید محتوی و انتشار آنها شامل چند مرحله زیر خواهد بود :
۱. در این مرحله، یک فایل مطلب خالی ایجاد کنید که هر گاه قصد انتشار مطلب جدیدی داشتید، آنرا کپی کرده و در پوشه content درون زیرپوشه مدنظر خود، قرار دهید و پارامترهای آن مانند تاریخ ، برچسبها، نام فایل و … را از روی آن پر کنید. این فایل خالی شما که میتواند درون میزکار شما هم قرارگیرد شبیه زیر خواهد بود:
Title:
Date:
Modified:
Category:
Tags:
Slug:
Authors: Mojtaba-Banaie
Summary:
متن اصلی
۲.با مراجعه به وب سایت مرتب، مطالب خود را با زبان مارکداون بنویسید و حتی یک اکانت در دراپباکس ایجاد کرده، فایلهای تصویر خود را درون پوشه pictures در آن بارگذاری کرده (با رعایت پوشهبندی مناسب)و آدرس آنها را در ادیتور مرتب وارد کنید. تا هم سرعت بارگذاری سایت شما بالاتر برود و هم همانلحظه خروجی را مشاهده کنید. این محتوی را عیناً در پایین فایل فوق کپی کنید.
۳.پارامتر SITEURL را در فایل تنظیمات برابر با آدرس اینترنتی سایت خود قرار دهید (یا دامنهای که خریدهاید و یا همان زیردامنه از سایت github.io).یادتان نرود که در هنگام آزمایش سایت به صورت محلی، این پارامتر را خالی بگذارید .
۴.وارد خط فرمان گیت شوید و درون پوشه اصلی پروژه، تغییرات را کامیت کرده و با دستور fab gh_pages آنها را به سایت اصلی منتقل کنید.
امکان ایجاد سایتهای شخصی با گیتلب
علاوه بر گیتهاب، سایت گیتلب که به دلیل امکانات متنوع و رایگان بودن بسیاری از سرویسها بخصوص امکان ایجاد مخزنکدهای خصوصی رایگان، طرفداران زیادی در بین توسعهگران و برنامهنویسان امروزی دارد،هم سرویس ایجاد سایتهای شخصی تحت دامنه gitlab.io ارائه میدهد.
از مزیتهای گیتلب در خصوص ایجاد سایتهای استاتیک این است که علاوه بر پشتیبانی مستقیم از اکثر موتورهای تولید سایتهای استاتیک ، تولید اتومات خروجی سایت با کامیت کردن تغییرات و ارسال آنها به گیتلب به راحتی امکان پذیر است.
یعنی کافی است متن جدید خود را تایپ کرده و سپس فایل را ذخیره، تغییرات را کامیت و آنها را به گیتلب ارسال کنید. تمام فرآیند تولید سایت از ابتدا توسط خود گیتلب انجام میشود و اگر هم خطایی در حین کار پیش آمد به شما ایمیل زده میشود و گرنه سایت شما به طور خودکار بروز میگردد و دیگر نیازی به انجام دستورات fab gh_pages و مانند آن هم نیست.
برای ایجاد یک سایت ساده با پلیکان و انتشار آن بر روی گیتلب میتوانید از این آموزش مفید هم علاوه بر مستندات خود گیتلب ستفاده کنید.
ارتقای عملکرد مارکداون
اگر می خواهید خروجی مارکداون خود را تغییر دهید یا امکاناتی مانند استفاده از فونتآیکون ها، پانویس و مانند آن را به خروجی اچ تی ام ال خود اضافه کنید، میتوانید از این آدرس، کتابخانههای متنوعی بیابید و حتی نحوه نوشتن توسعه برای مارکداون و سفارشی سازی کامل خروجی را هم یاد بگیرید.
با تشکر از مطالب خوبتون.
من با خطای زیر برخورد می کنم و هر کاری می کنم رفع نمیشه ممنون میشم راهنمایی بفرمایید.
[cce_python theme=’solarized-light’ nowrap=’false’]
WARNING: Feeds generated without SITEURL set properly may not be valid
WARNING: No timezone information specified in the settings. Assuming your timezone is UTC for feed generation. Check http://docs.getpelican.com/en/latest/settings.html#timezone for more information
ERROR: Skipping ./hello-world.md: could not find information about ‘date’
Done: Processed 0 articles, 0 drafts, 0 pages and 0 hidden pages in 0.16 seconds.
[/cce_python]
سلام و خوشحالم که مقاله فوق براتون مفید بوده.
امیدوارم تا الان این خطا را رفع کرده باشید
تنظیماتی که بنده در فایل تنظیمات پلیکان برای تاریخ انجام داده ام از قرار زیره :
[cce_python theme=’solarized-light’]
TIMEZONE = ‘Asia/Tehran’
DEFAULT_DATE_FORMAT = {
‘fa’: ‘%A %d %B %Y’
}
DATE_FORMATS = {
‘fa’: ‘%A %d %B %Y’
}
[/cce_python]
با این مقادیر، مجددا سایت را تولید کنید و ببنید خطا رفع میشود یا نه .
در فایل
hello-world.md
هم در ابتدای فایل پارامتر
date
را حتما وارد کنید.
خیلی مقاله ارزنده بود. مرسی
از شما
سلام. مقاله مفید و مفصلی بود. ممنون و سپاسگزار. فقط یه نکته: فلسفه قالب نوشتاری مارک داون قابل خواندن بودن متن اصلی نوشته شده است.
The overriding design goal for Markdown’s formatting syntax is to make it as readable as possible.