معرفی استودیوی داده گوگل

با گسترش خدمات رایانش ابری در دنیای معاصر و ارائه انواع سرویسهای آنلاین توسط شرکتهای مختلف در این بستر، سرویسهای مختلف پردازش، تحلیل و تصویر سازی داده ها به صورت آنلاین نیز توسط شرکتهای مختلف دنیا در حال ارائه شدن است. سرویسهایی که داده های شما را با هر حجم، پردازش کرده و انواع گزارشات و نمودارها را به شما ارائه می دهند حتی الگوریتم های یادگیری ماشین مورد نیاز را بر روی آنها پیاده می کنند.
یکی از این شرکتهایی که به تازگی به صورت جدی وارد این حوزه شده است شرکت معظم گوگل است. از این شرکت قبلاً خدمات متنوعی را در حوزه پردازش و تحلیل داده شاهد بوده ایم مانند گوگل آنالیتیکز ، گوگل بیگ کوئری ، گوگل اد وردز و مانند آن که هر یک در حوزه ای خاص، به جمع آوری داده پرداخته، گزارشهای مربوط به همان بخش را هم تولید و به کاربران ارائه می کردند اما با ارائه استودیوی داده گوگل، یک گام به سمت سرویسهای آنلاین و همه منظوره پردازش، تحلیل و نمایش داده ها در گوگل نزدیک تر شده ایم .
این ابزار به شما این امکان را می دهد تا اطلاعات خود را درون داشورد خود قرار داده و سپس به آسانی عمل خواندن، به اشتراک گذاری و شخصی سازی داده ها را انجام دهید. با استفاده از این ابزار شما می توانید بر روی داده های کلان خود، داستان های بزرگ ایجاد نموده و تصمیم گیری کسب و کار را با استفاده از آن، بهبود ببخشید.
ویژگی ها و امکانات استودیوی داده گوگل
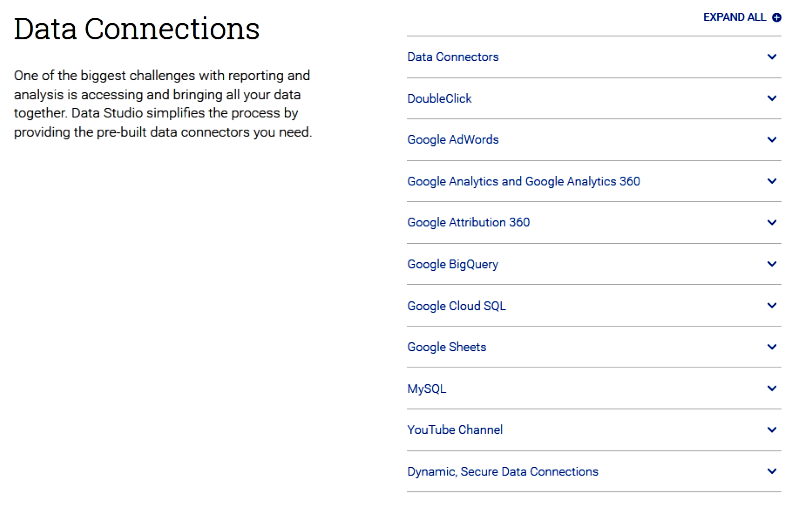
اتصالات داده
یکی از بزرگترین چالش های پیش رو در گزارش گیری و تحلیل داده ایجاد دسترسی و قراردادن همه ی داده ها در کنار هم است. دیتا استودیو به آسانی این فرآیند را با استفاده از اتصالگرهای داده ی پیش ساخته ای که نیاز دارید، مدیریت می کند.
تبدیل داده
همانطور که بیان شد، داده ها باید از حالت خام به فرم اطلاعات کامل و معنی دار تبدیل شوند. این ابزار با استفاده معیارهای انتخاب و تبدیل داده، داده ها را در بلوک هایی با ساختاری قدرتمند برای نمودارها و شکل ها قرار می دهد.
تصویرسازی و سفارشی کردن داده ها
گزارش ها و داشبوردها استانداردی برای بهبود عملکرد کسب و کار هستند. چه از یک گزارش آماده استفاده کنید، چه از ابتدا گزارش را آغاز کنید، استودیوی داده به منظور بهبود نتایج و ایجاد بهترین داستان، راه حل هایی را در تصویرسازی و سفارشی کردن به شما ارائه خواهد داد.
همکاری و اشتراک گذاری
در تحلیل داده ها از دموکراسی کمک بگیرید. با استفاده از این ابزار می توانید در تحلیل داده از خرد جمعی استفاده نمایید و تمام گزارش ها، داشبوردها و استودیوی داده ی خود را با دیگران به اشتراک بگذارید.
قابلیت استفاده
استودیوی داده ی گوگل، با ذهنیت تازه کار بودن کاربران طراحی شده است. با استفاده از قابلیت ها و ویژگی های متنوع و آسان آن مطمئنا در تجزیه و تحلیل داده ها از کار با آن لذت خواهید برد.
امکان کار با هر مقیاس داده
فرقی نمی کند که داده های شمابزرگ باشد یا کوچک، در هر حالت استودیوی داده به شما برای کار با آن و رفع نیازهایتان کمک می کند.
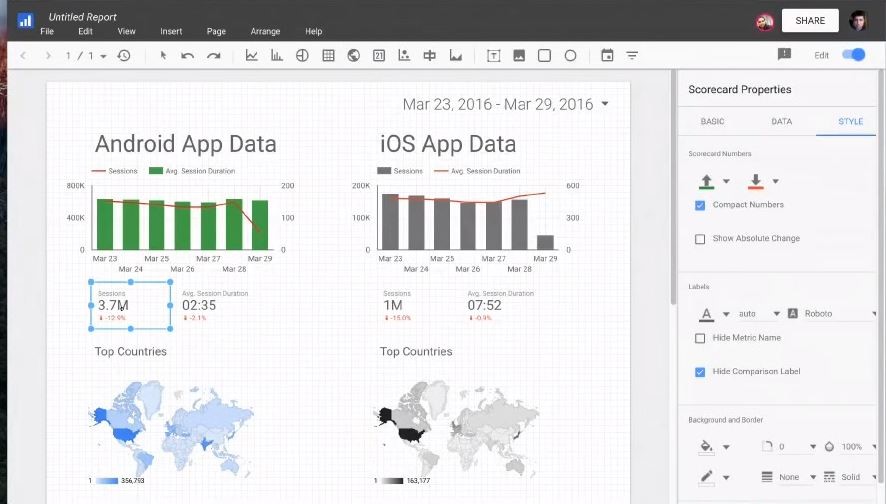
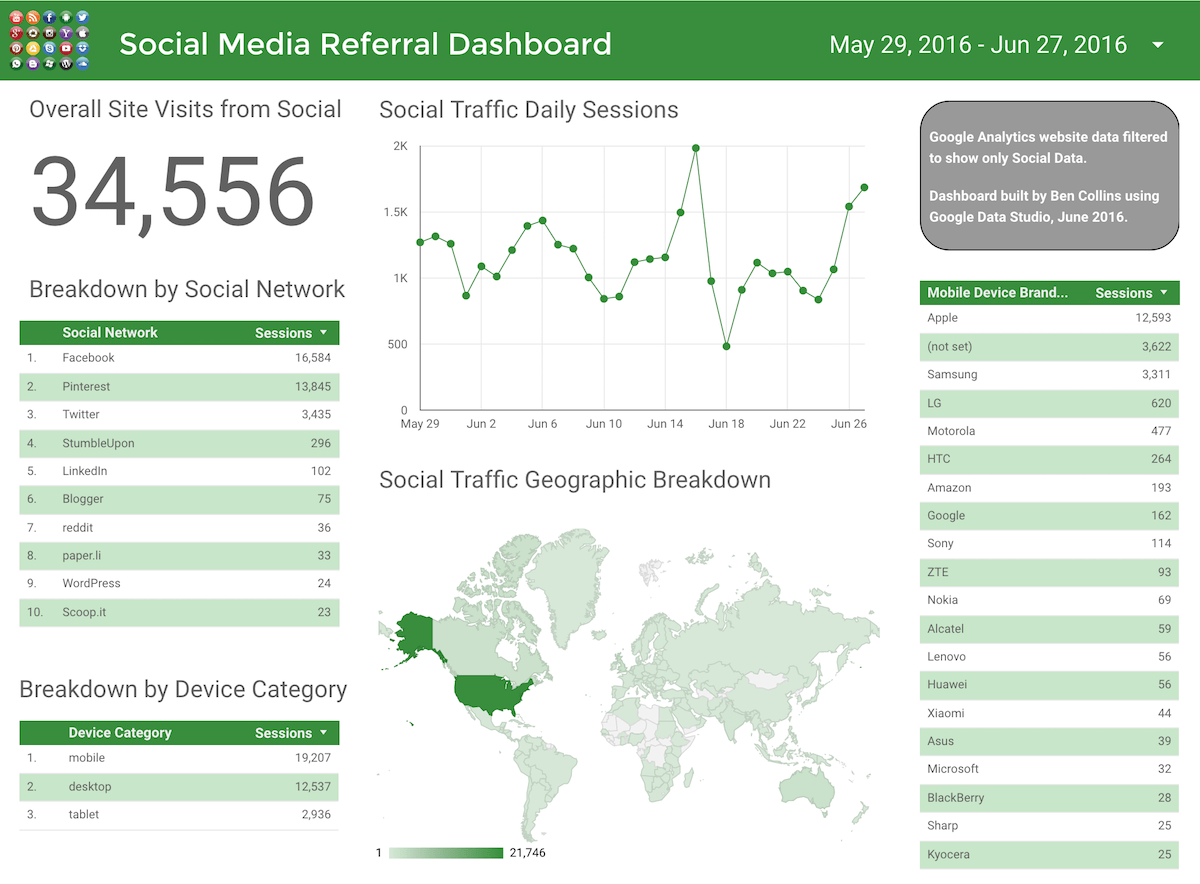
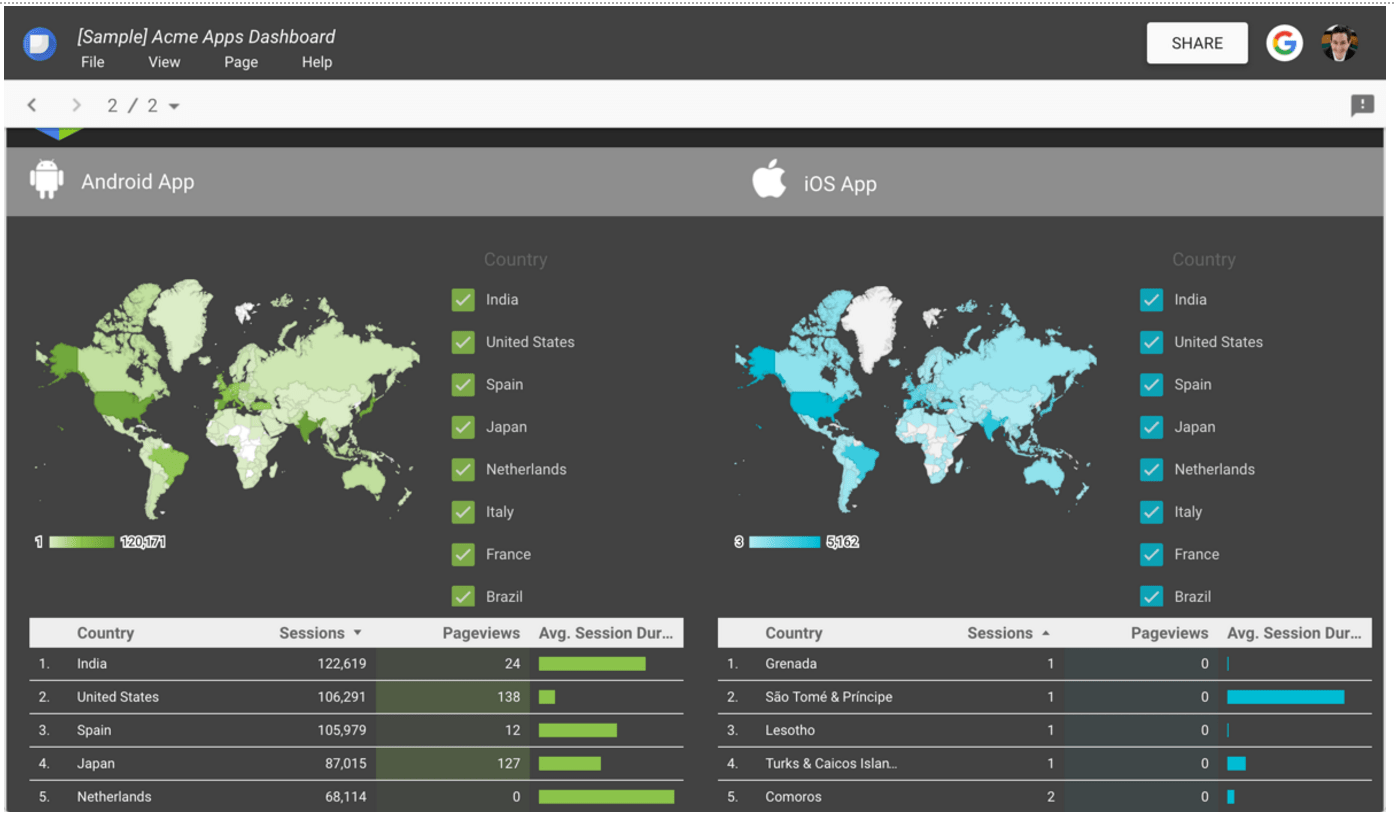
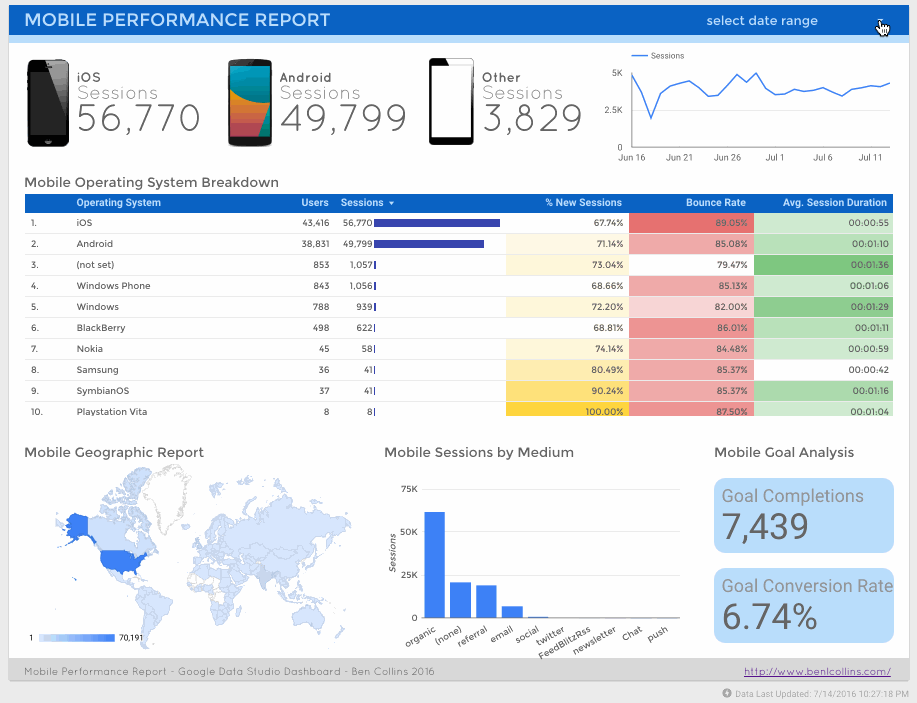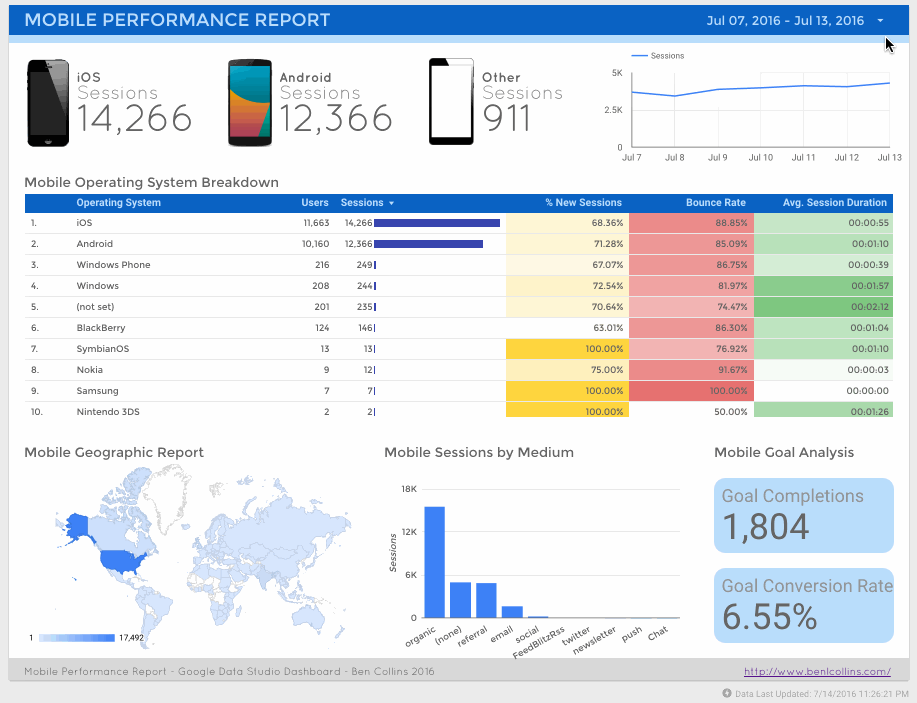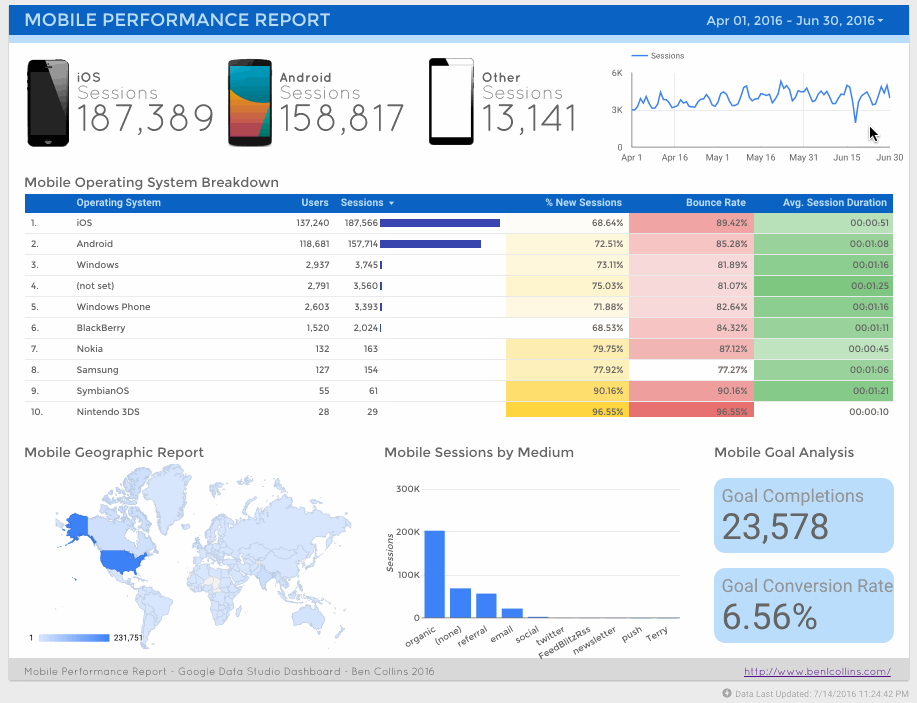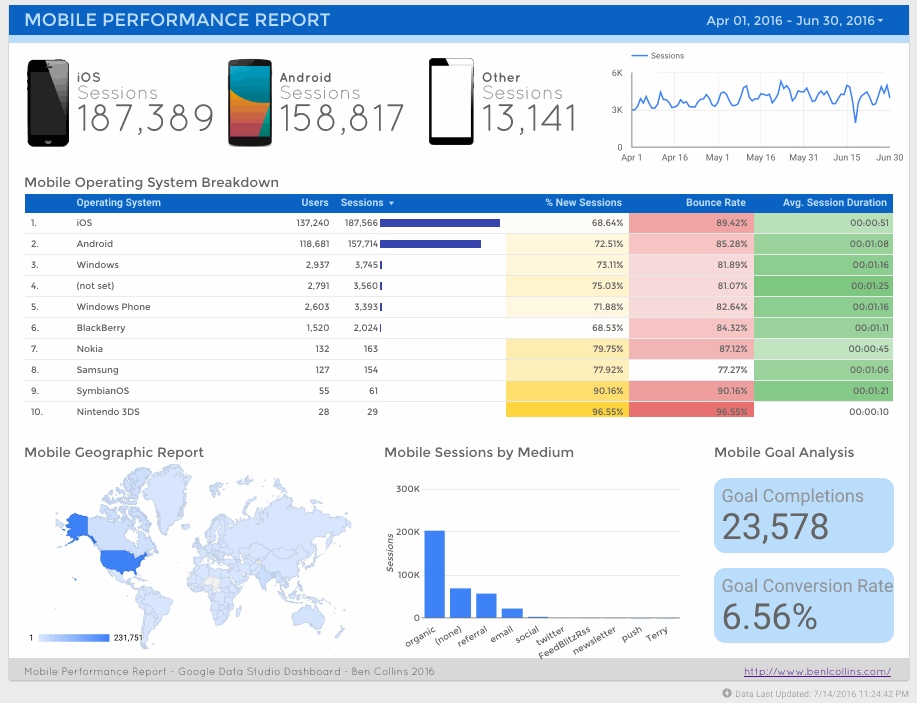
تصاویری از محیط کار آنلاین استودیوی داده گوگل
درمورد نحوه کار با استودیو گوگل به این مقاله که هم توضیح مناسب و هم تعداد زیادی لینک به سایر منابع و آموزشهای مرتبط دارد، می توانید مراجعه کنید .
در زیر به منظور آشنایی بیشتر با این ابزار، تصاویری از انواع داشبوردهایی که با آن ساخته شده است، قرار گرفته است .