

نتیجه این تفکرات و فعالیتهاي پایانناپذیر توسط بسیاری از شرکتها و توسعهدهندگان، معرفی راهکارهای شایستهاي است که یا هماکنون بهصورت عملی استفاده ميشوند یا به زودی شاهد معرفی یک نمونه موفق استفاده عملی از آنها خواهیم بود. نکته جالب توجه درباره پیدایش بيشتر این پایگاههاي دادهای، وجود یک نیاز بزرگ و تولد آنها در شرکتهايي است که هم اکنون با حجم عظیمی از کاربران و دادههاي مرتبط با آنها سروکار دارند. در این مقاله به بحث و بررسی انواع راهکارهای معروف و مهم NoSQL و ارائه توضیحاتی درباره هر کدام پرداختهایم. بدیهی است، راهکارهای دیگری نیز در این مجموعه وجود دارند که به دلیل اهمیت کمتر، از پرداختن به آنها صرفنظر شده و تنها به ارائه نام آنها بسنده کردهایم.
فناوری جدید برای چالش های نوین
در دنیای امروز، حرکت به سمت فناوريهاي جدید در کاربردهای سازمانی یا Enterprise و تحولات عمیق و کلی بهسرعت اتفاق نمیافتند. مجموعههاي بزرگ و سیستمهاي عظیم نرمافزاری تنها زمانی آماده پذیرش تحولات بنیادین ميشوند که چالشهاي جدید و مهمی در برابر آنها وجود داشته باشد. اتفاقی که امروزه در حال بروز است نیز از این دسته اتفاقها به شمار ميآيد. توسعهدهندگان و مجموعههاي بزرگ نرمافزاری، برای مدت مدیدی است که برای ذخیرهسازی داده از پایگاههاي داده رابطهای استفادهميکردند که معماری اولیه آنها به دهه ۱۹۵۰ میلادی بازمیگردد. اما با توسعه اینترنت و پیشرفت نیازهای کاربران و به وجودآمدن چالشهاي جدید، راهحلهاي مهمی در دنیای پایگاههاي داده معرفیشدند که زمینه ساز تحولی بنیادین در این شاخه از صنعت محاسبات خواهدبود.
اصل دوم ، تغییرات دادهها در طول زمانبود که این روزها، خیلی سریعتر از گذشته اتفاق میافتد. مجموعههاي تجاری دنیا، اکنون برای حفظ سرعت رشد و رقابتپذیری خود مجبورند حجم عظیمی از دادههاي متنوع را ذخیره، پردازش و به روزرسانی کنند و همزمان، تاریخچه آنها را نیز دراختیار داشته باشند. پایگاههاي داده سنتی رابطهای اگرچه از پس انجام این امور برميآمدند، اما با افزایش تراکنشها، حجم دادهها و نیاز به سرعت بیشتر، راهحلهاي جایگزین مناسبتر و بهینهای نظیر پایگاههاي داده NoSQL مورد توجه قرار گرفتند و به سرعت، جای خود را در شرکتهاي تجاری بزرگ بازکردند. لازم به توضیح است که استفاده از چنین پایگاههاي داده، برای دستهاي خاص از تجارتهاي بزرگ مناسب بوده و ممکن است بسیاری از کسبوکارهای متوسط و کوچک، با استفاده از آنها به نتیجه دلخواه نرسند و گزینه بهینه برای آنها، همچنان استفاده از پایگاههاي داده رابطهاي باشد.
اصل آخر، اینکه فناوري NoSQL در حال تبدیل شدن به یک کالای تجاری است. در زمانی خاص، شرکتهايي نظیر آمازون و گوگل، برای پاسخ به نیازهایشان مجبور بودند که چنین فناوريهايي را با هزینه سنگین توسعه دهند و به همین دلیل، بسیاری از شرکتهاي بزرگ به دلیل هزینههاي زیاد، از انجام چنین کاری امتناع ميکردند. اما امروزه، با ارائه رایگان کدهای چنین فناوريهايي به مجموعههاي اپنسورسی مانند آپاچی و دیگران، این امکان فراهم شده تا همه بتوانند با کمترین هزینه ممکن، پیچیدهترین کدها را در اختیار داشته باشند و همین امر، فناوری NoSQL را به خوبی در دسترس شرکتهاي کوچکتر قرارميدهد و نتیجه آن، سرعت بیشتر در رشد و توسعه چنین پایگاههاي دادهاي است.با توجه به آنچه ذکر شد، قصد داریم تا راهحلهای NoSQL را که در سالهای اخیر توسعه داده شدهاند و اکنون یک راهکار عملی برای مقابله با چالشهاي جدید هستند، معرفی کنیم.
همانطور که قبلاً نیز ذکر شد، عبارت NoSQL برای اشاره به مجموعه وسیعی از پایگاههاي داده با کاربردهایمتنوع استفادهميشود که از قوانین و اصول حاکم بر پایگاههاي دادهاي سنتی و رابطهاي تبعیت نمیکنند، اما این مجموعه خود متشکل از راهحلهاي متنوعی است که هر کدام برای انجام اموری خاص و به بهترین نحو ممکن، طراحی شدهاند. این امر، باعث ميشود طراحی این پایگاههايداده نیز براساس معماریهاي خاصی انجام شود تا بهترین جواب ممکن از کاربرد آنها به دست آید. به همین منظور، در ادامه مقاله تلاش ميکنیم که این سیستمهاي مبتنی بر NoSQL را به تفکیک نوع معماری (که به تبع نوع عملکرد و کاربرد آنها را نیز تفکیک ميکنند) مورد بحث و بررسی قرار دهیم.
جهت مطالعه بیشتر : آشنایی با الگوهای معماری NoSQL
بانکهای اطلاعاتی کلید/مقدار
نمونهها : Aerospike, Redis, Amazon DynamoDB, Riak , Oracle NoSQL Database,Voldemort, FoundationDB
کاربردهای معمول : کشکردن محتوا ودسترسی سریع به داده ها
نقاط قوت : مراجعه سریع
نقاط ضعف : نداشتن ساختار برای محتوای ذخیره شده
در مدلهای ذخیرهسازی این پایگاههایداده جفتهاي دادهاي کلید/مقدار در اصل بهصورت Distributed Hash Table ذخیره ميشوند به گونه ای که سرویس بازیابی مشابه Hash Table را فراهم ميسازند یعنی کافیست کلید مورد نظر را درخواست کنید تا با سرعت بالا، داده های ذخیره شده برای آن، به شما برگشت داده شود. در پایگاههاي داده کلید/مقدار جدید، هر node (یک ماشین عضو کلاستر پایگاه داده) موجود در سیستم ميتواند مقدار مرتبط با یک کلید را بهصورت بهینه بازیابی كند. مسئولیت نگهداری نگاشت کلیدها و مقدارها در میان نودهای موجود توزیع شده است بهطوری که هر گونه تغییر در مجموعه نودها، کمترین میزان قطع شدن خدمات سیستم را به بار خواهد آورد. این سرویس که هم اکنون در خدمات اشتراک فایل بهصورت peer-to-peer همچون BitTorrent مورد استفاده قرار ميگیرد، وسیلهای برای توسعه نوعی از پایگاههاي داده شده که راهی بهینه برای ذخیره دادههاي ساده، اما در مقیاسی بسیار وسیع را ارائه ميكنند. دادههايي که تنها با کلیدهای اولیه و بدون ارتباطات پیچیده نگهداری ميشوند و توسعهدهندگان برنامه کاربردی که از آنها استفاده ميکنند، از بسیاری از پیچیدگیها و کندی عملکرد پایگاههاي دادهاي رابطهاي در محیط مربوط فراری هستند.
جدول ۱، فهرستي از پایگاههاي داده را که قابلیت عملکرد بهصورت پایگاه داده کلید/مقدار را دارند، ارائه میکند.
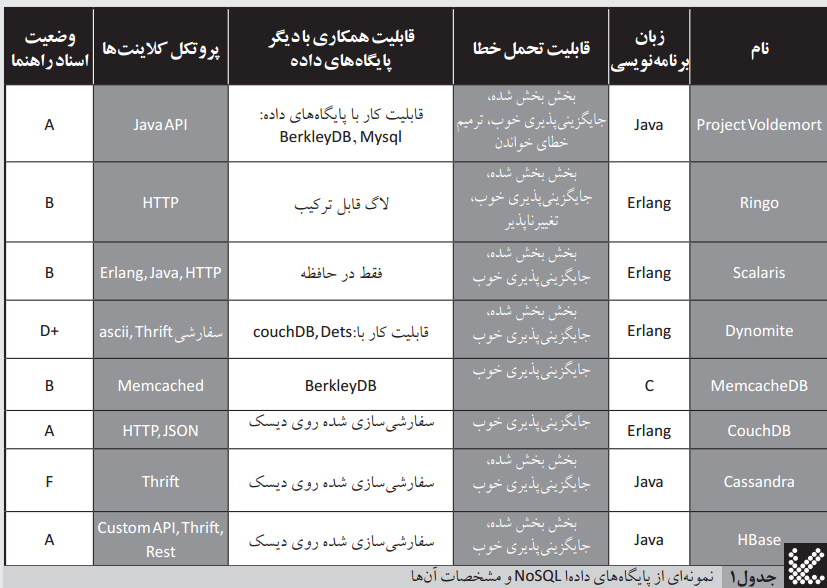
جدول ۱- نمونهاي از پایگاههاي داده های کلید/مقدار و مشخصات آنها
کاربرد نمونه: فرض کنید برنامهاي برای راهاندازی یک انجمن اینترنتی (forum) طراحی شده است. در صفحه پروفایل کاربران، باید آماری از فعالیت گذشته (پستهاي ذخیره شده و…) و همچنین ده پیام آخر برای کاربران نمایش داده شود. کافیست این اطلاعات را به صورت متن با قالب جی سان در آورده و در کلیدی با شناسه آن کاربر، ذخیره کنید . با این توضیح، هنگام ورود به پروفایل یک کاربر، کلیدی را که با شناسه آن کاربر خاص ذخیره شده است، درخواست شده و رشتهاي (String) از اطلاعات مرتبط براساس پروتکل JSON دریافت خواهید كرد که آنها را در جای مناسب نمایش می دهید. به این ترتیب برای نمایش صفحه پروفایل کاربر، نیاز به نوشتن پرس و جو در سایر بانک های اطلاعاتی نیست و با یک درخواست ساده و با سرعت بالا، داده های مورد نیاز در دسترس خواهند بود . البته این امر زمانی امکان پذیر خواهد بود که یک فرآيند پس زمینه، این اطلاعات را هر پانزده دقیقه محاسبه کرده (می تواند از سایر بانکهای اصلی پروژه استفاده کند) و در پایگاه داده کلید/مقدار آنها را بهروز رسانی كند.
اجرای چنین عملیاتی با پایگاههاي داده سنتی رابطهاي در مقیاس بسیار بزرگ، با تعداد بسیاری از سرورها، امری بسیار دشوار و غیر بهینه است. استفاده از پایگاههاي داده key/value در این مورد، یکی از بهترین و بهینهترین راهکارهای ممکن است.
توضیح: در این پایگاهها که بهترین نماینده آنها CouchDB است (به عنوان یک پایگاه داده متن باز و رایگان) و در اصل، نوعی از پایگاههاي داده کلید/مقدار به شمار ميآیند، دادهها در قالب اسناد ذخیره ميشوند. هر سند در این پایگاههاي داده حاوی مقادیر دلخواهی فیلد و الحاقاتی است که ميتوانند حاوی یک فرا داده یا متادیتای دلخواه نیز باشند.
در این مجموعهها، فیلدها در اسناد بهصورت یکتا نامگذاری ميشوند و نوع دادهاي مقدارهای آنها ميتواند متغیر باشد. همچنين، هیچ محدودیتی در اندازه متن و تعداد المانها در این پایگاههاي داده وجود ندارد. در CouchDB به عنوان نمونه، مدل بهروزرسانی دادهها مثبتنگرانه و بدون قفل است و تغییرات روي اسناد، توسط کلاینتهايي انجام ميشود که آنها را دریافت، ویرایش كرده و دوباره به سرور ارسال ميکنند. اینجا عملیات بهروز رسانی یا کاملاً موفقیتآمیز است یا کاملاً با شکست مواجه ميشود. این پایگاه داده به خوبی از خصوصیات ACID پشتیبانیميکند و دادههاي روی دیسک، برای حفظ پایداری سیستم هیچگاه رونویسی نمیشوند. همچنین بهروزرسانیها بهصورت سریالی انجام ميشود، اما به روزرسانیهاي باینری، بهصورت همزمان نوشته ميشوند.
عملیات خواندن در این پایگاههاي داده، زیر نظر یک سیستم کنترل ورژن انجام ميشود که باعث ميشود هر کلاینتی، یک نمونه یکتای کامل از یک سند را در کل عملیات خواندن در اختیار بگیرد.
نمونه موفق دیگری از این نوع پایگاههاي داده، MongoDB است که دادهها را با فرمت اشیاي جاوا اسکریپت (JSON) دریافت کرده و آنها را ذخیره ميکند. در این پایگاه داده، پرس و جوها توابع معمولی جاوا اسکریپت هستند و کار با آن برای توسعهدهندگان وب چندان غریب نخواهد بود. اگرچه موارد ذکر شده بیان سادهاي از عملکرد این پایگاه داده است، اما نکته مهم اين است که MongoDB، شاخصهاي لازم را برای پایگاه داده کاربر به صورت خودکار خواهد ساخت و پرسوجوها را (زمانی که شاخصهای مناسب تولید شده باشند) بسیار سریعتر برخواهدگرداند که البته گوشهاي از عملیات تعیین شاخصها نیز وظیفه توسعهدهنده پایگاه داده است. این پایگاه داده نیز از کتابخانهها و درایورهای متعدد برای زبانهاي برنامه نویسی مهم برخوردار است و ابزارهای توسعه و نگهداری مناسبی نیز برای آن تولید شدهاند.
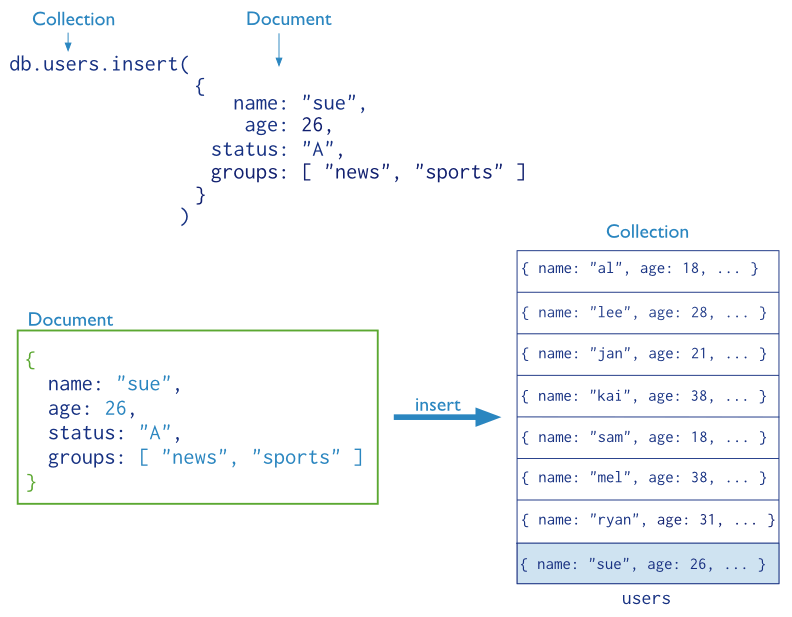
نمونه ای از یک سند ساده در مانگو را در شکل زیر می توانید مشاهده کنید.
کاربرد نمونه: تصور کنید، یک برنامه برای ساماندهی به اوضاع کودکان سر راهی یا گمشده نوشته شود که هدف آن، پیدا کردن و رساندن آنها به خانوادههایشان باشد. جزئیاتی که در این برنامه باید ذخیره شوند، به شدت براساس شرایط هر کودک و وضعیت محیط متفاوت است. به عنوان مثال، ممکن است یک کودک نام کوچک والدین خود را بداند و تنها تصویری از آنها در اختیار داشتهباشد. در این حالت، ممکن است در آینده فرد دیگری کودک مذکور را شناساییکرده و اطلاعات بیشتری در اختیار سیستم بگذارد، اما تا زمانی که این دادهها تأیید شوند، باید راهی برای ذخیره و بازیابی آنها وجود داشته باشد و افزون بر این، از فضای ذخیرهسازی و سرعت عملکرد به بهترین نحو استفاده شود.