
مقدمه ای بر کاساندرا
کاساندرا، فرزند دختر پادشاه شهر تروا بود که علاوه بر داشتن سیمایی زیبا، قدرت پیشبینی آینده را با جزئیاتی بسیار دقیق داشت، بهطوری که به ندرت کسی حرفهایش را باور میکرد. او نابودی شهر تروا را پیشبینی کرده بود اما توان جلوگیری از آن را نداشت. هکتور، شاهزادهای که توسط آشیل در جنگ تروا کشته شد، برادر کاساندرا بود. در سال ۲۰۰۸ دو كارمند سابق آمازون و مايكروسافت که در يك شبكه اجتماعى بزرگ مشغول به کار بودند، يك پايگاه داده جديد NoSQL را ايجاد كردند كه كاساندرا نامیده شد. این پایگاه داده از آن جهت اهمیت دارد که از یک معماری درونی بسیار قوی برای حل معضلاتی بسیار قدیمی سود می برد و به شکل مناسبی پیادهسازی شده است. این امر، علاوه بر پیشرو کردن کاساندرا در زمینه پایگاههای داده NoSQL، آن را به یکی از نمونه های موفق پروژههای اپنسورس تبدیل کرده است. کاساندرا شایستگیهای بسیاری همچون ماندگاری طولانی، مقیاسپذیری بسیار بالا و ثبات تنظیمپذیر دارد و به همین دلیل، توسعهدهندگان بزرگی از طرف شرکتهای معتبر در توسعه کد آن سهیم هستند. کاساندرا امروزه به پیشتازی بلامنازع در زمینه سرعت عملکرد در پردازش تراکنشها تبدیل شده است و آینده درخشانی برای آن پیشبینی میشود. نوشتار حاضر مفاهیم کلی مطرح در کاساندرا، روش کار و نحوه برقراری ارتباط با آن از طریق برنامههای کاربردی NET. را مرور خواهد كرد.
کاساندرا در ۱۰۰ کلمه
پروژه کاساندرا در آغاز توسط یک شبکه اجتماعی معروف برای پاسخگویی به نیازهای روزافزون آن شبکه درتعاملات دادهاي بسیار بزرگ ساخته شد و بعدها، توسعه و نگهداری آن به آپاچی محولشد. کاساندرا یک پایگاهداده اپنسورس است که براساس طرح Amazon Dynamo و مدل دادهاي Bigtable (که از طرف گوگل ارائه شده) طراحی و توسعه دادهشده است و قابلیتهاي کلیدی مانند توزیع یافتگی، تمرکز زدایی، مقیاسپذیری، دسترسپذیری بالا، مقاومت در مقابل خطا، ثبات تنظیمپذیر و ستونگرایی مدل دادهاي در توسعه آن همواره مورد توجه بوده است.
به يقين، خلاصهکردن تمام قابلیتهاي کاساندرا در چند کلمه ساده، گویای واقعیتها و ایدههاي موجود در پس توسعه چنین پایگاه دادهای نیست، اما سعی شده تا در مقالههاي قبلی به گوشهاي از دلایل و مزایای این معماری جدید برای پایگاههاي داده اشاره شود. به همین دلیل، بیش از این به مزایای عملیاتی و مباحث ساختاری و تئوریک مرتبط با کاساندرا نميپردازیم و به بحث و بررسی درباره مدل دادهاي آن، چگونگي نصب و راهاندازی آن و روش کار با آن بهعنوان پایگاه داده از طریق برنامههاي کاربردی خواهیم پرداخت.
مدل دادهای
تا چند سال پیش، تقریباً تمام توسعهدهندگان برنامههایی که به گونهاي با دادهها و پایگاههاي داده سروکار داشتند، تنها مدل دادهاي که برای طراحی در اختیار داشتند، مدل سنتی جدول، ستون و سطری بود که میراث حکمرانی چندین و چند ساله مدل پایگاههاي داده رابطهايبوده است. هماکنون نیز بسیاری ميپندارند همچنان تنها مدل قابل استفاده برای پیادهسازی پایگاه داده، همین مدل سنتی دادهاي است. اما دنیا دیگر تغییر کرده و براساس چالشهاي موجود بر سر راه مدل سنتی، مدلهاي جدیدی معرفی شدهاند که در بسیاری از زمینهها و در مواجهه با بسیاری از چالشها، شایستگیهاي بسیاری دارند. برای آموختن کاساندرا، بهتر است برای چند لحظه، تمام آنچه را که درباره پایگاههاي داده ميدانید، به فراموشي بسپاريد. بسیاری از مفاهیم موجود در مدل داده کاساندرا مانند فضای نام یا keyspace، برای توسعهدهندگان قدیمی پایگاه داده، مفاهیمی جدید و ناآشنا بوده و بسیاری دیگر، مانند ستون یا column معانی متفاوتی با مشابههاي قدیمی خود دارند. همچنين، با اینکه کاساندرا براساس مفاهیم بنیادی داينامو و Bigtable ساخته شده است، اما مدل دادهاي و مفاهیم مرتبط منحصر به فردی برای خود دارد.
برای آشنایی با مدل دادهاي کاساندرا، بهتر است از مفاهیم ساده و ابتدایی برای ذخیرهسازی دادهها شروع كنيم. سادهترین حالت ذخیرهسازی دادهاي را که با استفاده از یک آرایه یا لیست قابل پیادهسازی است، در نظر بگیرید. شكل ۱ نمایی از این مدل را ارائه ميکند. در این حالت، برای فهمیدن اینکه هر عنصر ذخیره کننده چیست، باید اسناد و دانشی درباره آن بهصورت خارجی نگهداری شود. همچنين، برای اینکه اندازه یک شکل کل مجموعه دادهاي حفظ شود، باید مقادیر خالی را با مقادیری مشخص (همانند null) پر كرد. یک آرایه، بهطور ساده ساختار دادهاي سودمندی است، اما از لحاظ معنایی، قوی نیست (شكل۱).
{kind=link}
شکل ۱- ساختار ساده یک آرایه
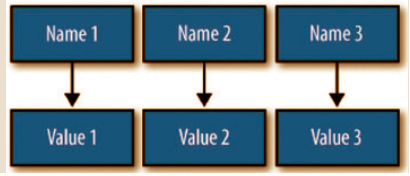
با اضافهکردن یک بعد به ساختار دادهاي قبلی، ساختاری جدید و با مفهومتر، مطابق آنچه در شكل ۲ نشان داده شده، به دست ميآید که حلال برخی مشکلات موجود در مدل قبلی است. بهعنوان مثال، هم اکنون ميدانیم که کدام مقدار، نمایانگر چیست و به چه چیزی اشاره ميکند(شکل۲).
{kind=link}
شکل ۲- اضافه کردن بعد دوم به آرایه، آن را با مفهومتر میکند.
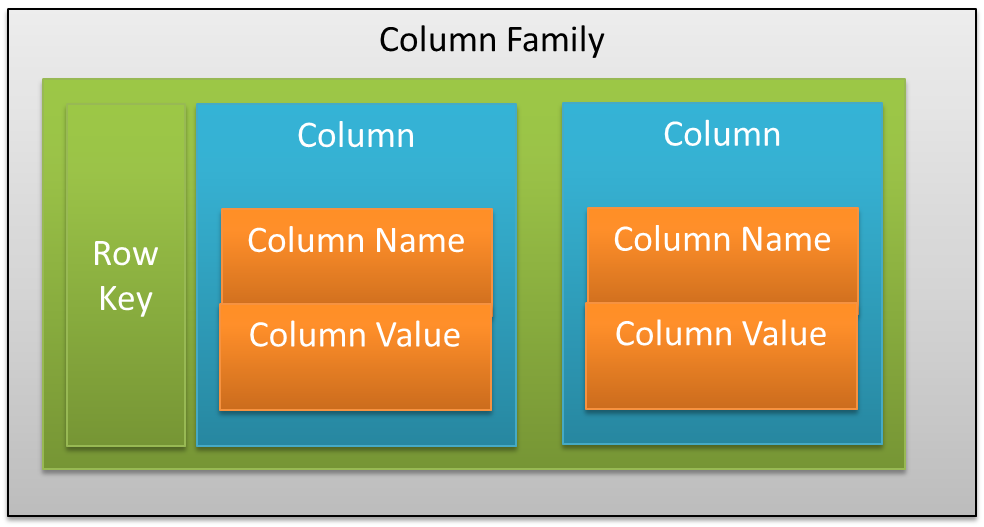
با این حال، با این ساختار تنها ميتوانیم به یک مفهوم (مثلاً یک شخص) اشارهکنیم و راهی برای ذخیرهسازی دادههاي چندگانه (مثلاً اشخاص مختلف) در یک ساختار منفرد را در اختیار نخواهیم داشت. به بیان دیگر، ما به ستونهایی احتیاج داریم که در آنها نیاز نباشد تا نام آنها همواره تکرار شود و همچنين، به مفهومی نياز داریم تا بتوانیم گروهی از ستونها را در یک قالب مفهومی دستهبندیكنيم. راهحل ساده برای اضافهکردن مقادیر چندگانه به ستونها، سطرها هستند که ميتوانند یک شناسه انحصاری به نام کلید سطر یا Row Key را نیز در اختیار داشته باشند. کاساندرا، مفهومی بهنام Column Family را معرفیکرده که برای تقسیمبندی گروهی از ستونهاي مرتبط با یکدیگر درنظر گرفتهشده است و مثالی از آن یک Column Family برای مشخصات اشخاص است. در اصل، مفهوم Column Family در کاساندرا به نوعی شبیه به مفهوم جدول در مدل سنتی رابطهاي است. با کنار هم قراردادن مباحث بالا، ساختار دادهاي کلی کاساندرا از این قرار خواهد بود: ستونها که جفتهاي Name/Value هستند و Column Familyها که حاوی سطرهایی هستند که مجموعههاي ستونی مشابه، اما نه دقیقاً یکسان با تعداد ستونهاي موجود در سیستم، هستند. نکته مهم دیگری که در کاساندرا مطرح است آن است که برخلاف پایگاههاي داده سنتی که در آنها نام ستونها باید تنها یک متغیر رشتهاي باشد، نام ستونها و مقادیر ذخیرهشده در سطرهای مرتبط ميتوانند علاوه بر نوع رشتهای، مقادیر Integer، UUID یا هر نوع آرایه بایتی دیگری نیز باشند. این قابلیت، امکان ذخیرهسازی دادههاي ارزشمند در کلیدها (خود ستونها) را علاوه بر مقادیر آنها (سطرها) فراهم ميسازد که کاربردهای پیشرفتهاي ، به خصوص در زمینه ایندکسکردن دارد.
با استفاده از مدل دادهاي کاساندرا دیگر نیاز نیست تا برای ذخیره هر مدخل جدید دادهای، تمام مقادیر مرتبط با ستونها را دانسته یااز null برای پرکردن مقادیر ناآشنای آنها استفاده كنيم. در کاساندرا به سادگی ميتوانیم مقادیری را که نميخواهیم، ذخیره نکنیم و در زمینه سرعت عملکرد، فضای ذخیرهسازی و قابلیت انعطاف پایگاه داده به نتایج مثبتی برسیم. با این اوصاف، مدل دادهاي منطبق با آنچه در کاساندرا استفاده ميشود را ميتوان همانند شكل۳ در نظر گرفت(شكل۳).
{kind=link}
شکل ۳- نمایی ساده از مدل دادهای کاساندرا
برای آشنایی بیشتر با مفهوم مطرح در شكل ۳، محتوای چنین پایگاه دادهاي را ميتوان با روش JSON با مثالی بهصورت زیر نیز بیان کرد:
Editors: ColumnFamily1 - نام جدول Erfan Nazari: RowKey - کلید سطر Email: Nazari@shabakeh-mag.com ColumnName:Value - مقدار ستون Interests: open-source ColumnName:Value - مقدار ستون Parham Izadpanah: RowKey - کلید سطر Email: izadpanah@shabakeh-mag.com ColumnName:Value - مقدار ستون Directors: ColumnFamily2 - نام جدول Parham Izadpanah: RowKey - کلید سطر Tel: +982166905080 ColumnName:Value - مقدار ستون
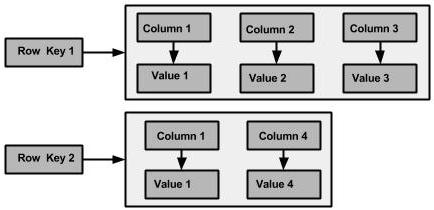
همانطور که در بالا نیز ميبینید، سطرها الزاماً حاوی مقادیر برای ستونهاي مشابهنیستند و در Column Familyهاي دیگر، ميتوان مجموعه ستونهاي دیگری را برای دادههاي مشابه داشت. با این حال، واحدهای دیگری نیز برای گروهبندی ساختار پایگاه داده وجود دارند که با نام Super Column شناخته ميشوند. این اَبَرستونها، مجموعهاي از ستونهاي مرتبط را در یک Column Family شامل ميشوند که ميتوان از آنها به نقشه نقشهها تعبیر كرد. شكل ۴ نمایی از مدل دادهاي کامل کاساندرا را نشان ميدهد (شكل۴). به یاد داشته باشید که ستونها در کاساندرا در اصل یک بعد دیگر با نام timestamp نیز دارند که ذخیرهکننده آخرین به روزرسانیدادههاي درون ستون است. این برچسب زمانی، مقداری خودكار و یک متادیتا نیست، بلکه مقداری است که باید توسط کلاینت فراهم شود و قابلیت پرس وجو نیز ندارد، بلکه برای جلوگیری از اختلاط دادهها مورد استفاده قرارميگیرد. توجه کنید، سطرها برچسب زمانی ندارند، بلکه تنها ستونهاي منفرد برچسب زمانی را ذخیره ميکنند.
{kind=link}
شکل ۴- شکل کامل مدل دادهای کاساندرا
مفاهیم بنیادی
همانطور که قبلاً نیز گفته شده، کاساندرا بهترین راه حل برای اجرا روی مجموعهاي از سرورها است و شاید عملکرد آن روي یک سرور منفرد، چندان رضایت بخش نباشد. بنابراين، ساختار کلی کاساندرا از بیرون، یک کلاستر (و در بعضی مواقع حلقه) نامیدهميشود. عبارت حلقه در این پایگاهداده به این دلیل استفاده ميشود که کاساندرا دادهها را در میان نودهای با آرایش حلقوی مدیریتميکند. واحد سازنده کوچکتر از کلاستر، یک نود (Node) یا به زبان سادهتر یک نسخه از کاساندرا روی یک ماشین منفرد است که وظیفه نگهداری از قسمتی از دادهها را برعهده دارد. در صورتی که هر نود از کار بیافتد، نودهای جایگزینی برای پاسخدهی به پرسوجوها وجودخواهند داشت. تعداد نودهای جایگزین موجود برای هر قسمت از دادهها را فاکتور جایگزینی مينامند. هر کلاستر، نگهدارنده (یک یا چند) مفهوم کلی و انتزاعی با نام Keyspace است که بزرگترین مفهوم دادهاي در کاساندرا به شمار ميآید و معادل مفهوم Database در مدل RDBMS است. هر فضای کلیدی خصوصیات مختلفی (مانند فاکتور جایگزینی، راهبرد جایگزینی، Column Familyها و…) دارد که چگونگي رفتار آن را در کل کلاستر تعیین ميکنند. مفهوم بعدی، Column Familyها هستند که نگهدارنده مجموعه مرتبی از سطرهای دادهاي است و هر کدام از آنها، حاوی مجموعه مرتبی از ستونهای دادهاي هستند. مفهوم Column Family را ميتوان به نوعی معادل جدولها در مدل رابطهاي به شمار آورد، اما توجه کنید که با جدولها بسیار متفاوت هستند. با توجه به مفهوم کلید سطر و مفهوم ستون که در بخش قبل نیز مطرح شدند، به ساختار ۴ بعدی معمول در کاساندرا خواهیم رسید که نقشی اساسی را در دسترسی به دادهها ایفا ميكند:
[Keyspace][ColumnFamily][Key][Column]
برای روشن شدن مطلب، ميتوانیم یک مثال برای ذخیره دادهها در کاساندرا مطرح كنيم. برای این منظور، یک Column Family با نام Hotel برای ذخیرهسازی دادههاي چند هتل، مطابق نوشتار JSON ارائه شده در زیر را در نظر ميگیریم:
Hotel {
key: THE_043 { name: Espinas, phone: 021-66352565,
address: Keshavarz Blvd., city: Tehran, state: Tehran}
key: THC_011 { name: Evin, phone: 021-22668562,
address: Chamran Highway, city: Tehran, state: Tehran}
key: HRD_021 { name: Dariush, phone: 0764-4223659,
address: Dariush Sq. , city: Kish, state: Hormozgan}
key: GIH_042 { name: Height, phone: 0131-5262266,
address: Namak Abrood, city: Chaloos, state: Gilan}
}
توجه کنید که در مثال فوق، برچسب زمانی ستونها را برای سادگی در نظر نگرفتهایم. در صورتی که از طریق CLI (کلاینت استاندارد کاساندرا) پایگاه داده فوق را مورد پرس و جو قرار دهیم، خروجی زیر تولید خواهد شد. در بخشهای بعد، با روشهاي برقراری ارتباط با کاساندرا و چگونگي دسترسی به آن از طریق زبانهاي برنامهنویسی و ورود دادههاي فوق به پایگاه داده، آشنا خواهید شد:
=> (column=state, value=Hormozgan, timestamp=3894166157031651) => (column=phone, value=0764-4223659, timestamp=3894166157031651) => (column=name, value=Dariush, timestamp=3894166157031651) => (column=city, value=Kish, timestamp=3894166157031651) => (column=address, value= Dariush Sq., timestamp=3894166157031651) Returned 5 results.
براساس موارد ذکر شده، از تفاوتهاي کلی موجود میان مدل کاساندرا و مدل سنتی رابطهاي ميتوان به مواردی نظیر نبود زبان پرسوجو (و استفاده از مکانیزم RPC خاصی با نام Thrift)، نبود یکپارچگی مرجعی و در نتیجه نبود عملیات Join و انطباق بهتر کاساندرا با مدل Denormalize شده دادهاي بر خلاف مدل رابطهاي اشارهكرد. بحث تفصیلی در این رابطه را ميتوانید در منابع علمی معرفی شده در همین پرونده دنبال كنيد.
۰
میانگین امتیاز
شما هم امتیاز بدهید!
سلام
خیلی ممنون از مطلب خوبتون
می خواستم سول کنم آیا شما در زمینه اشکالات این نوع پایگاه های اطلاعاتی هم تجربه ای داشته اید یا خیر؟
چون اینگونه دیتابیس ها برای انجام Join مشکلاتی دارند برای مثال فرض کنید اگر اطلاعات افراد روی ۴ نود باشد اطلاعات حسابهای افراد روی ۸ نود و اطلعات مربوط به تراکنشهای آنها روی ۴۰ نود و نیاز به Join نمودن روزانه داده ها به تعداد زیاد داشته باشیم آیا کاساندرا یا SparkSQL یا … می تواند مدیریت داده ها انجام دهد
با تشکر
سلام .
بنده به طور عملی چند سالیست که درگیر این پروژه ها هستم. اوایل فقط با هوس اینکه نو اسکیو ال کار کنیم به سمت این بانکها آمدم و طی اذیت هایی که بابت انتخاب نادرست بانک اطلاعاتی متحمل شدیم،تجربیات خیلی خوبی در این حوزه کسب کردم .
شما اگر نیاز به Join دارید نباید سمت کاساندرا بیایید و اصلا قرار نیست که شما یک بانک رابطه ای را به کاساندرا منتقل کنید. کاساندرا بیشتر برای ذخیره داده هایی استفاده می شود که به ازای یک کلید خاص قرار است داده های مختلفی به یک ترتیب مشخص که معمولا ترتیب زمانی است ذخیره شوند .
به عنوان مثال فرض کنید که شما قصد طراحی دیتابیسی برای نرم افزار تلگرام دارید . در این نرم افزار افراد می توانند در هر متن از هشتگ ها استفاده کنندو قرار است با کلیک روی هر هشتگ، تمام متنهایی که آن هشتگ را دارند به کاربر نشان دهید. در این جا برای فقط همین قسمت ، به سراغ کاساندرا بروید و جدولی بگیرید با نام هشتگ که کلید هر سطر آن خود هشتگ باشد و هر متنی که هشتگ داشت، به سطر همان هشتگ در کاساندرا به ترتیب زمانی افزوده شود. (البته اطلاعاتی مانند زمان و نویسنده متن و گروه هم باید ذخیره شود .)
حال با کلیک کاربر روی هر هشتگ، کافیست ده تا ستون بالایی این سطر را بخوانید و به کاربر نمایش دهید. در این صورت شما با سرعت بالا وبدون نیاز به جوین و اتصال کار خود را انجام داده اید . این سطر مربوط به هشتگ مثلا #رمضان ممکن است بسیار عریض شود اما شما همیشه از بالای جدول اطلاعات را به کاربر نمایش می دهید.
به عنوان مثال دیگر فرض کنید می خواهید فعالیتهای یک کاربر در سایت خود را ذخیره کنید اینکه به ازای هر باری که وارد سایت شما می شود چه صفحاتی را کلیک می کند و چه لینکهایی را مشاهده می کند. شما جدولی در کاساندرا در نظر میگیرید که کلید هر سطر آن، ترکیب نام کاربری شخص و آی دی جلسه جاری کاربر(سشن) باشد. با هر کلیک کاربر شما یک ستون به این سطر اضافه میکنید که بعدا بتوانید براساس کاربر، تحلیل مربوطه را انجام دهید.
مثال دیگر ذخیره لاگهای یک برنامه است . به ازای هر خطا کافیست در سطر مربوط به آن خطا یک ستون اضافه و ذخیره کنید و مدیر سیستم هم هر وقت نیاز به مشاهده لاگ ها داشت ، به ترتیب از بالای سطر شروع به نمایش خواهید کرد. در این جا هم نیاز به جوین و اتصال نداریم .
بنابراین باز هم تاکید می کنم که اگر ماهیت کار شما یک کار رابطه ایست سراغ مای اس کیو ال ،پستگرس یا اس کیو ال سرور و … بروید و فقط بخشهایی از کار را به کاساندرا بسپارید که با ساختار داده ای آن مطابقت دارد . قبلا در مقاله ای با نام «نگاهی اجمالی به نسخه های مختلف مای اس کیو ال – MySQL » توضیح داده ام که در نسخه های جدید مای اس کیو ال ، امکان اتصال مای اسکیو ال به کاساندرا فراهم شده است و این یعنی این که این دو نوع دیتابیس مکمل هم هستند و قرار نیست کاساندرا جای مای اس کیو ال را بگیرد و یا بالعکس .
موفق باشید .