

در ادامه سری آموزشی نرم افزار کیولیک سنس، به یک مجموعه داده نیاز داریم تا آموزشمان را بر پایه آن جلو ببریم. برای این منظور از مجموعه داده کشتی معروف تایتانیک استفاده خواهیم کرد. قبل از هر تحلیلی روی يک مجموعه داده، نیاز به پاکسازی و بررسی اولیه داده ها داریم. قبلاً برای این منظور، نرم افزار OpenRefine را معرفی کرده بودیم که اکنون هم می تواند مورد استفاده قرار گیرد اما برای آشنایی بیشتر با جنبه های مختلف علم داده و زبان محبوب R در این حوزه، تصمیم گرفتیم بخش پاکسازی و پردازش اولیه داده ها را با این زبان آموزش دهیم.
قبل از شروع این آموزش نیاز است که نرم افزار R را از این آدرس دانلود و نصب کنید. برای اینکه راحت تر بتوانید با این زبان آماری پیشرفته ارتباط برقرار کنید توصیه می کنم که R Studio را هم نصب کنید و برنامه های گفته شده در ادامه کار را در این محیط بنویسید. در کتابخانه دیجیتال سایت، کتاب آموزش R به زبان فارسی به قلم دکتر رضاپور هم قرار گرفته است که هرجا به مشکلی برخوردید به آن کتاب هم میتوانید مراجعه کنید. اگر هم می خواهید در محیط خود R به یادگیری این زبان به صورت تعاملی بپردازید توصیه می کنم این مقاله را هم از دست ندهید.
Rattle به عنوان یک کتابخانه معروف داده کاوی و یادگیری ماشین، نیازهای پردازش داده شما را به خوبی مرتفع خواهد کرد. برای نصب این بسته و ماژول در R، کافیست نرم افزار R Studio را باز کنید و در خط فرمانی که وسط صفحه باز شده است تایپ کنید :
install.packages(“rattle“)
پیامی مشابه با این را مشاهده خواهید کرد و کتابخانه های وابسته به Rattle به ترتیب شروع به نصب شدن خواهند کرد :
Installing package into ‘C:/Users/Mojtaba/Documents/R/win-library/3.3’ (as ‘lib’ is unspecified) also installing the dependencies ‘RGtk2’, ‘magrittr’, ‘stringi’ trying URL 'https://cran.rstudio.com/bin/windows/contrib/3.3/RGtk2_2.20.31.zip' Content type 'application/zip' length 13600625 bytes (13.0 MB)
حجم فایلها کمی بالاست (حدود ۳۰ مگابایت) . بنابراین شکیبا باشید….
بعد از اتمام کتابخانه های لازم و مشاهده مکان نما ، برای اطمینان از نصب درست Rattle تایپ کنید :
library(rattle)
rattle()
اگر احیانا کتابخانه gtk+ نصب نباشد، پیامی مشاهده خواهید کرد که آنرا نصب کند یا نه ؟ که شما با نصب آن موافقت کنید و منتظر بمانید که این کتابخانه هم نصب شود . اگر همه چیز با موفقیت پیش برود، محیط گرافیکی Rattle را مشاهده خواهید کرد. (ممکن است پیغامی هم برای نصب کتابخانه XML و cairoDevice مشاهده کنید که آنرا هم تایید نمایید)
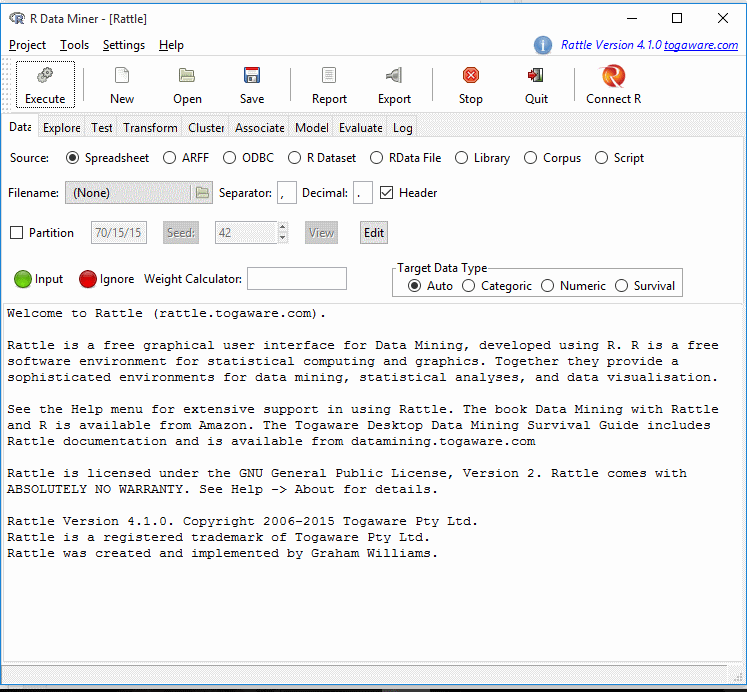
اکنون Rattle آماده استفاده است. بنابراین یادتان نرود که برای اجرای آن و باز شدن محیط گرافیکی Rattle ابتدا باید R Studio را باز کنید و سپس دو دستور فوق را تایپ نمایید …..
شروع کار
قبل از اینکه هر تحلیل یا فرآیند یادگیری ماشین یا داده کاوی ای را بخواهیم روی یک مجموعه داده پیاده کنیم، باید داده ها را بررسی کرده، اشکالات و خطاها را گرفته، داده های پرت را حذف کرده و نهایتاً با نگاه به مقادیر داده ها، دید اولیه نسبت به سیستم پیدا کنیم و اگر نیاز شد، تبدیلات لازم روی داده ها را انجام دهیم. بعد از انجام همه این مراحل، وارد مرحله مدلسازی و داده کاوی شویم.
مجموعه این مراحل را پیش پردازش داده می گوییم و بیشتر وقت دانشمندان داده هنگام کار کردن با یک مجموعه داده را همین بخش تشکیل میدهد.
این آماده سازی و پیش پردازش همانطور که اشاره شد، برای مقاصد زیر استفاده می شود :
- بارگزاری داده ها درون ابزارهای تحلیلی
- بررسی داده ها برای درک مفاهیم و روابط و یافتن مشکلات موجود در آن
- بررسی داده ها جهت رفع مشکلات موجود در آن ها
زمانی می گوییم کیفیت داده بالاست که برای یک کاربرد خاص مناسب باشد. در این بخش، ما به توصیف کیفیت کاراکترهای وابسته به داده می پردازیم. پس از بارگزاری داده ها، ما نیاز به بررسی و تبدیل آن داریم. بررسی و تبدیل داده ها یک عملیات تکراری است اما در اینجا برای وضوح بیشتر ما آن را به دو بخش متفاوت تقسیم می کنیم و هر آموزش هر بخش را جداگانه انجام خواهیم داد. در این نوشتار به بخش تبدیلات و در آموزش بعدی به بررسی داده ها خواهیم پرداخت.
در این آموزش به موضوعات زیر می پردازیم:
- مجموعه داده ها و انواع متغیر
- کیفیت داده
- بارگزاری داده ها در Rattle
- تخصیص نقش به متغیرها
- تبدیل متغیرها برای رفع مشکل کیفیت آنها و بهبود فرمت داده برای مدل سازی
مجموعه داده ها، مشاهدات و متغیرها
مجموعه داده های انواع گوناگونی دارند. زمانی که ما از یک مجموعه داده برای تجزیه و تحلیل پیش بینی ها استفاده می کنیم، می توانیم مجموعه داده را در قالب یک جدول شامل سطرها و ستون ها نمایش دهیم.
در دنیای واقعی، داده های ما با مشکلی که قصد حل آن را داریم مرتبط اند. اگر ما بخواهیم پیش بینی کنیم که کدام مشتری بیشترین خرید یک محصول را دارد، مجموعه داده ی ما احتمالاً حاوی اطلاعات مشتری و تاریخ فروش هاست. در حین یادگیری مباحث، ما نیاز به یافتن یک مجموعه داده برای رسیدن به اهدافمان داریم. شما می توانید نمونه های زیادی از مجموعه داده ها را بر روی اینترنت بیابید؛ در این مورد ما قصد داریم از لیست مسافران تایتانیک که از سایت کگل استخراج شده به عنوان مجموعه داده استفاده کنیم.
کگل بزرگترین جامعه ی تحلیل و پردازش داده دنیاست و مسابقاتی که در حوزه تحلیل داده در دنیا برگزار می کند و امتیازی که به تک تک دانشمندان علوم داده می دهد، مرجعیست برای سنجش اعتبار فنی افراد.
یک مجموعه داده ماتریسی ست که هر سطر آن شامل یک عنصر یا یک عضو مجموعه داده است. در مجموعه داده ی تایتانیک، هر سطر حاوی اطلاعات یک مسافر ، و هر ستون شامل یک متغیر خاص است. به عنوان مثال، در لیست مسافران، ستون جنسیت (sex) یک متغیر است. در لیست بخشی از لیست مسافران تایتانیک نشان داده شده است.
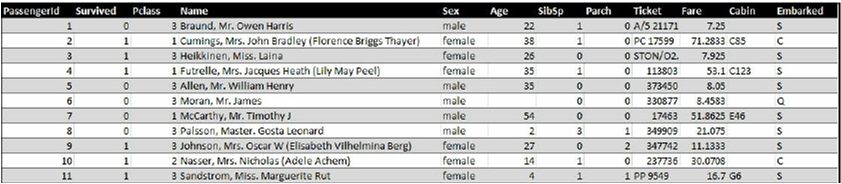
پیش از شروع به کار ما نیاز به درک کاملی از مجموعه داده و اطلاعات موجود در آن داریم. زمانی که یک مجموعه داده را از وب دریافت می کنیم، معمولاً مستنداتی در مورد متغیرهای آن هم ضمیمه می باشد که می توانیم از آن استفاده کنیم.
در زیر به توصیف متغیرهای موجود در این مجموعه داده می پردازیم.
Survived: اگر مسافری زنده مانده باشد، مقدار این متغیر یک و در غیر اینصورت صفر می باشد.
Pclass: این متغیر، مخفف کلاس یا بخشی ست که مسافر در آن مستقر شده است. این متغیر می تواند سه مقدار داشته باشد.( ۱= first Class؛ ۲= second Class؛ ۳= third Class).
Name: این متغیر حاوی نام مسافر می باشد.
Sex: این متغیر مربوط به جنسیت مسافر است.
Age: این متغیر مربوط به سن مسافر است.
SibSp: این متغیر به تعداد خواهران یا برادران/همسران شخص در کشتی می باشد.
Parch: این متغیر به تعداد والدین/فرزندان شخص در کشتی می باشد.
Ticket: این متغیر شماره بلیت مسافر را می گیرد.
Fare: این متغیر مربوط به کرایه ی مسافر می باشد.
Cabin: حاوی شماره کابین مسافر است.
Embarked: این متغیر مربوط به بندری ست که مسافر در آنجا سوار شده است. این متغیر می تواند دارای هر یک از سه مقدار زیر باشد:C،Q و S (C = Cherbourg; Q = Queenstown; S = Southampton).
برای کارهای تحلیل داده ما دو نوع متغیر داریم :
- متغیر های خروجی یا متغیر های هدف (Target): این ها حاوی متغیرهایی هستند که ما می خواهیم پیش بینی کنیم. در لیست مسافران، متغیر Survived یک متغیر خروجی است. به این معنا که ما می خواهیم زنده ماندن یک مسافر را پیش بینی کنیم.
- متغیرهای ورودی: متغیرهایی نیز وجود دارند که ما جهت ایجاد یک پیش بینی از آنها استفاده می کنیم. در لیست مسافران، متغیر جنسیت یک متغیر ورودی محسوب می شود.
Rattle متغیرهای خروجی را به عنوان متغیرهای هدف می شناسد. برای جلوگیری از سردرگمی، ما قصد داریم در این آموزش از عنوان متغیر هدف استفاده کنیم. در این مجموعه داده، ده متغیر ورودی ما شامل (Pclass،Name ، sex،age ، sibSp، parch، Ticket،Fare ، Cabin و Embarked) می باشد که ما می خواهیم برای پیش بینی پتانسیل زنده ماندن شخص از آنها استفاده کنیم. بنابراین در این آموزش، متغیر هدف ما Survived خواهد بود.
در سایت کگل و در بخش داده های مسابقه آموزشی کشتی تایتانیک، لیست مسافران به دو فایل CSV شامل train.csv و test.csv تقسیم شده است که در train.csv با ۸۹۱ سطر یا مسافر، برای هر مسافر متغیر Survived آن حاوی مقدار مشخص است یعنی می دانیم که آن مسافر خاص، زنده مانده است یا نه .دومین فایل، test.csv، تنها شامل ۴۱۸ مسافر است، متغیر Survived آن بدون مقدار می باشد یعنی ما نمی دانیم مسافر زنده است یا خیر. هدف از این رقابت استفاده از فایل آموزشی برای ایجاد یک مدل است که مقدار متغیر Survived را در فایل تست پیش بینی کند. (به همین دلیل متغیر Survived به عنوان متغیر هدف در نظر گرفته می شود)
Rattle دو نوع متغیر اصلی را پشتیبانی می کند : عددی و طبقه ای (Categorical). یک متغیر عددی، حاوی ارزش عددی اندازه گیری شده است. در این مجموعه داده، age، SibSp، Parchو fare متغیرهای عددی هستند.
یک متغیر طبقه ای یا دسته ای، متغیری ست که می تواند در مجموعه های مختلف گروه بندی شود. دو نوع متغیر طبقه ای داریم: ترتیبی و اسمی. در یک متغیر ترتیبی هر مجموعه با یک عدد نمایش داده می شود که بیانگر رتبه یا اهمیت یا رابطه ای بین داده ها می باشند. در مجموعه داده ای ما،Pclass یک متغیر مجموعه ای ترتیبی با سه دسته ی متفاوت با اعداد ۱، ۲ و ۳ است یعنی مسافرین در سه درجه مختلف، بلیط کشتی تایتانیک را خریداری کرده اند و هر کلاس یا طبقه، نشان از میزان قدرت مالی مسافرین است.
در یک متغیر طبقه ای اسمی، مجموعه با یک برچسب کلمه ای نشان داده می شود و فقط یک اسم است بدون بیان هیچ ترتیبی. در این مجموعه داده، جنسیت مثالی ازین نوع است. این متغیر دو مقدار ممکن دارد که با کلمات female(زن) و male(مرد) برچسب گذاری شده است. یا بندری که مسافر از آن سوار شده است (Embarked)، فقط یک متغیر اسمی است .
بارگزاری داده ها
در Rattle شما باید به صراحت نقش هر متغیر را اعلام کنید. یک متغیر می تواند پنج نقش متفاوت زیر را داشته باشد:
ورودی (Input): فرآیند پیش بینی، از متغیرهای ورودی جهت پیش بینی مقدار متغیر هدف استفاده خواهد کرد.
هدف (Target): متغیر هدف، خروجی مدل ما خواهد بود.
ریسک (Risk): متغیر ریسک واحد اندازه گیری متغیر هدف است.
شناسایی یا شناسه ( Ident یا Identifier): یک شناسه، متغیری برای شناسایی منحصر بفرد یک شی یا یک سطر است. در مثال قبل، person یک شناسه است که یک شخص منحصر بفرد را مشخص می کند.
رد شده (Ignore): متغیری که با علامت ignore نشانه گذاری شده، توسط مدل نادیده گرفته خواهد شد. بعداً در مورد این نوع داده بیشتر بحث خواهیم کرد. این متغیرها گاهاً باعث ایجاد دردسر و کاهش عملکرد مدل پیش بینی می شوند.
Rattle می تواند داده ها را از چندین منبع داده بارگزاری کند. در اینجا چندین انتخاب وجود دارد:
- استفاده از منابع صفحه گسترده برای بارگزاری داده از یک فایل CSV
- Open Database Connectivity (ODBC) یک استاندارد برای تعریف اتصال پایگاه داده است. با استفاده از این استاندارد، شما می توانید از رایج ترین پایگاه داده ها بارگزاری را انجام دهید. در این گزینه شما می توانید داده ها را از ERP، CRM، سیستم های انباره داده و سایر پایگاه داده ها بارگزاری نمایید.
- استفاده از Attribute-Relation File Format (ARFF) برای بارگزاری داده از فایل های وکا(Weka). وکا یک نرم افزار ماشین های یادگیرنده می باشد که با جاوا نوشته شده است.
- همچنین شما می توانید مجموعه داده های R را بارگزاری کنید. این جداول در حافظه R بارگزاری شده اند. در حال حاضر، Rattle داده های فرمت R را پشتیبانی می کند.
- گزینه ی RData file، به شما اجازه ی بارگزاری مجموعه داده های R را که به صورت یک فایل، معمولاً .Rdata ذخیره شده اند، می دهد.
- با گزینه ی Library، Rattle می تواند مجموعه داده های نمونه را که در پکیج های R قرار داده شده، بارگزاری کند.
- گزینه ی Corpus اجازه ی بارگزاری و پردازش یک پوشه از مستندات را می دهد.
- در تصویر زیر، شما می توانید انتخاب گزینه ی Script را مشاهده نمایید.
در این آموزش قصد داریم تا با بارگزاری فایل CSV به توصیف ویژگی های Rattle بپردازیم. معمولاً از CSV برای بارگزاری داده استفاده می کنیم. بر روی اینترنت شما می توانید نمونه مجموعه داده های زیادی از این نوع را بیابید.
بارگزاری یک فایل CSV
برای یادگیری نحوه ی بارگزاری داده در Rattle، به سراغ داده هایی که پیش از این بیان شد می رویم. از اینجا می توانید فایل train.csv را دانلود کنید.
گام های زیر را برای بارگزاری فایل train.csv دنبال کنید:
- نرم افزار Rattle را باز کرده و به سربرگ Data می رویم (سربرگ پیش فرض نرم افزار هم هست) :
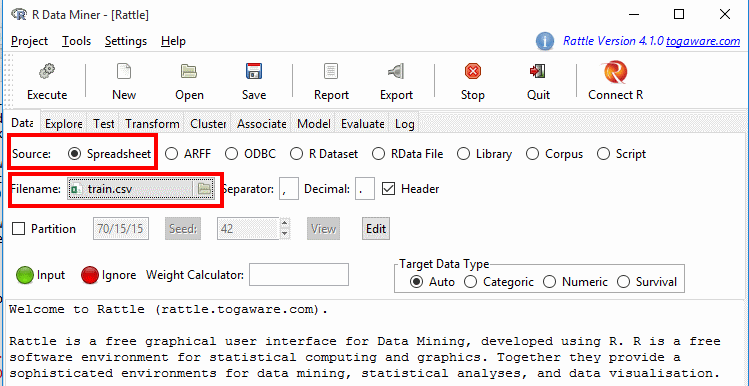
- گزینه ی Spreadsheet را به عنوان منبع داده انتخاب کرده و بر روی آیکون پوشه ی Filename کلیک کنید.
- فایل train.csv را انتخاب کرده و بر روی Open کلیک کنید.
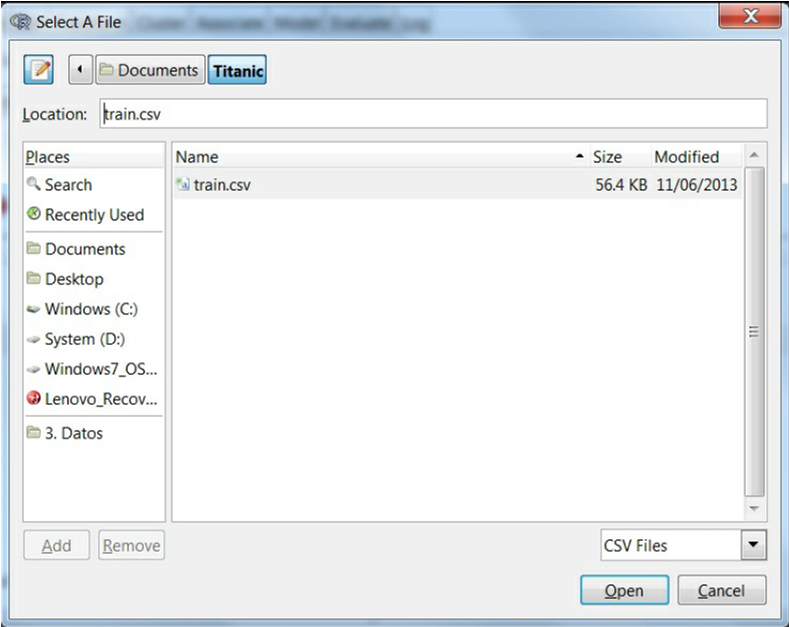
- در نهایت بر روی دکمه ی Execute در بالای صفحه برای بارگزاری مجموعه داده کلیک کنید.

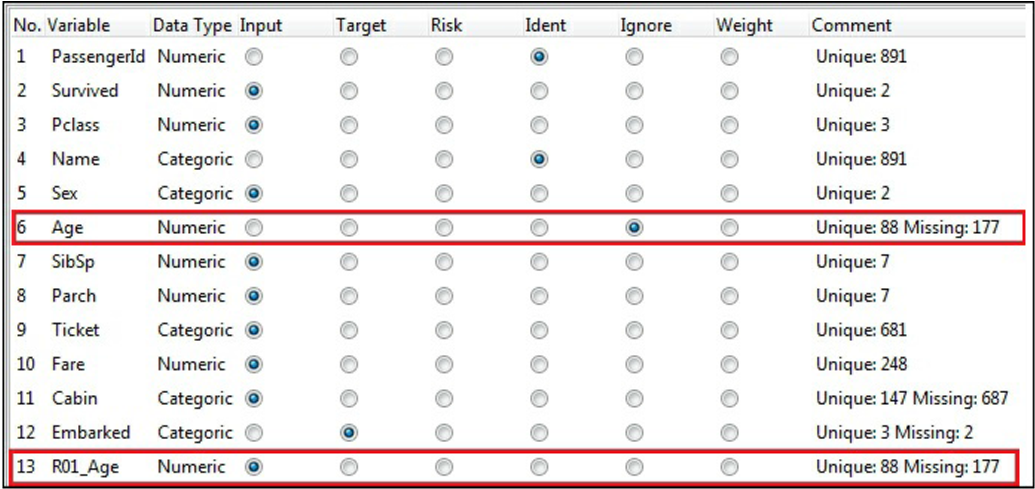
Rattle داده ها را از فایل بارگزاری کرده، و پس از تجزیه و تحلیل آن ساختار مجموعه داده را حدس میزند. حال ما می توانیم بررسی داده ها را شروع کنیم. در پنجره ی Rattle، ما می توانیم ۸۹۱ سطر مجموعه داده را به همراه نه متغیر و متغیر Survived به عنوان متغیر هدف، مشاهده کنیم. (اگر Rattle تنظیمات دیگری را به شما نشان داد و مثلاً متغیر شناسه یا هدف دیگری را انتخاب کرده بود، خودتان تنظیمات را به شکل زیر در آورده و دکمه Execute را بزنید.) ما می توانیم نقش هر متغیر را با استفاده ازدکمه های رادیویی جلوی آنها تغییر دهیم. توجه کنید که Age، Cabin و Embarked دارای مقادیر از دست رفته(missing values) هستند:
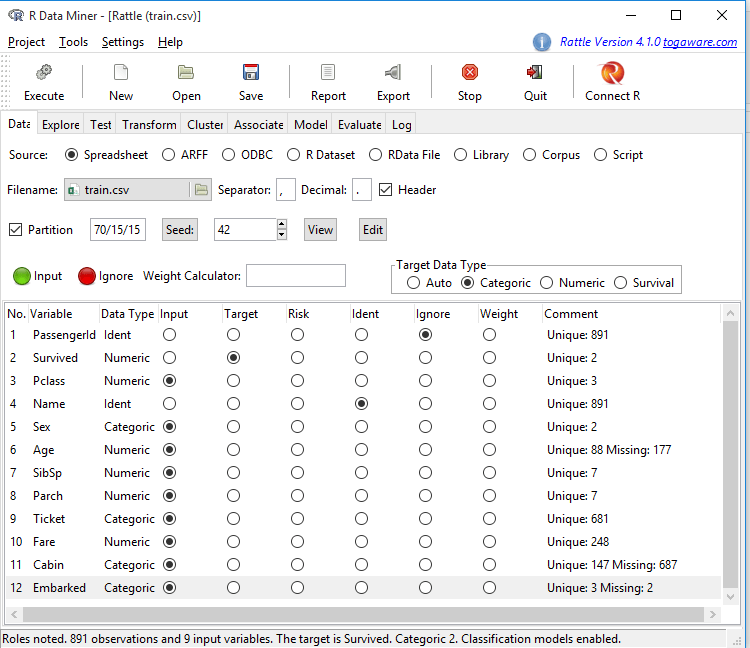
در مورد داده های ناموجود یا از دست رفته، در ادامه آموزش، صحبت خواهیم کرد.
موضوع این مجموعه داده پیش بینی زنده ماندن یا نماندن یک مسافر است. متغیر هدف، Survived بوده و دارای دو حالت ممکن ست:
- ۰ ( زنده نمانده)
- ۱ (زنده مانده)
متغیر name یک شناسه منحصر بفرد برای هر مسافر است. (PassengerId هم می تواند شناسه باشد که فعلاً آنرا غیر فعال کرده ایم – Ignore)به همین دلیل، ما ۸۹۱ سطر و ۸۹۱ مقدار متفاوت داریم.
تغییرات لازم را در نقش های متغیرهای متفاوت، طبق شکل بالا ایجاد کرده و روی دکمه ی Execute برای بروزرسانی داده ها کلیک کنید. برای ذخیره ی کار، بر روی دکمه ی Save کلیک کنید و یک نام مناسب برای فایل انتخاب کنید.
دکمه ی Save، کار ما را ذخیره می کند اما منبع داده یعنی فایل Csv را ویرایش نخواهد کرد.

در سربرگ Data در Rattle، دو دکمه ی مفید وجود دارد-view و Edit. با استفاده از این دکمه ها شما می توانید داده هایتان را ویرایش و مشاهده کنید. ما همچنین جعبه انتخاب (check box) ،Partition را مطابق شکل زیر داریم که داده ها را به صورت تصادفی به سه گروه آموزشی ، اعتبار سنجی و تست (به نسبت ۷۰ ، ۱۵ و ۱۵) تقسیم می کند و بیشتر برای داده هایی به کار می رود که قبلاً داده های تست و آموزشی آنها تفکیک نشده است . برای مسافرین تایتانیک، که داده ها را به تفکیک می توانیم دانلود کنیم از این گزینه استفاده نخواهیم کرد.:

آخرین گزینه در بارگزاری داده Weight Calculator است. این گزینه به شما اجازه می دهد تا فرمولی برای اولویت دادن به برخی مشاهدات درج کنید.
شما می توانید به طور خودکار با ویرایش نام ها در فایل اصلی، نقش های مد نظر خود را مستقیماً به متغیرها نسبت دهید. زمانی که شما یک متغیر را با ID شروع می کنید، Rattle به طور خودکار به آن نقش یک شناسه را می دهد. شما می توانید با نامگذاری یک متغیر با استفاده از عبارات Target، Risk و Ignore، به Rattle برای تعیین نوع داده ها کمک زیادی بکنید.
تبدیل داده و تحلیل اکتشافی آن، دو مرحله تکرار شونده هستند. یعنی ما هنگام تحلیل و بررسی داده ها، مجبور به برخی تبدیلات روی داده ها هستیم . با اعمال این تغییرات، مجدداً کار تحلیل را ادامه می دهیم که باز منجر به تغییرات بعدی می شود و این روند، چندین بار تکرار خواهد شد و هدف آن هم بهبود کیفیت داده برای ایجاد یک مدل دقیق تر است. برای تبدیل داده ها، شما ابتدا نیاز به درک آنها دارید. در حقیقت شما زمانی که داده ها را به خوبی بشناسید، می توانید آنها را بررسی و تبدیل کنید.
برای سادگی، در این آموزش ابتدا به تبدیل داده ها می پردازیم و در آموزش بعدی به بررسی و اکتشاف داده خواهیم پرداخت.
کارشناسان داده کاوی معمولاً زمان زیادی را پیش از شروع مدل سازی صرف آماده سازی داده می کنند. آماده سازی داده یک عمل مسحور کننده در ساخت مدل پیش بینی نیست اما تاثیر زیادی در عملکرد مدل دارد. بنابراین، صبور باشید و زمان بیشتری را برای ساخت یک مجموعه داده ی خوب بگذارید.
زمانی که ما تبدیلی را روی یک متغیر انجام می دهیم، Rattle متغیر اصلی را ویرایش نمی کند و یک متغیر جدید با پیشوندی که نمایانگر تبدیل انجام شده است و نام متغیر اصلی را نمایش می دهد. در زیر یک مثال از تبدیل نمایش داده شده است:

در لیست متغیرهای بالا، می توانید متغیر fare را پس از اعمال تبدیل مشاهده کنید.
تبدیل داده با Rattle
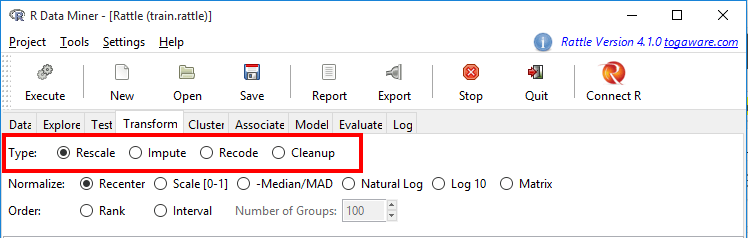
سربرگ Transform در Rattle چهار نوع تبدیل متفاوت را پیشنهاد می دهد:
- Rescale
- Impute
- Recode
- Cleanup
این گزینه ها در شکل زیر نمایش داده شده اند:
تغییر مقیاس داده
مقیاس ها در دنیای واقعی در اندازه های متفاوت استفاده می شوند؛ برای مثال، در فهرست مسافران تایتانیک، حداقل مقدار برای متغیر سن برابر ۰٫۴۲ و حداکثر مقدار برابر ۸۰ است. برای متغیر Fare (کرایه) ، حداقل مقدار برابر صفر و حداکثر ۵۱۲٫۳ است. به همین دلیل، ۱۰ درجه اختلاف برای متغیر سن میزان زیادی و برای کرایه اختلاف کمی است. برخی از الگوریتم ها و تکنیک ها به همه متغیرها در مقیاس مشابه نیاز دارند، و ما نیاز داریم تا مقادیر مقیاس های مختلف را برای رسیدن به مقیاس مشابه تنظیم کنیم. تغییر مقیاس ( Rescaling) روند تنظیم مقادیر عددی از یک متغیر به مقیاس های مختلف است.
در rattle، گزینه ی تغییر مقیاس دو زیر گزینه دارد –Normalize و Order. نرمال سازی متغیرها (Normalize)، به این معناست که مقادیر مختلف مشاهدات در یک مقیاس مشخص تنظیم می شوند. رایج ترین مقیاس در نرمال سازی مقیاس[۱-۰] است. اگر ما این گزینه را روی متغیر اعمال کنیم، Rattle مقادیر این متغیر را بین ۰ و ۱ نگاشت خواهد کرد. به عنوان مثال در جدول زیر ما برای ۵ مقدار از متغیر Age این روش را اعمال کرده ایم. همانطور که مشاهده می کنید حداقل مقدار ۰ و حداکثر مقدار برای سن ۸۰ است. با تغییر مقیاس بین ۰ و یک، حداقل مقدار برابر ۰ و حداکثر مقدار یک نگاشت خواهد شد. مقادیر میانی بین دو مقدار صفر و یک نگاشت خواهند شد:
|
سن |
مقدار جدید |
| ۰٫۴۲ | ۰ |
| ۵ | ۰٫۰۵۷۵۵۲۱۴۹ |
| ۱۹ | ۰٫۲۳۳۴۷۵۷۴۸ |
| ۵۴ | ۰٫۶۷۳۲۸۴۷۴۵ |
| ۸۰ | ۱ |
در تبدیل متغیر به روش Order نرم افزار Rattle دو تبدیل متفاوت ارائه داده است—Rank و Interval. با استفاده از گزینه ی Rank، به حداقل مقدار متغیر، رتبه ی یک را اختصاص می دهیم و به بقیه مقادیر، نسبت آنها را بایک به دست آورده و نمایش می دهیم. زمانی که ما به محاسبه ی نسبت مقادیر یا به عبارتی موقعیت نسبی آنها بیشتر از ارزش حقیقی آنها اهمیت دهیم، از این گزینه استفاده می کنیم.
در این مثال، حداقل مقدار برای سن ۰٫۴۲ می باشد که برابر اولین موقعیت در صف داده هاست. دومین نسبت یا موقعیت در صف نسبت دهی به متغیرها، مربوط به مقدار ۰٫۶۷ است و سومین و چهارمین جایگاه در صف مقادیر مشابه ۰٫۷۵ را دارند. در این مورد، Rattle از موقعیت سه و چهار استفاده نکرده و به جای آن مطابق جدول زیر از ۳٫۵ استفاده می کند.
| سن | رتبه (Rank) |
| ۰٫۴۲ | ۱ |
| ۰٫۶۷ | ۲ |
| ۰٫۷۵ | ۳٫۵ |
| ۰٫۷۵ | ۳٫۵ |
| ۰٫۸۳ | ۵٫۵ |
و در نهایت، با استفاده از گروه بندی Interval، مقادیر در مجموعه های مختلفی گروه بندی می شوند. با استفاده از باکس ورودی مطابق شکل زیر، تعداد گروه هایی که قصد ایجاد آن را داریم انتخاب می کنیم:
![]()
با استفاده از روش Interval و گروه بندی در ۱۰ مجموعه، Rattle ده گروه ایجاد می کند و آنها را به ترتیب از صفر تا نه برچسب می زند. بسته به مقدار هر داده، Rattle هر مشاهده را به یک گروه نگاشت خواهد کرد. حداقل مقدار برابر ۰٫۴ است که در گروه صفر قرار می گیرد. بالاترین مقدار به همین روش در گروه شماره ۹ قرار خواهد گرفت.
مقدار دهی به مقادیر از دست رفته با استفاده از گزینه ی imput
گاهی اوقات، شما برای برخی متغیرها، به دلیل وجود داده های از دست رفته، مشاهدات ناقصی خواهید داشت. دلایل متفاوتی برای وجود داده های از دست رفته وجود دارد. گاهی اوقات، داده ها به صورت دستی جمع آوری شده و همه آنها با دقت مشابهی جمع آوری نشده اند. گاهی نیز داده ها از چندین سنسور جمع آوری شده اند و یکی از آنها ممکن است به طور موقت از کنترل خارج شده باشد.
نادیده گرفتن داده های از دست رفته می تواند مشکل ساز باشد. در R، مقدار NA به معنی عدم دسترسی برای داده های از دست رفته تخصیص داده می شود، اما بسیاری از منابع داده هستند که داده های از دست رفته را با مقادیر واقعی و مشخصی کدگذاری می کنند. برای مقادیر عددی، ۰ یا ۹۹۹۹۹ می تواند نمایانگر اعداد از دست رفته باشد. شما بایستی داده های خود را به دقت برای یافتن مقادیر از دست رفته ی واقعی بررسی کنید. همانطور که می بینید، در مجموعه داده ی تایتانیک، متغیرهای Age،Cabin و Embarked دارای مقادیر از دست رفته هستند.
با استفاده از گزینه ی imput، ما می توانیم انتخاب کنیم که چگونه در مجموعه متغیرها داده های از دست رفته را مطابق شکل مقداردهی کنیم:

Rattle به ما اجازه می دهد تبدیلات زیر را روی مقادیر از دست رفته اعمال کنیم:
Zero/Missing: با استفاده از این گزینه، Rattle همه ی مقادیر از دست رفته در نوع عددی را با صفر و مقادیر از دست رفته در متغیرهای مجموعه ای را با عبارت Missing جایگزین می کند.
Mean: این گزینه از مقدار میانگین در متغیرهای عددی برای پر کردن مقادیر از دست رفته استفاده می کند. البته از این گزینه در متغیرهای مجموعه ای استفاده نمی شود.
Median: با استفاده از این گزینه ما می توانیم مقادیر از دست رفته را با میانه (عددی که دقیقاً برای هر متغیر در وسط قرار میگیرد ) جایگزین کنیم. مشابه مقدار میانگین از این گزینه تنها در متغیرهای عددی استفاده می شود.
Mode: با انتخاب این گزینه، Rattle مقادیر از دست رفته را با مقدار دارای بیشترین تکرار جایگزین می کند. این گزینه می تواند در هر دو نوع متغیرهای مجموعه ای و عددی استفاده شود.
Constant: این گزینه به ما اجازه می دهد تا مقادیر از دست رفته را با یک مقدار ثابت جایگزین کنیم. مشابه گزینه ی Mode ما می توانیم از این روش در هر دو نوع متغیرهای عددی و مجموعه ای استفاده کنیم.
Rattle دارای پنج انتخاب متفاوت است و چنانچه قصد استفاده از رویکرد متفاوتی داشته باشیم نیاز به کدنویسی آن در Rattle داریم یا اینکه می توانیم مقادیر از دست رفته را پیش از بارگزاری در Rattle جایگزین کنیم.
حتما فکر می کنید که گزینه های Median، Mean و Mode مشابه هستند و نمی توان فهمید از این میان کدامیک باید انتخاب شود. برای انتخاب یکی از این گزینه ها، ما باید ببینیم چگونه مقادیر در سطرهای مختلف توزیع شده اند. در آموزش های بعدی خواهیم دید که هیستوگرام بهترین نمودار برای مشاهده توزیع مقدار در یک متغیر است و با نحوه ی رسم نمودار هیستوگرام در Rattle آشنا خواهیم شد.
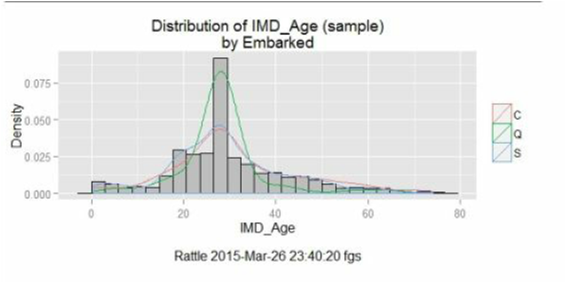
برای درک چگونگی پر کردن مقادیر از دست رفته، می توانید هیستوگرام متغیر اصلی را تجزیه و تحلیل کنید سپس یک تبدیل را اعمال کرده و هیستوگرام جدید را تجزیه و تحلیل کنید. برای مثال در مورد متغیر Age، ما یک هیستوگرام با متغیر اصلی ایجاد کرده ایم (تصویر سمت چپ) و پس از اعمال تبدیل Zero هیستوگرام جدید را ایجاد می کنیم. زمانی که نسبت Zero را استفاده می کنیم، ما این مقدار را با همه ی مقادیر از دست رفته جایگزین می کنیم. در نهایت شما چیزی مشابه نمودار زیر را مشاهده خواهید کرد:
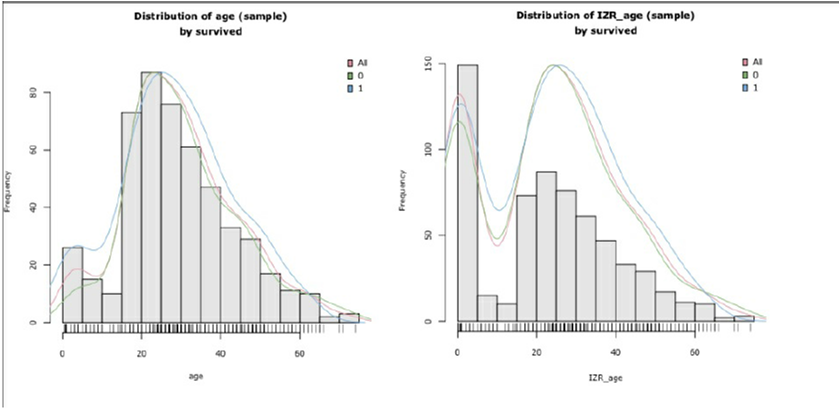
هیستوگرام نمایش داده شده در سمت چپ، تصویر متغیر اصلی Age است. میانگین برابر ۲۹٫۷ سال است. در مجموعه داده ی تایتانیک، متغیر Age دارای ۱۷۷ مقدار از دست رفته است. در حین عمل جایگزینی، این ۱۷۷ مقدار با ۰ جایگزین خواهند شد. این عمل میانگین توزیع را برابر ۲۳٫۸ خواهد کرد. در این مورد، ما می توانیم افراد زیادی را با سن صفر مشاهده کنیم. همانطور که می بینید، عملکرد برخی تکنیک ها یا الگوریتم ها می تواند از این تغییر در توزیع تاثیر بگیرد.
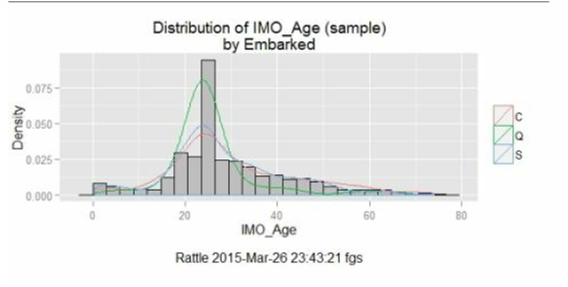
حال، ما می توانیم نسبت Mean (پر کردن مقادیر از دست رفته با میانگین)، نسبت Median (پر کردن مقادیر از دست رفته با میانه) یا Mode (پر کردن مقادیر از دست رفته با مد) را اعمال کنیم.
این سه شکل نحوه ی توزیع را بر روی هیستوگرام متغیر سن پس از اعمال جایگزینیMean (اولین تصویر)، جایگزینی Median (تصویر دوم) و جایگزینی Mode (آخرین تصویر) می باشد و همانطور که مشخص است، اعمال هر تبدیل، به شدت روی مقدار میانگین داده ها موثر است.
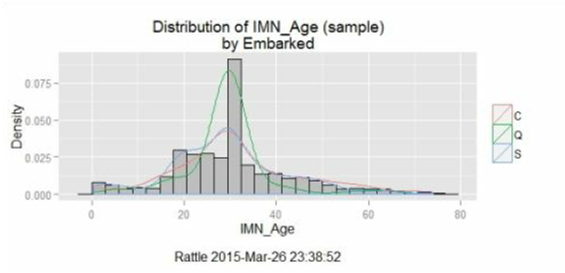
علاوه بر این، شما باید گزینه حذف را هم برای همه مقادیر از دست رفته در متغیر سن در نظر بگیرید. گزینه بعدی هم پرکردن داده های از دست رفته با یک مقدار ثابت است. این متغیر در میان ۸۹۱ سطر موجود دارای ۱۷۷ مقدار از دست رفته است؛ بنابراین پر کردن همه ی این فضاها با یک مقدار ثابت احتمالا باعث ایجاد یک عملکرد بد خواهد شد.
کدنویسی مجدد متغیرها (Recoding)
ما از گزینه ی Recode برای تبدیل مقادیر متغیرها توسط توزیع مقادیر درون مجموعه های مختلف یا تغییر نوع متغیر استفاده می کنیم.
طبقه بندی کردن (Binning)
برخی مدل ها و الگوریتم ها تنها با متغیرهای مجموعه ای کار می کنند. Binning عملیاتی ست که می تواند برای تبدیل یک متغیر عددی به یک متغیر طبقه ای مفید باشد. مثلا اگر بخواهیم برای متغیر سن، به جای مقادیر عددی از چهار مقدار : کودک، جوان، میانسال و پیر استفاده کنیم باید از روش طبقه بندی یا همان Binning استفاده کنیم.
چگونگی طبقه بندی یک متغیر به این صورت است:
- تقسیم کردن بازه ی مقادیر به چند مجموعه یا طبقه مختلف . (مثلا سن به چهار گروه فوق)
- توزیع هر مقدار درون طبقه متناظر آن . (تعیین اینکه این مقدار جزء کدام طبقه است )
برای تعریف طبقه ها یا مجموعه ها، ما سه انتخاب داریم:
- با استفاده از Quantiles گروه هایی با تعداد سطر مشابه ایجاد می شود.
- با استفاده از KMeans گروه هایی که اعضای آن براساس فاصله مقادیر تعیین می شوند، ایجاد می شود.
- انتخاب Equal Width برای توزیع مقادیر در گروه هایی با عرض یکسان، مطابق آنچه در تصویر نشان داده شده است.
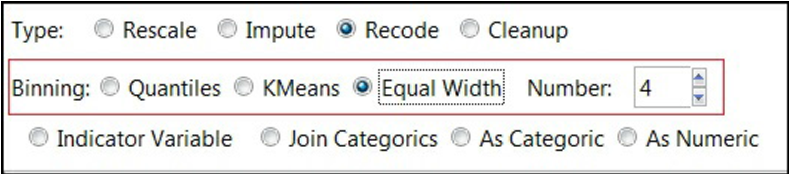
مانند تصویر، سعی کنید تبدیل عرض یکسان Equal With را اعمال کنید (هنگام انتخاب Binning) . Rattle ده گروه ایجاد خواهد کرد و هر سطر را در یک گروه قرار خواهد داد.
برای توزیع مقادیر درون گروه های مختلف، شما می توانید از روش دیگری نیز استفاده کنید. مطابق شکل زیر این مراحل را طی کنید: در انتخاب Type، گزینه ی Rescale و سپس در انتخاب Order گزینه ی Interval را انتخاب کرده و Number of Grouping را بر روی مقدار ۱۰ تنظیم می کنیم.
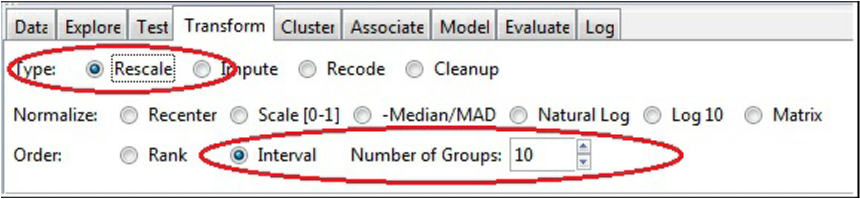
تفاوت این دو انتخاب در چیست؟ متغیر سن یک متغیر عددی ست؛ زمانی که ما از Recode استفاده می کنیم، نتیجه نیز یک متغیر عددی ست. اگر شما از Binning استفاده می کنید، متغیر جدید یک متغیر مجموعه ای خواهد بود. مطابق آنچه در شکل زیر نمایش داده شده است:
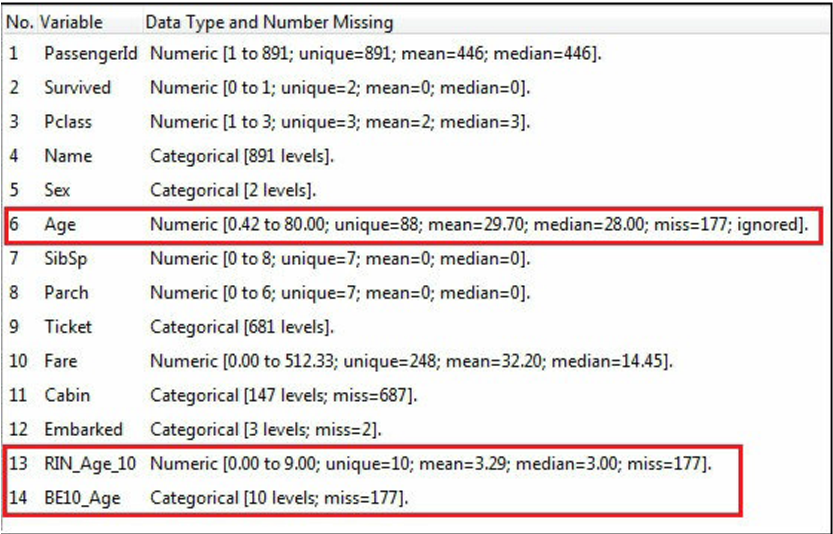
در تصویر قبلی، ما RIN_Age_10 را با استفاده از Rescale و متغیر BE10_Age را با استفاده از Binning ایجاد می کنیم.
Binning می تواند به منظور کاهش خطای داده های ناکافی و تعداد کم سطرها هم استفاده شود(small observation errors) .شما می توانید با جایگزینی مقدار اصلی توسط مقدار نماینده ی گروه، تاثیر خطاهای ناشی از تعداد ناکافی داده ها را کاهش دهید.
متغیرهای شاخص
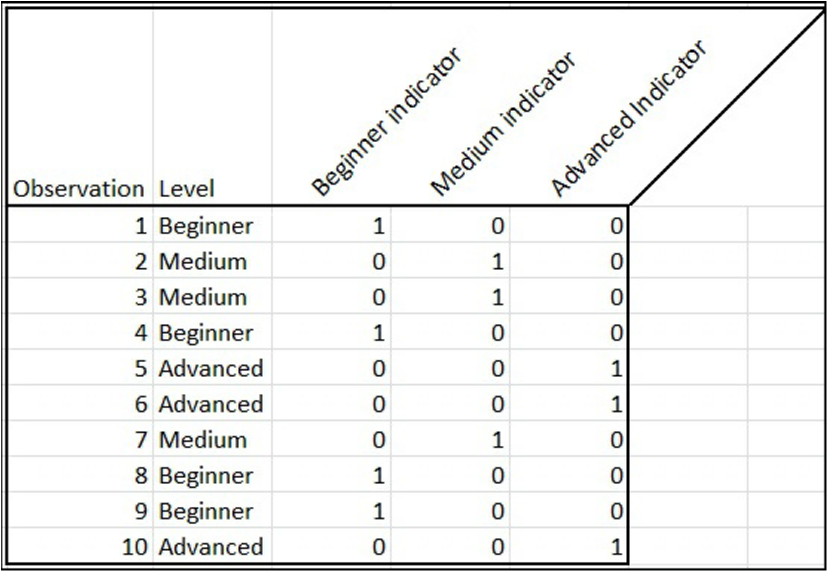
برخلاف بخش قبلی، برخی الگوریتم ها (مانند بسیاری از مدل های خوشه بندی) تنها با متغیرهای عددی کار می کنند. یک روش ساده برای تبدیل متغیرهای مجموعه ای به عددی استفاده از متغیرهای شاخص است. بدین صورت که به جای یک متغیر با سه مقدار پیر و جوان و کودک، ما سه ستون جدید ایجاد می کنیم با نام پیر و جوان و کودک (که عبارت indicator به آن ها اضافه شده است) و بسته به اینکه سطر مورد نظر ما کدام مقدار را دارد (جوان، کودک و پیر)، دو ستون از این سه ستون جدید حاوی صفر و یک ستون حاوی عدد یک خواهند بود.
برای مثال، یک متغیر مجموعه ای برای مثال Level را با سه مجموعه ی Beginner، Medium و Advanced انتخاب کنید و گزینه اجرا را بزنید: سه متغیر جدید با نام های Beginner indicator، Medium indicator و Advanced indicator ایجاد خواهد شد. مطابق شکل زیر اگر مقدار متغیر Level، برابر Beginner است، متغیر Beginner indicator را برابر یک و در غیر این صورت برابر صفر قرار می دهیم.
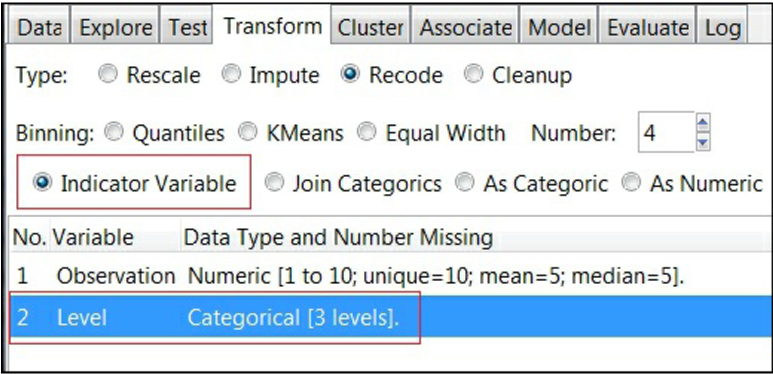
در Rattle، سربرگ تبدیل Transform، دارای گزینه ای با عنوانIndicator Variable است. به منظور این تبدیل، متغیر را انتخاب کنید (در این مورد، Level)، سپس Indicator Variable را انتخاب کرده و مطابق آنچه در تصویر نمایش داده شده است، بر روی دکمه ی Execute کلیک کنید. Rattle یک متغیر برای هر مجموعه ی متعلق به متغیر مجموعه ای، ایجاد می کند:
اتصال مجموعه ها
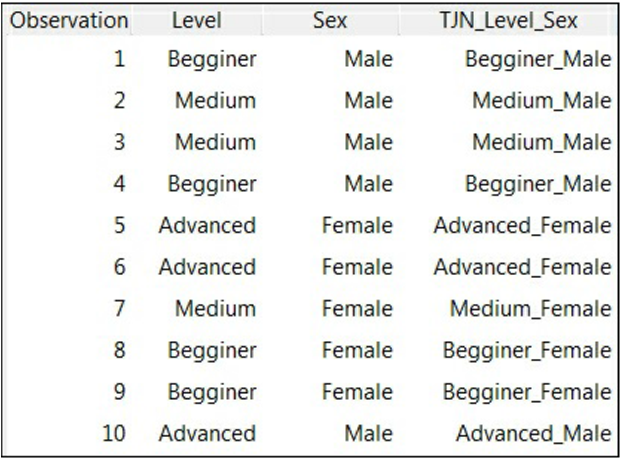
با استفاده از گزینه ی Join Categories، Rattle دو متغیر مجموعه ای را داخل یک متغیر قرار می دهد. در جدول زیر، ما از Rattle برای قرار دادن Level و Sex در یک متغیر استفاده می کنیم:
گزینه ی As Category
با استفاده از گزینه ی As Category، شما می توانید متغیرعددی را داخل متغیر مجموعه ای قرار دهید.
گزینه ی As Numeric
با استفاده از گزینه ی As Numeric، شما می توانید متغیر مجموعه ای را داخل متغیر عددی قرار دهید.
عملیات پاکسازی
با استفاده از گزینه ی Cleanup در سربرگ Transform مطابق آنچه در تصویر می بینید، شما می توانید ستون ها و سطرهای مجموعه داده را حذف کنید.
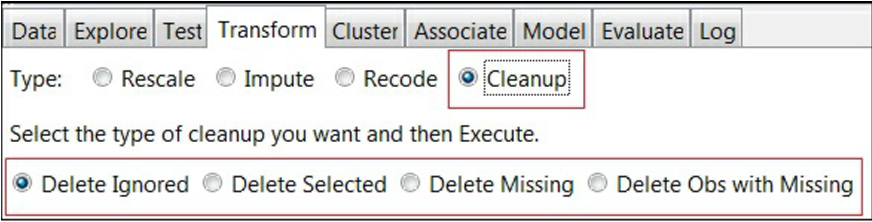
در زیر گزینه های مختلف در دسترس برای عملیات پاکسازی ذکر شده اند:
- Delete Ignored: این گزینه می تواند متغیرهایی که با نشانه ی ردشده (Ignore) مشخص شده اند را حذف کند.
- Delete Selected: این گزینه متغیرهای انتخابی را حذف می کند.
- Delete Missing: این گزینه همه ی متغیرهای دارای مقادیر از دست رفته را حذف می کند.
- Delete Obs with Missing: این گزینه تنها سطرهایی از متغیر انتخابی که دارای مقدار از دست رفته است را حذف می کند.
حال شما نحوه ی تبدیل متغیرها را یاد گرفتید. زمانیکه Rattle یک متغیر را تبدیل می کند، عمل ویرایش روی متغیر اصلی اعمال نخواهد شد. نرم افزار یک متغیر جدید با اصلاحات مربوطه ایجاد می کند. اگر شما تبدیلی را بر روی متغیر سن ایجاد نمایید، شما علاوه بر متغیر سن، یک متغیر جدید خواهد داشت. الگوریتم های شما تنها به یک متغیر نیاز دارند، متغیر اصلی یا متغیر تغییر یافته، بنابراین شما نیاز دارید تا متغیری که قصد استفاده از آن را ندارید، به Ignore تغییر نقش دهید. به طور پیش فرض، پس از تبدیل، Rattle متغیر اصلی را به Ignore تغییر می دهد. در تصویر زیر، شما می توانید ببینید که متغیر اصلی Age به Ignore تغییر نقش می یابد و متغیر تبدیل یافته ی جدید به عنوان ورودی (Input) تنظیم می شود:
خروجی گرفتن از داده
پس از تبدیل داده، مطابق شکل زیر شما نیاز دارید تا از مجموعه ی داده جدید خروجی بگیرید تا در مراحل بعد، از آن به عنوان منبع داده خود استفاده کنید :

در منوی اصلی، بر روی دکمه ی Export کلیک کنید تا پنجره ی جدید باز شود. یک مسیر و نام برای فایل انتخاب کنید و بر روی دکمه ی Save کلیک کنید.
با سلام
لینک های دانلود R و Rstudio مشکل دارند و باز نمی شوند
از لینک های زیر می توان استفاده کرد
https://cran.r-project.org/bin/windows/base/
http://rprogramming.net/download-and-install-rstudio/