
آشنایی با دیتابیس تحلیلی آپاچی دروید
وبینار کارگاه عملی آپاچی دروید - موسسه نیک آموز - یلدای ۱۴۰۰

یکی از دیتابیسهایی که اخیرا و به صورت روزانه با آن سروکار دارم و به کارگیری آنرا در بسیاری از شرکتهای متوسط و بزرگ ایران برای ذخیره و پاسخگویی به حجم عظیم دادههای ورودی ، یک ضرورت میدانم ، دیتابیس تحلیلی آپاچی دروید است.

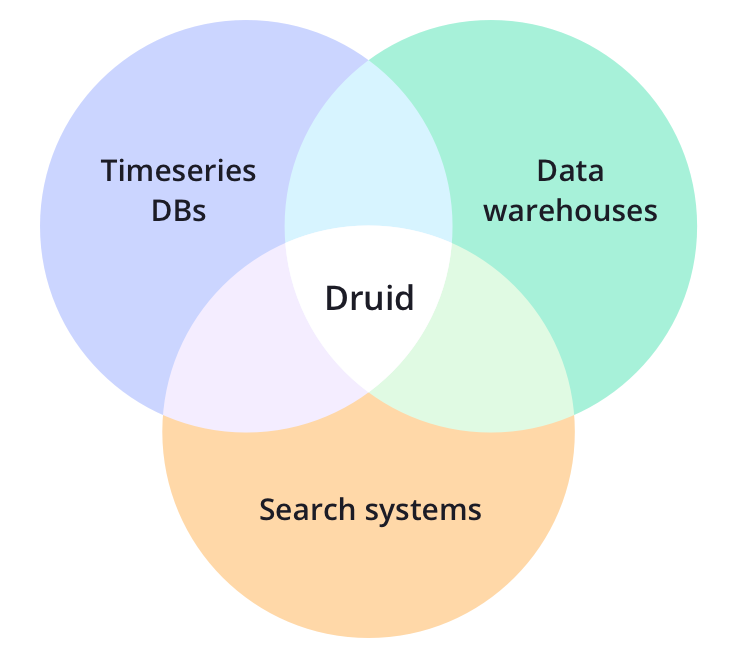
این دیتابیس که در رسته بانکهای اطلاعاتی تحلیلی به عنوان نسل جدید دیتاویرهوسها قرار میگیرد، ویژگی های کاربردی بسیار خوبی دارد. به عنوان نمونه،
- یک دیتابیس تحلیلی است و ذخیره دادهها به صورت ستونی در آن، هم حجم دادهها را بسیار کم میکند و هم سرعت پاسخگویی به کوئری های تحلیلی که معمولا ترکیبی از گروهبندی و فیلترینگ دادهها هستند را بسیار بهبود می بخشد.
- همزمان یک دیتابیس سری زمانی و یک موتور جستجوی پیشرفته هم هست.
- معماری توزیع شده بسیار پیشرفته ای دارد که مقیاس پذیری و پاسخ گویی به هر حجمی از دادهها در زمان مناسب (زیر یک ثانیه) تضمین میکند (البته نیاز به تخصیص منابع و پایش دارد )
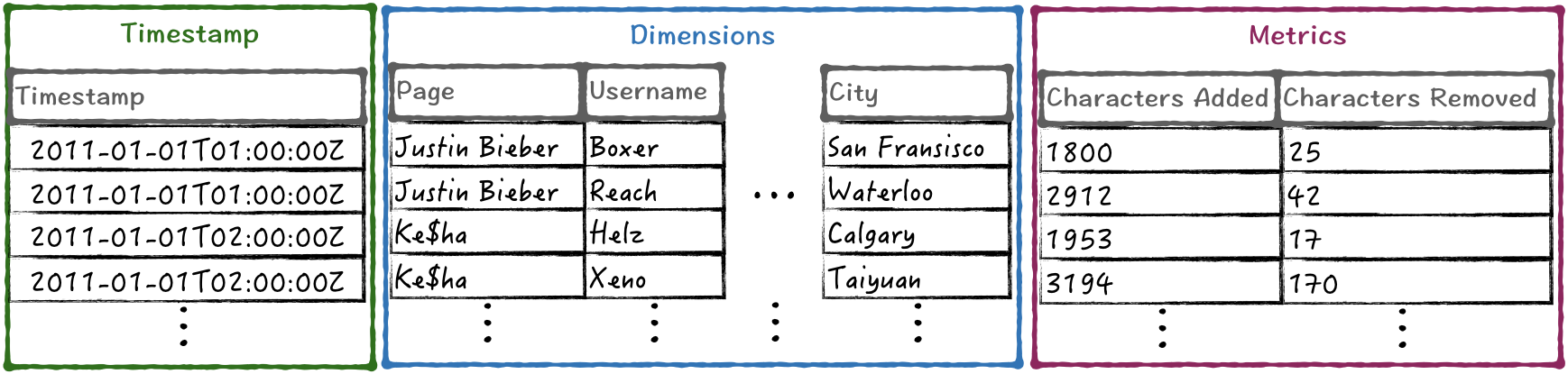
- یک دیتابیس سری زمانی است و تمامی دادهها باید حاوی مهر زمان یا تایم استمپ باشند.
- بخش دریافت داده یا اینجسشن بسیار پیشرفته ای دارد و کافی است دادههای خود را به Kafka/MinIo/HDFS/ … منتقل کنید و ادامه کار یعنی دریافت از کافکا – و سایر منابع-، فیلترینگ و پردازش اولیه داده ها و ذخیره آنها به صورت بلادرنگ را به دروید بسپارید.
- امکان تجمیع داده ها به صورت خودکار در آن فراهم شده است یعنی مثلا داده های هر پنج دقیقه را تجمیع کرده ، آمار مورد نیاز آن بازه زمانی را به صورت خلاصه برای شما محاسبه میکند.
- الگوریتم های تقریبی پیشرفته ای دارد که همزمان با تجمیع دادهها میتوانید با تقریب بسیار مناسبی، آماره هایی راجع به داده هایی که در حین تجمیع، حذف می شوند را ذخیره کنید.
- ….
به مناسبت شب یلدای ۱۴۰۰ ، به دعوت موسسه آموزشی نیک آموز وبینار یکساعته ای را راجع به این دیتابیس برگزار کرده ام که محوریت این وبینار، نصب و راه اندازی و کار عملی با آن بوده است.
بعد از حدود بیست دقیقه معرفی آن، به صورت عملی به نصب و راه اندازی آپاچی دروید پرداخته ام. در انتها هم با تولید دادههای نمونه در کافکا، فرآیند دریافت خودکار این داده ها در دروید و تجمیع آنها را به علاقه مندان به صورت عملی نشان داده ام.
اگر به این حوزه علاقه مند هستید، می توانید فیلم های آموزشی این وبینار را از آدرسهای زیر دریافت کنید و پس از مشاهده آن، با اجرای مراحل انجام شده به صورت لوکال، کار با این دیتابیس خوش آتیه را استارت بزنید.
فیلم های این وبینار از آدرس های زیر قابل دریافت است :
- بخش اول : معرفی معماری و مفاهیم پایه آپاچی دروید در دیدئو ببینید
- بخش دوم : کارگاه عملی در دیدئو ببینید
- بخش سوم : پرسش و پاسخ
مطالب بخش عملی این وبینار نیز در آدرس زیر قرار گرفته است :