
معرفی RAY : کتابخانه ای برای پردازش توزیع شده
آیا RAY میتواند به محبوبیت اسپارک در حوزه پردازش توزیع شده برسد؟
چندی پیش وقتی گزارش Oreilly راجع به دستمزدها و پرداختی های حوزه پردازش داده/هوش مصنوعی را بررسی می کردم در بخش کتابخانه های پایتون که آشنایی با آنها بیشترین درآمد را برای متخصصین این حوزه به همراه دارد، به کتابخانه Ray برخوردم که حقوق متوسط ۱۹۰ هزار دلاری برای آن، وسوسه انگیز به نظر میرسید و نشان میداد که بازار به این پروژه متن باز نیاز دارد. اما اینکه دقیقا چه مشکلی را این کتابخانه حل کرده است در نگاه نخست، به چشمم نیامد. در فهرست زیر ترتیب این مهارتها و حقوق متوسط متناظر با هریک را می توانید مشاهده کنید :
با بررسی اولیه این پروژه که کتابخانه های آن برای پایتون، جاوا و ++C در دسترس است، متوجه شدم که هدف اصلی آن، اجرای توزیع شده کدهای مرتبط با پردازش داده و بویژه انجام کارهای یادگیری ماشین بر این مبناست (اجرای توزیع شده و مقیاس پذیر مدلهای یادگیری ماشین).
با توجه به وجود چارچوب های به نسبت جاافتاده و قدیمی این حوزه مانند اسپارک و فلینک، رواج یک فریمورک جدید و آن هم در این سطح، کمی برایم تعجب آور بود. با بررسی مثالهای موجود در مستندات رسمی Ray، دلیل اصلی این محبوبیت (البته از نقطه نظر بنده) را یافتم. با توجه به اینکه در آینده ای نزدیک از این کتابخانه، در ادبیات حوزه پردازش داده زیاد خواهید شنید، تصمیم گرفتم این تجربه را با شما هم اشتراک بگذارم.
اگر با اسپارک و هدوپ آشنا باشید، میدانید که این دو فریمورک پردازش توزیع شده داده ها که اولی جزء اصلی ترین بازیگران این حوزه هم محسوب می شود، علیرغم امکانات فراوان و سرعتی که با خود به همراه می آورند، یک ضعف بزرگ دارند و آن هم این است که باید برنامه های موجود خود را با استانداردهای آنها تطبیق دهید یعنی به سبک آنها کدنویسی کنید. قدم اول هم در این راستا، این است که توسعه دهندگان شما با اسپارک (یا فلینک یا آپاچی بیم) و نحوه برنامه نویسی با آن، آشنا شوند که این موضوع، خود مانعی بزرگ برای تیم های مختلفی است که فرصت آموزش یا نیروی ماهرِ آشنا به مباحث پردازش توزیع شده داده ها را ندارند.
GitHub – ray-project/ray: An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyp…
https://github.com/ray-project/ray
فریمورک Ray این مانع را به درستی تشخیص داده است و دلیل محبوبیت و رواج آن هم به نظرم، همین نکته کلیدی است. Ray به شما اجازه میدهد همان سبک برنامه نویسی معمولی خود را ادامه دهید و فقط با اضافه کردن یک خط کد در ابتدای تعریف تابع یا کلاس (از طریق Decorator ها)و یک تغییر کوچک در هنگام فراخوانی این توابع، آنها را برای شما به صورت توزیع شده اجرا کند و نتیجه را به شما برگرداند.
به این ترتیب، نیاز به آموزش و یادگیری یک مهارت جدید یا تغییر شکل طراحی برنامه ها، از بین میرود و همه می توانند برنامه هایی بنویسند که هر تابع آن در بخشی از شبکه اجرا شود و نتیجه به برنامه فراخوانی کننده آن، از طریق چارچوب Ray ارسال شود.
خلاصه کلام اینکه چارچوب RAY به شما اجازه میدهد با انجام تغییرات کوچکی در همان برنامه های موجود، آنها را به برنامه هایی توزیع شده تبدیل کنید. این موضوع باعث میشود، به کارگیری آن در پروژه های موجود و در شرکتهای مختلف، با سرعت بیشتری نسبت به رقبا انجام شود. به قطعه کد زیر دقت کنید :
import time
def do_some_work(x):
time.sleep(1) # Replace this with work you need to do.
return x
start = time.time()
results = [do_some_work(x) for x in range(4)]
print("duration =", time.time() - start, "\nresults = ", results)خروجی قطعه کد فوق ، مشابه با این خواهد بود :
duration = 4.0149290561676025
results = [0, 1, 2, 3]حال همین کد را اگر بخواهیم با Ray اجرا کنیم، کافی است تغییرات اندک زیر را اعمال کنیم تا یک کد توزیع شده (در ادامه توضیح خواهم داد که این کد بر روی کلاستر Ray اجرا خواهد شد) داشته باشیم :
import time
import ray
ray.init(num_cpus = 4) # Specify this system has 4 CPUs.
@ray.remote
def do_some_work(x):
time.sleep(1) # Replace this is with work you need to do.
return x
start = time.time()
results = ray.get([do_some_work.remote(x) for x in range(4)])
print("duration =", time.time() - start, "\nresults = ", results)
با این تغییر و به شرط اینکه Ray را روی سیستم خود نصب کرده باشیم (در حالت لوکال)، خروجی زیر را مشاهده خواهیم کرد :
duration = 1.0064549446105957
results = [0, 1, 2, 3]مشاهده میکنیم که سرعت کار تا چهار بار بیشتر شده است و تغییراتی که در کد اصلی هم باید اعمال شود، در حد تغییری ساده در فراخوانی توابع است تا آنها را به جای فراخوانی معمولی، به صورت توزیع شده و بر روی یک کلاستر مجزا، اجرا کنیم.
نصب Ray هم در حالت لوکال و برای تست اولیه بسیار ساده و در حد نصب یک کتابخانه پایتون است. این موضوع هم به سرعت تطبیق و به کارگیری آن خواهد افزود.

علاوه بر این مزیت بزرگی که Ray با خود به همراه می آورد (سادگی استفاده)، فایده بزرگ دیگری هم در آن نهفته است . با استفاده از Ray، پردازش های سنگین و برنامه هایی که نیاز به پایش و نظارت مداوم وضعیت منابع دارند در یک کلاستر جداگانه اجرا می شوند و برنامه های معمول روزانه، تنها ترتیب اجرای این توابع را مشخص میکنند و اجرای آنها، به صورت ریموت و در کلاستر Ray انجام میشود.
اتفاقا مدتی بود که این مساله ذهنم را به خود مشغول کرده بود که ما روزانه برنامه های مختلفی را اجرا میکنیم و برای هر تسک خاص (یک میکروسرویس) یک کانتینر در کوبرنتیز بالا می آوریم و به تدریج که تعداد این کانتینرها زیاد میشود، مدیریت منابع سرور برایمان پیچیده تر می شود. بخش زیادی از کارهای روزانه ما، خواندن داده ها از کافکا، پردازش آنها و نهایتا ذخیره نتایج و یا ارسال مجدد آنها به یک تاپیک جدید در کافکاست .
به دنبال فریمورکی بودم که هم بتواند امکان اجرای این کانسیومرها (مصرف کنندگان داده های کافکا) را به صورت توزیع شده و نظارت شده برای ما فراهم کند و هم بتوانیم در صورت نیاز، تعداد آنها را به راحتی کم یا زیاد کرده، بر منابع مصرفی آنها، نظارت کنیم .
در همین راستا و با جستجوی Kafka + Ray به ریپوزیتوری زیر (و مقاله مرتبط با آن که معماری آنرا توضیح داده است ) رسیدیم که نتیجه آن، طراحی یک چارچوب داخلی برای مدیریت این بخش از خطوط پردازش داده با Ray بود که در صورت موفقیت آمیز بودن آن، استفاده از Ray در تمامی پروژه های پردازش داده داخلی ما به تدریج صورت خواهد گرفت.
GitHub – bkatwal/distributed-kafka-consumer-python: A distributed Kafka Consumer in Python using Ray
A distributed Kafka Consumer in Python using Ray. Contribute to bkatwal/distributed-kafka-consumer-python development by creating an account on GitHub.
https://github.com/bkatwal/distributed-kafka-consumer-python
داشتن داشبورد گرافیکی مدیریتی مناسب از دیگر مزایای استفاده از Ray است.
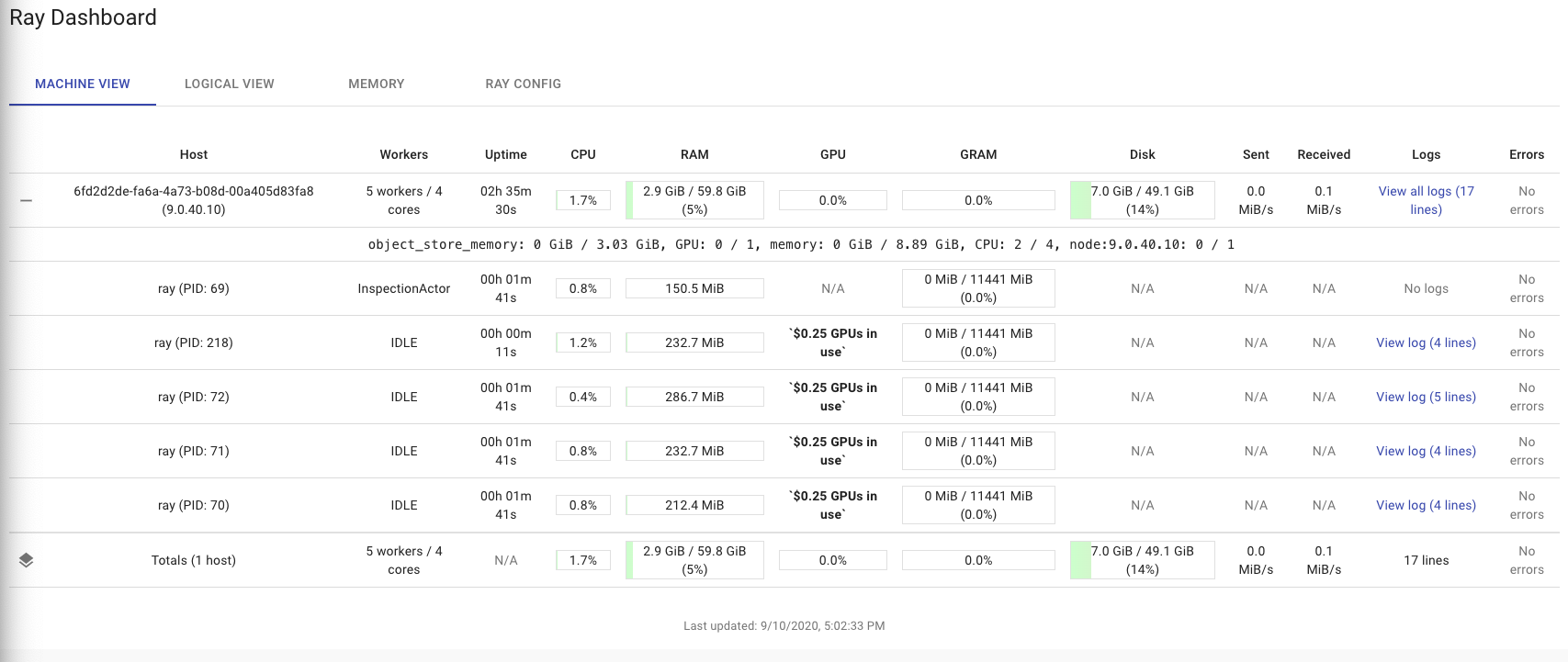
البته دقت کنید که به دلیل توزیع شدگی تسک ها در شبکه، قبل از مهاجرت به Ray مستندات آنرا به خوبی مطالعه کرده، تستهای مختلف را بر روی آن انجام دهید. بعد از آشنایی و تست اولیه Ray توصیه میکنم این مقاله را هم حتما مطالعه کنید : Programming in Ray: Tips for first-time users – RISE Lab (berkeley.edu)
البته یک نکته باریک تر از مو هم اینجا وجود دارد و آن هم این است که کدهای اسپارک هم می توانند توسط Ray اجرا شوند. این مورد زمانی که برای آموزش مدلهای داده خود از تنسورفلو یا PyTorch استفاده کرده اید، میتواند بسیار مفید باشد .
https://docs.ray.io/en/latest/data/raydp.html
ممنون جناب دکتر. بسیار سازنده و مفید بود لطفا همجنان با قدرت به کارتون ادمه بدین که بسیار ما رو مشتاق کردین